译者 | 朱先忠
图像来自文章https://arxiv.org/abs/2303.10158,由作者本人制作
人工智能在改变我们的生活、工作和与技术互动的方式方面取得了令人难以置信的进步。最近,一个取得重大进展的领域是大型语言模型(LLM)的开发,如GPT-3、ChatGPT和GPT-4。这些模型能够以令人印象深刻的准确性执行语言完成翻译、文本摘要和问答等任务。
虽然很难忽视大型语言模型不断增加的模型规模,但同样重要的是要认识到,它们的成功很大程度上归功于用于训练它们的大量高质量数据。
在本文中,我们将从以数据为中心的人工智能角度概述大型语言模型的最新进展,参考我们最近的调查论文(末尾文献1与2)中的观点以及GitHub上的相应技术资源。特别是,我们将通过以数据为中心的人工智能的视角仔细研究GPT模型,这是数据科学界日益增长的一种观点。我们将通过讨论三个以数据为中心的人工智能目标——训练数据开发、推理数据开发和数据维护,来揭示GPT模型背后以数据为核心的人工智能概念。
大型语言模型与GPT模型
LLM(大型语言模型)是一种自然语言处理模型,经过训练可以在上下文中推断单词。例如,LLM最基本的功能是在给定上下文的情况下预测丢失的令牌。为了做到这一点,LLM被训练来从海量数据中预测每个候选令牌的概率。

使用具有上下文的大型语言模型预测丢失令牌的概率的说明性示例(作者本人提供的图片)
GPT模型是指OpenAI创建的一系列大型语言模型,如GPT-1、GPT-2、GPT-3、InstructGPT和ChatGPT/GPT-4。与其他大型语言模型一样,GPT模型的架构在很大程度上基于转换器(Transformer),它使用文本和位置嵌入作为输入,并使用注意力层来建模令牌间的关系。
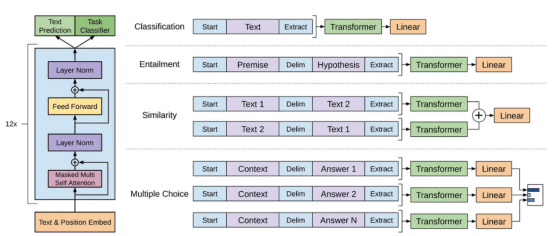
GPT-1模型体系架构示意图,本图像来自论文https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
后来的GPT模型使用了与GPT-1类似的架构,只是使用了更多的模型参数,具有更多的层、更大的上下文长度、隐藏层大小等。

