每个人想要的大模型,是真·智能的那种......
这不,谷歌团队就做出来了一个强大的「读屏」AI。
研究人员将其称为ScreenAI,是一种理解用户界面和信息图表的全新视觉语言模型。

论文地址:https://arxiv.org/pdf/2402.04615.pdf
ScreenAI的核心是一种新的屏幕截图文本表示方法,可以识别UI元素的类型和位置。
值得一提的是,研究人员使用谷歌语言模型PaLM 2-S生成了合成训练数据,以训练模型回答关屏幕信息、屏幕导航和屏幕内容摘要的问题。
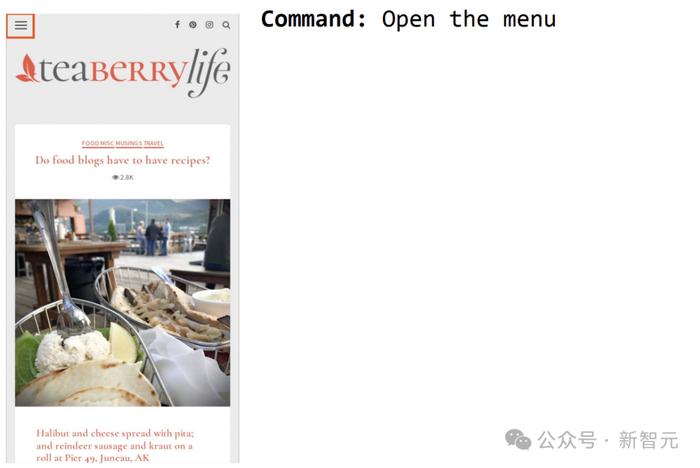
举个栗子,比如打开一音乐APP页面,可以询问「有几首歌时长少于30秒」?
ScreenAI便给出了简单的答案:1。

再比如命令ScreenAI打开菜单,就可以选中。
架构灵感来源——PaLI
图1中展示了ScreenAI模型架构。研究人员受到了PaLI系列模型架构(由一个多模态编码器块组成)的启发。
该编码器块包含一个类似ViT的视觉编码器和一个消费图像(consuming image)和文本输入的mT5语言编码器,后接一个自回归解码器。
输入图像通过视觉编码器转化为一系列嵌入,这些嵌入与输入文本嵌入结合,一起输入mT5语言编码器。
编码器的输出传递给解码器,生成文本输出。
这种泛化公式能够使用相同的模型架构,解决各种视觉和多模态任务。这些任务可以重新表述为文本+图像(输入)到文本(输出)的问题。
与文本输入相比,图像嵌入构成了多模态编码器输入长度的重要部分。
简而言之,该模型采用图像编码器和语言编码器提取图像与文本特征,将二者融合后输入解码器生成文本。
这种构建方式可以广泛适用于图像理解等多模态任务。

另外,研究人员还进一步扩展了PaLI的编码器-解码器架构,以接受各种图像分块模式。
原始的PaLI架构只接受固定网格模式的图像块来处理输入图像。然而,研究人员在屏幕相关领域遇到的数据,跨越了各种各样的分辨率和宽高比。
为了使单个模型能够适应所有屏幕形状,有必要使用一种适用于各种形状图像的分块策略。
为此,谷歌团队借鉴了Pix2Struct中引入的一种技术,允许根据输入图像形状和预定义的最大块数,生成任意网格形状的图像块,如图1所示。
这样能够适应各种格式和宽高比的输入图像,而无需对图像进行填充或拉伸以固定其形状,从而使模型更通用,能够同时处理移动设备(即纵向)和台式机(即横向)的图像格式。
模型配置
研究人员训练了3种不同大小的模型,包含670M、2B和5B参数。
对于670M和2B参数模型,研究人员从视觉编码器和编码器-解码器语言模型的预训练单峰检查点开始。
对于5B参数模型,从 PaLI-3的多模态预训练检查点开始,其中ViT与基于UL2的编码器-解码器语言模型一起训练。
表1中可以看到视觉和语言模型之间的参数分布情况。

自动数据生成
研究人员称,模型开发的预训练阶段很大程度上,取决于对庞大且多样化的数据集的访问。
然而手动标注广泛的数据集是不切实际的,因此谷歌团队的策略是——自动数据生成。
这种方法利用专门的小模型,每个模型都擅长高效且高精度地生成和标记数据。
与手动标注相比,这种自动化方法不仅高效且可扩展,而且还确保了一定程度的数据多样性和复杂性。
第一步是让模型全面了解文本元素、各种屏幕组件及其整体结构和层次结构。这种基础理解对于模型准确解释各种用户界面并与之交互的能力至关重要。
这里,研究人员通过爬虫应用程序和网页,从各种设备(包括台式机、移动设备和平板电脑)收集了大量屏幕截图。
然后,这些屏幕截图会使用详细的标签进行标注,这些标签描述了UI 元素、它们的空间关系以及其他描述性信息。
此外,为了给预训练数据注入更大的多样性,研究人员还利用语言模型的能力,特别是PaLM 2-S分两个阶段生成QA对。
首先生成之前描述的屏幕模式。随后,作者设计一个包含屏幕模式的提示,指导语言模型生成合成数据。
经过几次迭代后,可以确定一个有效生成所需任务的提示,如附录C所示。
为了评估这些生成响应的质量,研究人员对数据的一个子集进行了人工验证,以确保达到预定的质量要求。
该方法在图2中进行了描述,大大提升预训练数据集的深度与广度。
通过利用这些模型的自然语言处理能力,结合结构化的屏幕模式,便可以模拟各种用户交互和情景。

