��������ͨ���Դ�ģ��ѵ����Ӧ�����������������ó���ģ��ѵ���ǵ��͵ij���Ӧ�ã��Ҵ�ģ��ѵ����Ҫ���ߣ����������������ܺ��Լ۱�;�������г���Ϊ��˳��㡢ͨ�ó��㡢���ܳ����ҵ�������࣬�����������г����ص��Լ���Ӧ�Ĺ�����Ʒƽ̨�������˲��пƼ���Ӧ�����г��IJ�Ʒ����;�����˽�����ȫ������ܼ����г����й������ܼ����г��ķ�չ���ơ�
������ģ��ѵ�������ص�
��������ChatGPT�ı���һʱ���ģ����ӿ�ֳ��ٶȵ����ġ������ͨ�塢��Ѷ�Ļ�Ԫ���ֽڵ���ȸ����Ϊ���̹š��������Եȴ�ģ�ͣ��ͳ�����˾�����뵽�ⳡ�����С���ģ��������Ϊ�ⳡ�����Ľ��㡣
������ģ��ѵ���ǵ��͵ij���Ӧ��
������ģ��ѵ���ļ�����Ҫ�����¼����ص㡣
����1.���ݹ�ģ�Ӵ�ģ��ѵ����Ҫ���������ݽ���ѧϰ���Ż�����ȷ��ģ�;��й㷺��֪ʶ�ͽ�ǿ�ķ�����������Щ����ͨ����Դ�����硢���ݿ⡢��ѧ�о����������ģ�ɴ�����������ʮ�ڸ�������
����2.������Դ����ߣ���ģ��ѵ���Լ�����Դ������dz��ߣ�ͨ����Ҫ�����ܵļ�������Կ���Ⱥ������������⣬����ģ��ģ������ѵ��ʱ��Ҳ���������ӣ���Լ�����Դ������������˸��ߵ�Ҫ��
����3.���м��㣺Ϊ�����ѵ���ٶȣ���ģ��ѵ��ͨ�����ò��м��㼼���������ݲ��к�ģ�Ͳ��С�ͨ�����������������������ڵ���豸�����Դ�����ѵ��Ч�ʡ�
����4.�ֲ�ʽ���㣺��ģ��ѵ�������÷ֲ�ʽ���㼼������ѵ������ֲ����������ڵ��Ͻ���Эͬ����������Գ�����������и����ڵ�ļ����������������ѵ�����ܡ�
����5.�칹���㣺��ģ��ѵ���г����漰�칹���㣬�����ò�ͬ���͵ļ�����Դ(�������Э��������GPU��TPU��)Эͬ��������������ʹ��ѵ��ϵͳ�ܹ���Բ�ͬ���������Ż���Դ���䣬�������ѵ�����ܡ�
����6.�Ż��㷨��Ϊ�����ģ�͵�ѵ��Ч������ģ��ѵ����ͨ�����ø����Ż��㷨����Щ�㷨���Լ���ģ��ѵ�����̣����ģ�������ٶȺ����ܡ�
������������(supercomputing)�Ǹ����ܼ�������Ķ�����̬���߱������ص㡣
����1.���м��㣺����Ӧ�ò��ò��м��㼼���������ģ�ļ�������ֽ�ɶ��С�����ڶ������������������Ͻ��м��㡣��������˼���Ч�ʣ�ʹ��ԭ����Ҫ��ʱ����ɵ���������ڽ϶̵�ʱ������ɡ�
����2.�ֲ�ʽ���㣺����Ӧ��ͨ���ֲ�ʽ���㼼�������������������ڶ������ڵ����Эͬ���������ּ��㷽ʽ��������������и����ڵ�ļ������������������������ܡ�
����3.�߶ȼ��ɣ�����Ӧ��ͨ��������ǧ��������̨��������洢�豸�������豸���γ�һ���߶ȼ��ɵļ���ϵͳ������ϵͳ����ǿ��ļ��������ͼ��ߵ���Դ�����ʣ��������㲻ͬ�����Ӧ�ó����ļ�������
����4.������չ������Ӧ�þ߱�������չ���������Ը��ݼ���������������Դ״����̬��������ڵ���������ʹ����ϵͳ�ܹ��ڲ�ͬ�����±��ֽϸߵ���Դ�����ʺͼ������ܡ�
����5.�칹���㣺����Ӧ�ò����칹���㼼�������ø����ܴ�������GPU���ֳ��ɱ��������(FPGA)�Ȳ�ͬ���͵ļ�����Դ����Эͬ��������ʹ����ϵͳ�ܹ���Բ�ͬ���������Ż���Դ���䣬�������������ܡ�
����6.���ؾ��⣺����Ӧ��ͨ�����ؾ��⼼����ȷ��Ϊ��������ڵ�����������������������ά��ϵͳ�ȶ�����������������ٶȺ�ȷ�ԡ�
�������пƼ�����Ӧ���������������ۣ������з���Ӧ�����������ɼ���������������������Բɼ�����Ӧ�������й����е�CPU�����ʡ�CPU�ܹ����ݡ�GPU�����ʡ�GPU�ܹ����ݡ��Դ������ʡ��ڴ������ʡ����̶�д���ʡ������շ����ʵ����ݣ��൱��ΪӦ�������й�������“CT”��顣ͼ1չʾ��ͨ��Ӧ�����������ɼ�����������ɼ���1300�ڲ�����ģ��ѵ����Ӧ������������ͼ���ϰ벿���Ǵ�ģ�����е����������������°벿���Ǵ�ģ�����е�ʱ��ͼ��ͼ2��1300�ڲ�����ģ��ѵ����Ӧ�������������ڵ�Ŵ�ͼ����ͼ1��ͼ2���Կ������ô�ģ��ѵ���������Ƕ�ڵ㲢��Эͬ�������ڵ������Դ�����ʸߣ��ڵ��ͨ��Ƶ���ܼ���ͨ�����Ϸ��������Եó���ģ��ѵ�����ڵ��͵ij���ܹ�Ӧ�á���ģ��ѵ����������Ҫ�ﵽ“����”�����������������ܡ����Լ۱ȡ�
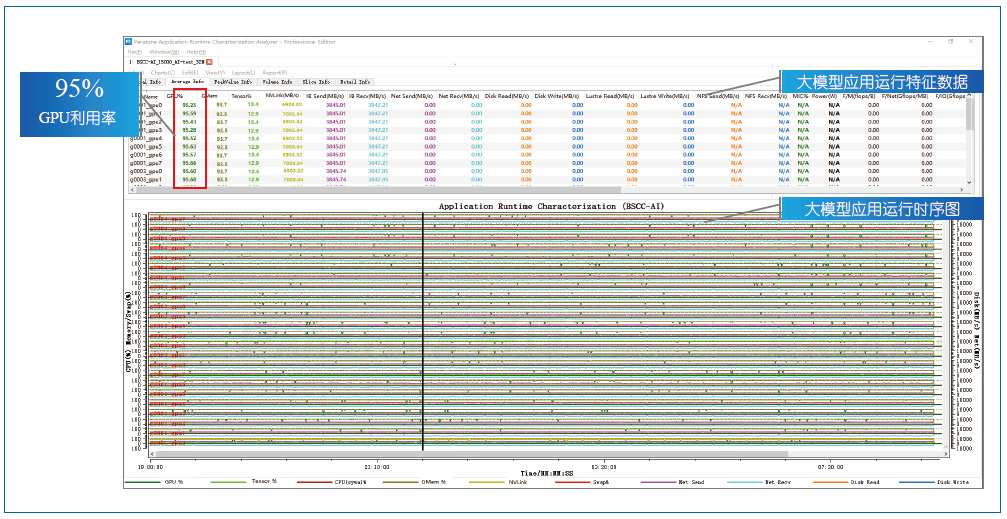
����ͼ1 1300�ڴ�ģ��ѵ��Ӧ����������ͼ

����ͼ2 1300�ڴ�ģ��ѵ��Ӧ�������������ڵ�Ŵ�ͼ
������ģ����Ҫ������
���������������ϴ�ģ��ѵ������ȷ���ȶ������жϵصõ������ͼ3չʾ��������ѵ��GLM-1300�ڲ�����ģ�͵Ĺ��̹��̡���ģ����ʱ8�������ѵ����ƽ̨�ĵ����������˽�6���£���ʽѵ����ʼ��������ƽ̨Ӳ�����ϴ������ȶ������⣬�������ü���(checkpoint)��ÿ�ι����Ի����һ����ʱ��;�����ʧ��������ѵ��ƽ̨�Ը�Ч��ɴ�ģ��ѵ��������Ҫ��
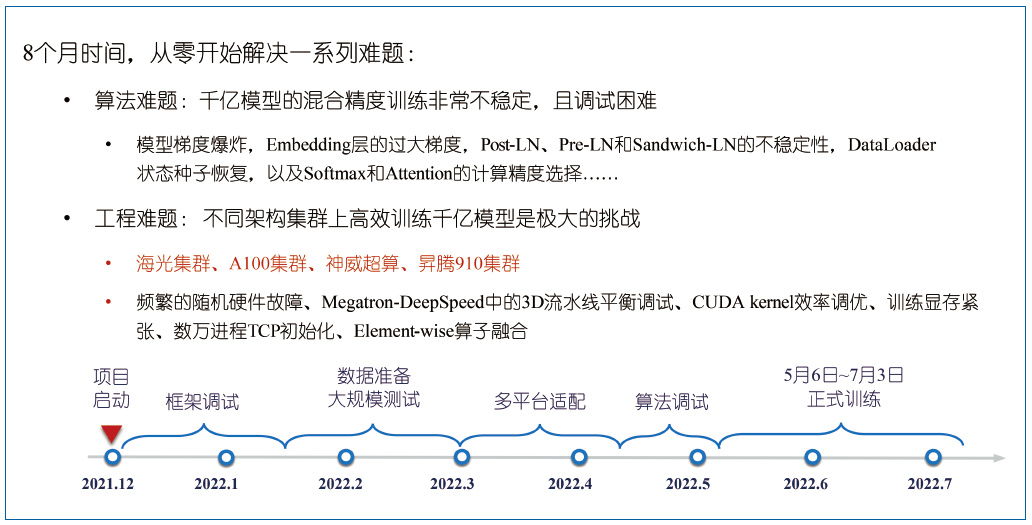
����ͼ3 GLM-1300�ڴ�ģ��ѵ������
������ģ����Ҫ������
������������ָ�������ɴ�ģ��ѵ�����㣬����ץס��չ��ʱ�䴰�ڣ����ܽ�ʡ���ѵ���ɱ���Ҫʵ�ָ����ܣ���Ҫ�ڲ�ͬ��ͨ�������ֶ��������ܣ�����Ӳ��ѡ�ͽ�ѡ�����ʺϴ�ģ��ѵ����Ӳ���ܹ�ƽ̨����ѵ����ѡ����ʵ����ӿ�Ͳ��з����ȡ�
������ģ��ѵ����Ҫ���Լ۱�
������ģ��ѵ��“��Ǯ”�ǹ��ϵģ������dz�����˾���Ǵ�ͳ���߰���Ͷ�붼��������ѹ����ͼ4չʾ��OpenAI��GPT-3��DeepMind��Gopher������MT-NLG���ȸ��PaLM��ѵ�����ݣ���������1750�ڵ�5400�ڲ��ȣ�ѵ���������������Ԫ������ǧ����Ԫ�����ڵ����δ����������ݣ����ù���Ҳ����ǧ��Ԫ������Ԫ����ҡ����ʹ�ģ��ѵ���ķ��ó�ΪAIGC��ҵ����Ҫ��ע�㣬�����dz�����ҵ�ܷ�����Ĺؼ���

����ͼ4 ��ģ��ѵ������֧��
�����������������ܡ����Լ۱ȵij���ܹ�GPU������Ⱥ��Ϊ��ģ�;����ĸ��衣
��������������״
����������г����Է�Ϊ���ࣺ��˳��㡢ͨ�ó��㡢���ܳ����ҵ���㡣
������˳���
������˳�������������ϵ�Ӧ�ã����ģ���������ܣ���Ҫ�û�Ϊ�߶˳���Ĵ�ҵ��Ա�����������Ϳ��е�λ�����Ҽ��û�����ҵ�����о��������Գ���Ӳ��ϵͳҪ��dz��ߡ������Ʒ��ν��֮������Ҫ����㡢�ô桢ͨ�š�I/O���dz����ڣ�������Ƹ߶�ƽ��ĸ߶˳������������Ҫ���Ҽ�������Ͷ�룬��Ҫ����Լ۱ȣ�һ���ɹ��ҳ�����������ʵ�ֲ������������
����ͨ�ó���
����ͨ�ó�������������µ�Ӧ�ã����������ǧ�����µ�Ӧ�ã���Ҫ���ʷ���ע�Լ۱ȣ��������㺣��������Դ�û����ճ�����ǰ�������������С����ϵͳΪ����
�������������Ǻ����û�������࣬��Ҫ����Ӧ������������������Բ�ͬ����Ӧ�ã���ȡ��̬����������ʽ��������Լ۱ȳ�����������Դ��ͨ�����ó������ʽ�������û����Խ��н��ѳ�����Ŀǰ�Գ����Ƽ�������ģʽ��������г�����
�������ܳ���
�������ܳ�����GPU����Ϊ����Ӧ�ù�ģ�ӵ������������������ܼ�������Ͷ�ʴ��Խ����٣���Ҫ����������������Դ����Ҫ���ʷ���ע�Լ۱ȡ���ģ�����������Ǵ�����ʹ�����
������������IJ�Ʒ��̬������ģʽ�������ģ��ѵ������ij�������ģʽ�ͽ��������������Ƽ���ģʽ����Ҫ����Ӧ�������������������ö�̬����������ʽ�����Լ۱���ߵ�����������Դ�������û����Խ��н��ѳ��������ó������Ŀǰ��Ҫ�����������������������
����ͼ5չʾ�˶�AIѵ�����������ƺ�δ���г���Ԥ������ͼ��������ݿ��Կ���������BERT��GPT-2��GPT-3��PaLM�ȴ�ģ�͵ı�����ѵ����������ָ����������2015~2020�꣬ѵ��������������6����������ͼ5�Ҳ��ǹ������ݹ�˾IDC������Ԥ�⣬2026�������������ģ����1271�����ڴ�(EFLOPS)��Ԥ��δ��5���й�����������ģ���긴�������ʽ���52.3%��

����ͼ5 AIѵ�������������ƺ�δ���г�Ԥ��
����ҵ����
����ҵ�����Ӧ�ù�ģͨ��Ϊ���˵���ǧ�ˣ���ҵ��ֱ�ӹ�������ע�������������ܺ��Լ۱ȡ���ҵ������˵������ֻ��ҵ���е�һ�����ڣ���Ҫʵ������ҵ�����ƣ���֤ҵ�����е��ȶ��ԺͿɿ��ԡ�
����ҵ����������ҵ��������ҵҵ�������������������ҵ�����̣���֤�û�ҵ������ڶ���ʵ�ָ������������ܡ����Լ۱ȡ�ͨ���ɹ�����/�����ƻ�רҵ��������������������
�������ͻ�������ơ�������Ʒ
����ʵ���ϣ��û������IJ�Ʒ��ij�����幦�ܣ�����ע���յ����档�û���ע����ܽ�Ϊ�������棺��һ����ƷҪ�и������������������������˳����ɼ���;�ڶ�����ƷҪ�и����ܣ��ܸ���Ч����ɼ�������;��������ƷҪ�и��Լ۱ȣ����ڸ�Ч��ɼ��������ͬʱ�����ĸ��͵ijɱ�����֮��Ҫ������Ե��ṩ��ͬ�IJ�Ʒ��̬�Ը��õ������û�����
�������в�Ʒ����
����Ϊ���㲻ͬ�����ϸ�������пƼ�����˲�ͬ�IJ�Ʒ���������г����ơ����������ơ�������ҵ�Ƶȡ�
�������г�����������ͨ�ó����г������IJ�Ʒƽ̨�������˶������ݹ������ߡ���¼�������ߡ����ӻ������Լ�����������(SaaS)���ɵȣ�������С�С�û�����Ƭ������
�����������������������ܳ����г������IJ�Ʒƽ̨���ṩ���㼯Ⱥ��������������̬���ֱ������ģ�ʹ��ģѵ������С��ģѵ������������������ƽ̨������(PaaS)���ṩPyTorch��TensorFlow�ȳ��ÿ�ܣ��Լ����õĶ�����Դ���ݼ������������Ƽܹ���ͼ6��ʾ��

����ͼ6 ���������Ƽܹ�
����������ҵ�ƻ��ڳ����ƻ�����ʩ���ṩ��ҵ��“ר����”“�����”�ȶ��Ʒ������̬�Ķ��ƻ��Ʒ���ƽ̨����ҵ�Ʋ����ɱ����û�ҵ�����̿��١���Ч����̬ʵ�֣��������㳬��ҵ��ϵͳ��SaaS����˽�в��������ɿء���ȫ�ȶ��ĸ��Ի�����
������������������Դ�غͼ�����Ӫ�������ƣ�������ҵ�ƿ�Ϊ�������졢�������������ҩ�з���оƬ���졢ʯ�Ϳ�̽����ҵ�ṩ��������ݸ�Ч����ȫ�ɿ��ĸ����ܼ���ҵ��֧�֡�
���������������ģʽ
�������пƼ����������������ģʽ����ļ����û����������Դ��ͼ7Ϊ���г�����ҵ��ܹ�ͼ���üܹ���Ϊ���㣺�ײ�����Դ�㣬���ǹ��Ҹ��������ģ����ط���������ij��㡢�������ģ��������Ƴ��̵�;�м�����ɲ�Ʒ����(Product Engineering��PE)��ϵͳ����(System Engineering��SE)��վ��ɿ��Թ���(Site Reliability Engineering��SRE)�����ݹ���(Data Engineering��DE)���Ŷӹ�����ȫ������߳����Ʒ���ƽ̨���ṩ���ݴ�����ǰ����������ģ�⡢��ֵ��⡢�������û�ȫҵ��������;�ϲ�Ϊ��������ѧ�����졢��ѧ����ҵ���졢������������ѧ���˹����ܵȸ�����ĺ������������ڳ����Ƶ�ҵ��ܹ��������Ĵ�ҵ�����ͣ���һ���������ҵ�ĺ������������ṩ�����������;�ڶ����������û���ҵ�����Ƴ������������ṩ����PaaSƽ̨��Ϊҵ���ṩ��������API�ͷ����ϵ�;�������������Ӧ�������������ṩPaaSƽ̨����ͬ����SaaS��ģʽ����������Ӧ���������ٷ�չ�����“������”����;���������ϸ����㽨�跽������������Ӫ������
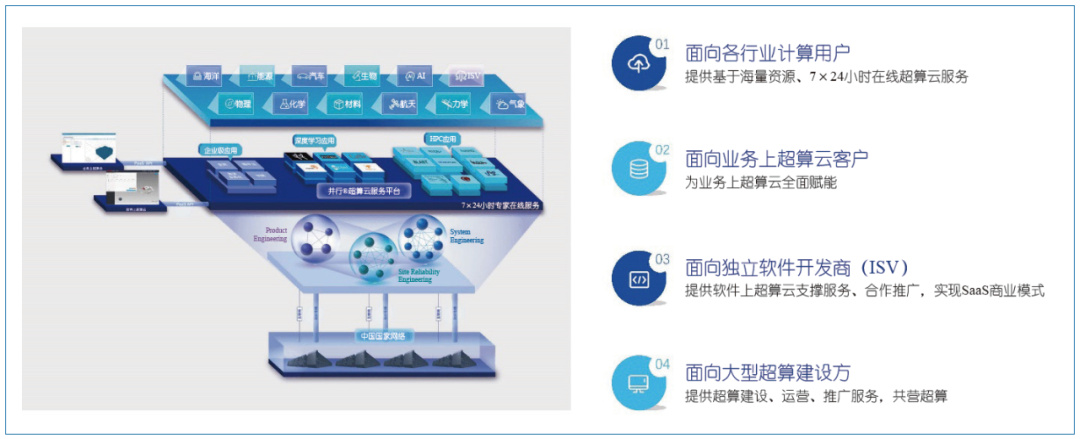
����ͼ7 ������ҵ��ܹ�
�������������
����Ŀǰ��������Դ�ٻ���ţ��������β�룬�����������Ϊ��֤��Դ�������������Ч����Ĺؼ�Ҫ�ء����пƼ��ƶ���5������Ľ�������ֱ��Ӧ������1����2����3����������4����5�������磬��Ⱥ��̬����5�������Ҫ������GPU��ԴΪijһ�߶��ͺ�(������)���ﵽ1000�Ź�ģ���ϣ�֧�ֶ��ƻ����ݰ�ȫ������֧��ר��������֧�ֱ�����ҵ���ȣ�֧�����ܻ���ά��Ӧ�ó����̽ӿ�(API)�ȡ�
��������Ӧ�����������ľ�ȷѡ��
�������г�����ƽ̨�����е�Ӧ����ǧ���֣�������Դ�������а����֡�ij��Ӧ����Դ�������а����֡�ij��Ӧ�������ں���ƽ̨�������š��Լ۱����?���ʵ��Ӧ����ƽ̨�Ŀ��ٸ�Чƥ��?�����Щ���⣬���пƼ��Ƴ�����Ӧ�����������ľ�ѡ��ParaSelect�����û�������Ӧ�ú͵��͵Ĺ�������(workload)�ύ�����пƼ��ı�����ƽ̨�����ڲ������ݺͲ���Ӧ�����������⣬��ƽ̨�ɿ��ٸ������ܲ��Ա��棬��֪�û��ʺϸ�Ӧ�����е�Ӳ��ƽ̨�Լ�����Լ۱ȵ�ƽ̨��
����ͼ8ΪLlama2-7Bģ����A100 40GB PCIeƽ̨��ͬ������ģ�ϵ�Ԥ����ʵ��ֵ����ͼ�п��Կ���Ԥ����ʵ��������Ͻ�Ϊ�ӽ������Եó�Llama2-7B��A100 40GB PCIeƽ̨�нϺõ�����Ч�ʡ�

����ͼ8 ����Ӧ�����������ľ�ѡ��ParaSelect����
�����Ż�����
�����ڲ��г�����ƽ̨���еĶ���������ij���Ӧ�þ��õ�����Ż���ͼ9չʾ����ij1300�ڲ�����Ԥѵ��Ӧ��������������ͼ�п��Կ�������������Ч�ʵ�����Ҫ����GPU����������75%�������ڼ��㷽������Ż��ռ䣬ͨ������������Ż�Ӧ�ó�������ƣ���GPU������������95%����(��ͼ10)���������ܵõ����������

����ͼ9 1300��Ԥѵ��Ӧ����������(�Ż�ǰ)


����ͼ10 1300��Ԥѵ��Ӧ����������(�Ż���)
����ȫ������ܼ����г����ֳ����չ��̬�ƣ�ͼ11��IDC�Ȼ���������ȫ������ܼ����г��Լ��й������ܼ����г��ķ�չ���ƣ�ѧ�����������л��������������ں������Ǹ������г�������������ռ�ݰ�ڽ�ɽ�������Ʒ������ʲ����������й�����ҵ��У�ȸ����ܼ����г�������ĸ��������ʽ�����50%���й������ܼ����г����������չ��
����ͼ11 ȫ������ܼ����г��Լ��й������ܼ����г��ķ�չ����
����(���ĸ���CNCC2023����������������)
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