GPT模型的各种模型大小比较(作者提供图片)
什么是以数据为中心的人工智能?
以数据为中心的人工智能是一种新兴的思考如何构建人工智能系统的新方式。人工智能先驱吴恩达(Andrew Ng)一直在倡导这一理念。
以数据为中心的人工智能是对用于构建人工智能系统的数据进行系统化工程的学科。
——吴恩达
过去,我们主要专注于在数据基本不变的情况下创建更好的模型(以模型为中心的人工智能)。然而,这种方法可能会在现实世界中导致问题,因为它没有考虑数据中可能出现的不同问题,例如不准确的标签、重复和偏置。因此,“过度拟合”一个数据集可能不一定会导致更好的模型行为。
相比之下,以数据为中心的人工智能专注于提高用于构建人工智能系统的数据的质量和数量。这意味着,注意力将集中在数据本身,而模型相对来说更固定。以数据为中心的方法开发人工智能系统在现实世界中具有更大的潜力,因为用于训练的数据最终决定了模型的最大能力。
值得注意的是,“以数据为中心”与“数据驱动”有根本不同,因为后者只强调使用数据来指导人工智能开发,而人工智能开发通常仍以开发模型而非工程数据为中心。
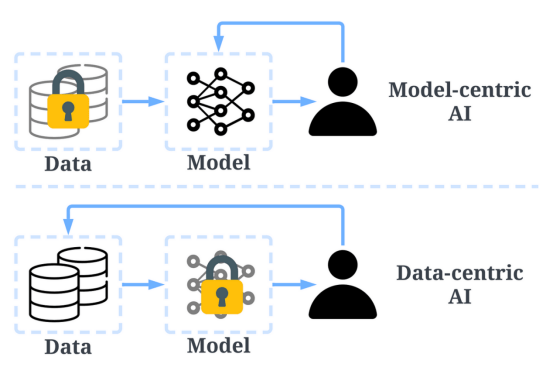
以数据为中心的人工智能与以模型为中心的AI的比较(图片来自https://arxiv.org/abs/2301.04819论文作者)
总体来看,以数据为中心的人工智能框架由三个目标组成:
训练数据开发是收集和产生丰富、高质量的数据,以支持机器学习模型的训练。
推理数据开发是为了创建新的评估集,这些评估集可以为模型提供更精细的见解,或者通过工程数据输入触发模型的特定能力。
数据维护是为了确保数据在动态环境中的质量和可靠性。数据维护至关重要,因为现实世界中的数据不是一次性创建的,而是需要持续维护的。
以数据为中心的人工智能框架(图像来自论文https://arxiv.org/abs/2303.10158的作者)
为什么以数据为中心的人工智能使GPT模型如此成功?
几个月前,人工智能界大佬Yann LeCun在其推特上表示,ChatGPT并不是什么新鲜事。事实上,在ChatGPT和GPT-4中使用的所有技术(Transformer和从人类反馈中强化学习等)都不是新技术。然而,他们确实取得了以前的模型无法取得的令人难以置信的成绩。那么,他们成功的动力是什么呢?
首先,加强训练数据开发。通过更好的数据收集、数据标记和数据准备策略,用于训练GPT模型的数据的数量和质量显著提高。
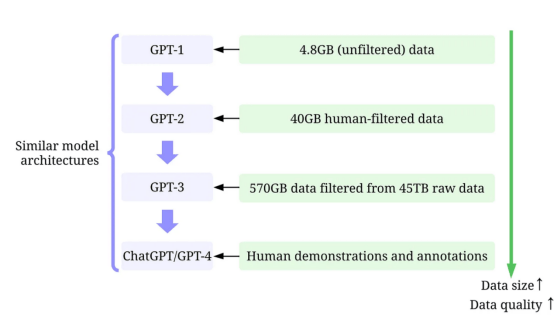
GPT-1:BooksCorpus数据集用于训练。该数据集包含4629MB的原始文本,涵盖了冒险、幻想和浪漫等一系列流派的书籍。
没有使用以数据为中心的人工智能策略。
训练结果:在该数据集上应用GPT-1可以通过微调来提高下游任务的性能。
采用了以数据为中心的人工智能策略:(1)仅使用Reddit的出站链接来控制/过滤数据,该链接至少收到3个结果;(2)使用工具Dragnet和Newspaper提取“干净”的内容;(3)采用重复数据消除和其他一些基于启发式的净化方法(论文中没有提到细节)。
训练结果:净化后得到40GB的文本。GPT-2无需微调即可实现强大的零样本结果。
使用了以数据为中心的人工智能策略:(1)训练分类器,根据每个文档与WebText的相似性筛选出低质量文档,WebText是高质量文档的代理。(2)使用Spark的MinHashLSH对文档进行模糊的重复数据消除。(3)使用WebText、图书语料库和维基百科来增强数据。
训练结果:从45TB的明文中过滤得到570GB的文本(在本次质量过滤中仅选择1.27%的数据)。在零样本设置中,GPT-3显著优于GPT-2。
使用了以数据为中心的人工智能策略:(1)使用人工提供的提示答案,通过监督训练调整模型。(2)收集比较数据以训练奖励模型,然后使用该奖励模型通过来自人类反馈的强化学习(RLHF)来调整GPT-3。
训练结果:InstructGPT显示出更好的真实性和更少的偏差,即更好的一致性。
GPT-2:使用WebText来进行训练。这是OpenAI中的一个内部数据集,通过从Reddit中抓取出站链接创建。
GPT-3:GPT-3的训练主要基于Common Crawl工具。
InstructGPT:让人类评估调整GPT-3的答案,使其能够更好地符合人类的期望。他们为注释器设计了测试,只有那些能够通过测试的人才有资格进行注释。此外,他们甚至还设计了一项调查,以确保注释者喜欢注释过程。
ChatGPT/GPT-4:OpenAI未披露详细信息。但众所周知,ChatGPT/GPT-4在很大程度上遵循了以前GPT模型的设计,它们仍然使用RLHF来调整模型(可能有更多、更高质量的数据/标签)。人们普遍认为,随着模型权重的增加,GPT-4使用了更大的数据集。
其次,进行推理数据开发。由于最近的GPT模型已经足够强大,我们可以通过在固定模型的情况下调整提示(或调整推理数据)来实现各种目标。例如,我们可以通过提供摘要的文本以及“summarize it”或“TL;DR”等指令来进行文本摘要,以指导推理过程。