两组不同任务
接下来,研究人员为模型定义了两组不同的任务:一组初始的预训练任务和一组后续的微调任务。
这两组的区别主要在于两个方面:
- 真实数据的来源:对于微调任务,标记由人类评估者提供或验证。对于预训练任务,标记是使用自监督学习方法推断的或使用其他模型生成的。
- 数据集的大小:通常预训练任务包含大量的样本,因此,这些任务用于通过更扩展的一系列步骤来训练模型。
表2显示所有预训练任务的摘要。
在混合数据中,数据集按其大小按比例加权,每个任务允许的最大权重。

将多模态源纳入多任务训练中,从语言处理到视觉理解和网页内容分析,使模型能够有效处理不同的场景,并增强其整体多功能性和性能。

研究人员在微调期间使用各种任务和基准来估计模型的质量。表3总结了这些基准,包括现有的主要屏幕、信息图表和文档理解基准。

实验结果
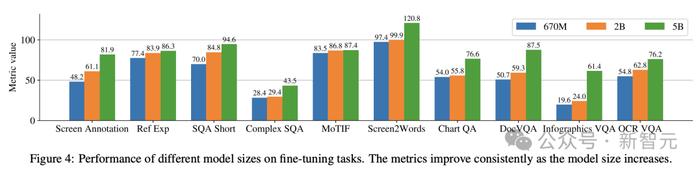
图4显示了ScreenAI模型的性能,并将其与各种与屏幕和信息图形相关的任务上的最新SOT结果进行了比较。
可以看到,ScreenAI在不同任务上取得的领先性能。
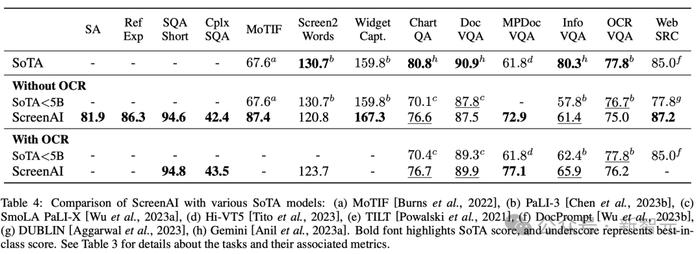
在表4中,研究人员呈现了使用OCR数据的单任务微调结果。
对于QA任务,添加OCR可以提高性能(例如Complex ScreenQA、MPDocVQA和InfoVQA上高达4.5%)。
然而,使用OCR会稍微增加输入长度,从而导致整体训练速度更慢。它还需要在推理时获取OCR结果。
另外,研究人员使用以下模型规模进行了单任务实验:6.7亿参数、20亿参数和50亿参数。
在图4中可以观察到,对于所有任务,增加模型规模都可以改进性能,在最大规模下的改进还没有饱和。
对于需要更复杂的视觉文本和算术推理的任务(例如InfoVQA、ChartQA和Complex ScreenQA),20亿参数模型和50亿参数模型之间的改进明显大于6.7亿参数模型和20亿参数模型。
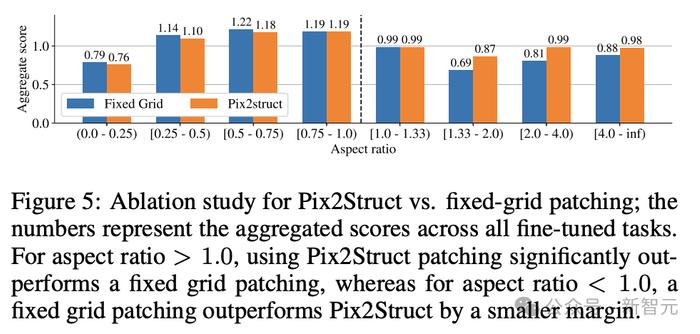
最后,图5显示了,对于长宽比>1.0的图像(横向模式图像),pix2struct分割策略明显优于固定网格分割。
对于纵向模式图像,趋势相反,但固定网格分割仅稍微好一些。
鉴于研究人员希望ScreenAI模型能够在不同长宽比的图像上使用,因此选择使用pix2struct分割策略。
谷歌研究人员表示,ScreenAI模型还需要在一些任务上进行更多研究,以缩小与GPT-4和Gemini等更大模型的差距。
文章内容仅供阅读,不构成投资建议,请谨慎对待。投资者据此操作,风险自担。

奥维云网(AVC)推总数据显示,2024年1-9月明火炊具线上零售额94.2亿元,同比增加3.1%,其中抖音渠道表现优异,同比有14%的涨幅,传统电商略有下滑,同比降低2.3%。

“以前都要去窗口办,一套流程下来都要半个月了,现在方便多了!”打开“重庆公积金”微信小程序,按照提示流程提交相关材料,仅几秒钟,重庆市民曾某的账户就打进了21600元。

华硕ProArt创艺27 Pro PA279CRV显示器,凭借其优秀的性能配置和精准的色彩呈现能力,为您的创作工作带来实质性的帮助,双十一期间低至2799元,性价比很高,简直是创作者们的首选。