提示符微调,图片由作者提供
设计正确的推理提示是一项具有挑战性的任务。它在很大程度上依赖于启发式技术。一项很好的调查总结了目前为止人们使用的不同的提示方法。有时,即使在语义上相似的提示也可能具有非常不同的输出。在这种情况下,可能需要基于软提示的校准来减少差异。
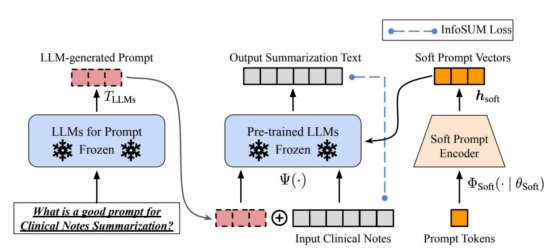
基于软提示符的校准。本图像来自于论文https://arxiv.org/abs/2303.13035v1,经原作者许可
大型语言模型推理数据开发的研究仍处于早期阶段。在不久的将来,已经在其他任务中使用的更多推理数据开发技术可能会应用于大型语言模型领域。
就数据维护方面来说,ChatGPT/GPT-4作为一种商业产品,并不仅仅是训练一次成功的,而是需要不断更新和维护。显然,我们不知道数据维护是如何在OpenAI之外执行的。因此,我们讨论了一些以数据为中心的通用人工智能策略,这些策略很可能已用于或将用于GPT模型:
持续数据收集:当我们使用ChatGPT/GPT-4时,我们的提示/反馈反过来可以被OpenAI用来进一步推进他们的模型。可能已经设计和实施了质量指标和保证策略,以便在此过程中收集高质量的数据。
数据理解工具:有可能已经开发出各种工具来可视化和理解用户数据,促进更好地理解用户的需求,并指导未来的改进方向。
高效的数据处理:随着ChatGPT/GPT-4用户数量的快速增长,需要一个高效的数据管理系统来实现快速的数据采集。
ChatGPT/GPT-4系统能够通过如图所示的“拇指向上”和“拇指向下”两个图标按钮收集用户反馈,以进一步促进他们的系统发展。此处屏幕截图来自于https://chat.openai.com/chat。
数据科学界能从这一波大型语言模型中学到什么?
大型语言模型的成功彻底改变了人工智能。展望未来,大型语言模型可能会进一步彻底改变数据科学的生命周期。为此,我们做出两个预测:
以数据为中心的人工智能变得更加重要。经过多年的研究,模型设计已经非常成熟,尤其是在Transformer之后。工程数据成为未来改进人工智能系统的关键(或可能是唯一)方法。此外,当模型变得足够强大时,我们不需要在日常工作中训练模型。相反,我们只需要设计适当的推理数据(即时工程)来从模型中探索知识。因此,以数据为中心的人工智能的研发将推动未来的进步。
大型语言模型将实现更好的以数据为中心的人工智能解决方案。在大型语言模型的帮助下,许多乏味的数据科学工作可以更有效地进行。例如,ChaGPT/GPT-4已经可以编写可操作的代码来处理和清理数据。此外,大型语言模型甚至可以用于创建用于训练的数据。例如,最近的工作表明,使用大型语言模型生成合成数据可以提高临床文本挖掘中的模型性能。
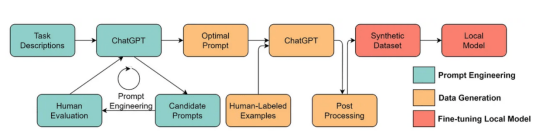
使用大型语言模型生成合成数据以训练模型,此处图像来自论文https://arxiv.org/abs/2303.04360,经原作者许可
参考资料
我希望这篇文章能在你自己的工作中给你带来启发。您可以在以下论文中了解更多关于以数据为中心的人工智能框架及其如何为大型语言模型带来好处:
[1]以数据为中心的人工智能综述。
[2]以数据为中心的人工智能前景与挑战。
注意,我们还维护了一个GitHub代码仓库,它将定期更新相关的以数据为中心的人工智能资源。
在以后的文章中,我将深入研究以数据为中心的人工智能的三个目标(训练数据开发、推理数据开发和数据维护),并介绍具有代表性的方法。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:What Are the Data-Centric AI Concepts behind GPT Models?,作者:Henry Lai
文章内容仅供阅读,不构成投资建议,请谨慎对待。投资者据此操作,风险自担。

奥维云网(AVC)推总数据显示,2024年1-9月明火炊具线上零售额94.2亿元,同比增加3.1%,其中抖音渠道表现优异,同比有14%的涨幅,传统电商略有下滑,同比降低2.3%。

“以前都要去窗口办,一套流程下来都要半个月了,现在方便多了!”打开“重庆公积金”微信小程序,按照提示流程提交相关材料,仅几秒钟,重庆市民曾某的账户就打进了21600元。

华硕ProArt创艺27 Pro PA279CRV显示器,凭借其优秀的性能配置和精准的色彩呈现能力,为您的创作工作带来实质性的帮助,双十一期间低至2799元,性价比很高,简直是创作者们的首选。


