����Meta��UC��������NYU��ͬ���Ԫ��������ģ�ͣ������������롹ָ����·����AI�Լ������У����ҸĽ����룬Ч����ɱ���ҽ���ģ�͡�
����LLM�����ݵĴ������ģ�����������Ԥѵ�������ϣ���������RLHF��DPO�ȶ���Ρ�
�������߲�������������˹���ע���ݣ����Һܿ���������ˮƽ����LLM�Ľ�һ����չ��
��������1�£�Meta��NYU���ŶӾ����������ģ�͵����ҽ������ƣ�ʹ��LLM-as-a-Judge����ʾ���ƣ���ģ����ѵ���ڼ�������ҷ�����

�������ĵ�ַ��https://arxiv.org/abs/2401.10020
�������ķ��֣���ʹ�����������ע�ߣ�LLMҲ��ͨ�������Լ�����Ӧʵ������������
�������������Ŷ��ַ�����һƪ�о�����LLM�����ҽ�������������ٰθ���һ����Ρ�

�������ĵ�ַ��https://arxiv.org/abs/2407.19594
�����Ͼ����Լ����Լ���֣���˲���ֻ��עģ����Ϊactor��δӷ������Ż���Ҳ��Ҫ��֤ģ����Ϊjudge�߱��������������������
����֮ǰ���о�����Ϊ���ڹ�עǰ�߶����Ժ��ߣ�����˵���ѵ���ڼ����ܵĹ��챥�͡�
�������������п�����ɱȱ��������������Խ����źŵĹ������(reward hacking)��
������ˣ�����Meta��NYU��UC�������Ȼ������о��������������Ҫ����һ����Ԫ����������——��ģ�������Լ������ۣ��Ӷ���������������

������Ȼ�������е��ƣ���ʵ���Ǻ����ġ�����ʵ�鷢�֣�������һ��Ƕ��������������Ч����
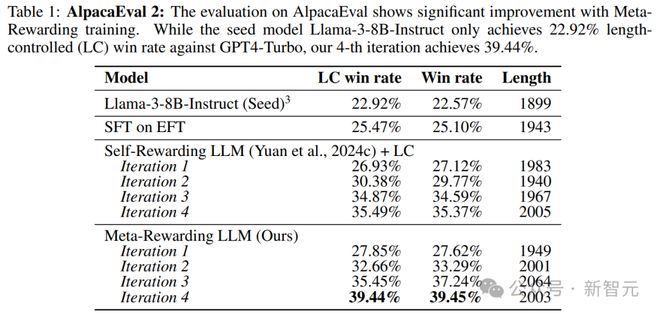
��������Llama-3-8B-Instruct��AlpacaEval 2�ϵ�ʤ�ʾʹ�22.9%����39.4%����GPT-4�ı��ָ���;��Arena-Hard�����20.6%������29.1%��
�������˵������1�·������о���LLM-as-a-Judge����ô��ƪ��������ġ�Ԫ�����������൱��LLM-as-a-Meta-Judge��
��������Judge����Ҫ���࣬Meta-JudgeҲ���Ը����㣬���ƺ���һ��֤����ģ�͵��������������Ѷ�����ල��������
����Meta��ѧ��Yann LeCunҲת������ƪ�о����������³�������˫�ع�——

����Meta�����Meta-Judge��FAIR�ܷ�ʵ��fair?
�����о�����Ҫ����Ҫ����Meta FAIR��һ���ع��������ˡ�

����Ԫ����(Meta-Rewarding)
�����ø�ֱ�Ļ�˵����Ԫ����������������ԭ�е�actor-judge�Ļ�����������meta-judge������ͬһ��ģ�͡��������ǡ�������Ҫ�����������ݵIJ��롣
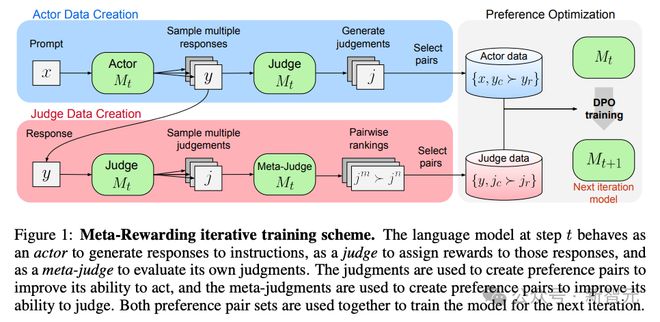
�������У�actor����Ը�����ʾ������Ӧ;judge����Ϊ�Լ�����Ӧ�������ۺʹ��;��meta-judge����Լ��Ĵ���������жԱȡ�
�������յ��Ż�Ŀ�꣬��ϣ��actor�����ɸ��õ���Ӧ����ѵ��Ч��������judge��ȷ�ʡ�
������ˣ�meta-judge��Ϊѵ��judge�Ľ�ɫ������ͬʱ����ģ����Ϊactor��judge�����ܡ�
���������ֽ�ɫ��ɵĵ���ѵ��ģʽ��ͼ1��ʾ���ڵ�t�������У����ռ�ģ��M_t����ʾx����Ӧ��������M_t���Լ��������ۣ��ɴ˵õ�����ѵ��actor��ƫ�����ݡ�
����֮����ͬһ����Ӧ����y����M_t���ɸ��ֲ�ͬ���۵ı��壬��meta-judge���д�ֺ��������ɴ˵õ�����ѵ��judge��ƫ�����ݡ�
�����������������ƫ�����ݣ�ͨ��DPO������ģ��M_t����ƫ���Ż����������һ�ֵ������õ�ģ��M_(t+1)��
��������ƫ��
����֮ǰ�Ĺ����������֣���Ϊjudge��ģ�ͻ�ƫ�ø�������Ӧ����ᵼ�¶��ֵ�����𰸵ġ����ȱ�ը����
������ˣ�����������һ�ּ��ġ����ȿ��ơ�(length-control)����——ʹ�ò���ρ∈[0,1]��Ȩ��judge�����ֺ���Ӧ�ı����ȡ�
�������磬���ڷ����ڵ�һ�ݶӵ�ģ����Ӧ����������ΧΪ[(1-ρ)Smax+ρSmin, Smax]��ѡ��������̵���Ӧ��Ϊ���Ŵ𰸡�
����Judgeƫ�����ݵĴ���
�������ȣ�ѡ��judge��û�а��յ�ģ����Ӧ��ͨ�������������judge��ȷ���ԡ�����ÿ��ѡ�е���Ӧy�����������N����Ӧ��ģ������{j1, … , jN}��
����֮�����е�ÿһ��(jm, jn)���гɶ�������ʹ����ͼ2��ʾ��meta-judge��ʾģ�塣

�������˸������۽����meta-judge����Ҫ����CoT�������̡�
����Ϊ����meta-judge���ܴ��ڵ�λ��ƫ��(����������ѡ�����ȳ��ֵ�Judgment A)����ͬһ������(jm, jn)�ύ��˳����meta-judge�����������ۣ��õ����ν��rmn��

�����������w1��w2���ڱ������ܴ��ڵ�λ��ƫ�ã�

��������win1st��win2nd��ʾ��meta-judge���������۹����У�����λ�õ����۷ֱ��ж��ٴ�ʤ����
���������ϱ����������Ծ�����(battle matrix)B��¼ÿһ�ε����ս����
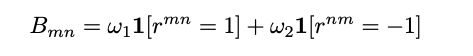
��������Elo���֣����ԴӾ���B����meta-judge��ÿ��judge�����Ԫ����������
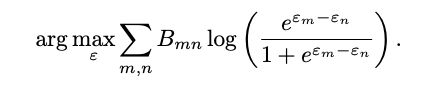
�������߷��֣�meta-judge��judgeһ����Ҳ��չ�ֳ�������ƫ�á���������ѡ����������������
����Ϊ�˱�������ѵ����ģ���چ��£�����judge���ݼ�ʱҲ��ȡ�˹��˴�ʩ�����meta-judgeѡ�е������������һ�����ȣ��������ݶԶ��ᱻֱ��������
��������ʵ��
����ʵ����
����ʵ��ʹ��Llama-3-8B-Instruct��Ϊ����ģ�ͣ����������ʵ��������֮ǰ���������ġ�Self-Rewarding Language Models��һ�¡�
������Ԫ����ѵ��֮ǰ��ʵ��������EFT(Evaluation Fine-Tuning)���ݼ��϶�����ģ�ͽ��мල��(SFT)��
����EFT���ݼ��Ǹ���Open Assistant�����ģ����ṩ��ʼ��LLM-as-a-Judgeѵ�����ݣ���������������������Ӧ����ѵ��ģ�ͳ䵱���١�
��������Ԫ����������ʵ������2�����ʾ����Llama-2-70B-Chat����8-shot��ʾ���ɡ�
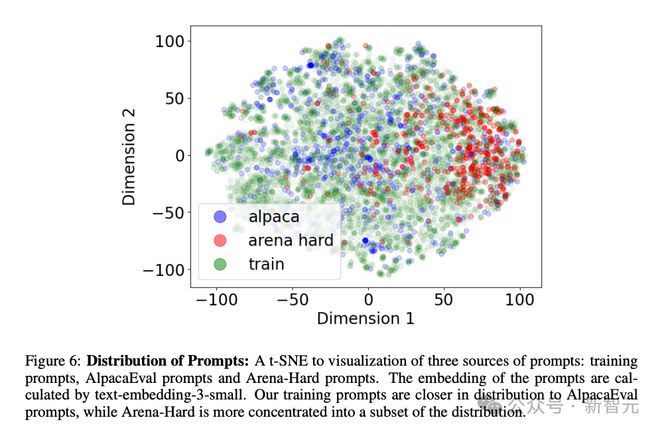
��������ͼ��ʾ��ѵ�����õ���ʾ�ڷֲ��ϸ��ӽ�AlpacaEval���ݼ�����Arena-Hard����ʾ���зֲ���ѵ����ʾ��һ���Ӽ���
��������ÿ�ε�����ʵ��Ӹ����Ӽ��г�ȡ5,000����ʾ���ܹ������Ĵε�����
���������������£�
����- Iter 1���ӳ�ʼ��SFTģ�Ϳ�ʼ��ʹ��DPO(Direct Preference Optimization)�����ɵ�actor��judge��ƫ�öԽ���ѵ�������M1��
����- Iter 2��ʹ��DPO��M1���ɵ�actor��judgeƫ�öԽ���ѵ�������M2��
����- Iter 3/4��ʹ��DPO����M2/M3���ɵ�actorƫ�öԽ���ѵ�������M3/M4��
����ÿ��prompt����ģ������K=7����Ӧ��ÿ�ε����ܹ�����3.5�����Ӧ��Ȼ�����ǹ��˵���ͬ����Ӧ(ͨ��ɾ��������50���ظ���)��
������������ʹ����ͬ�IJ�������Ϊÿ����Ӧ����N = 11^2����ͬ���жϡ�
������������
����Ԫ����ģ�͵�Ŀ����Ҫ��ģ�ͼ����Լ����ݡ��������Լ������������ʵ��ҲҪ����ģ������������ɫ�еı�����Ρ�
��������ģ����ǰ����������������ҽ���ģ�ͣ�������ͬ�ġ����ȿ��ơ����ƣ�����ֱ�ӶԱȳ�Ԫ�������ƴ������������档
�������ȣ��ȿ���������С��ݡ�����ô����
����ʵ��������������GPT4-as-a-Judge���Զ�������������AlpacaEval 2��Arena-Hard��MT-Bench���ֱ������ģ�͵IJ�ͬ���档
�������磬AlpacaEval��Ҫ��ע���쳡������ʾ�������˸����ճ����⡣
�������֮�£�Arena-Hard���������ӻ������ս�Ե����⣬Ҫ��Ԥ�����7������(�������������ԡ�������������)�������ı���
����MT-Bench��8����ͬ�����������Ҫ����ģ�͵Ķ��ֶԻ�������
������һ���棬Ϊ������LLM���١���������ô����ʵ�������LLM���ķ���������ƫ�õ�����ԡ����û�п��õ������ע���ݣ���ʹ�ý�ǿ��AI���ٴ��档
����ָ���������
����ͼ3չʾ����AlpacaEval���ϣ�Ԫ��������(���г��ȿ��ƻ���)ʤ����ѵ�������ı仯��
��������������Ԫ������ʤ�ʴ�22.9%���������39.4%��������GPT-4�����ӽ�Claude Opusģ�͡�
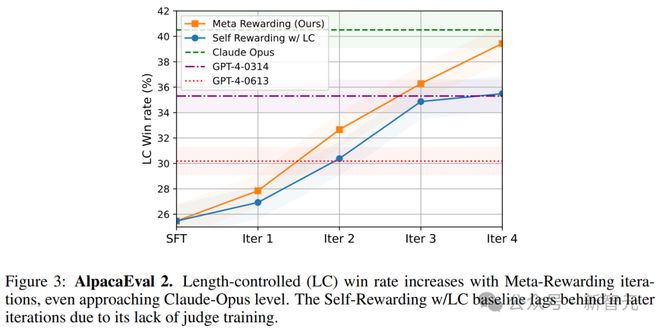
�������ǵ�����ģ�Ͳ�����ֻ��8B�����ң�������SFT��ʹ�õ�EFT���ݼ���û�������κζ�����˹����ݣ�����һ���൱����Ľ����
�������⣬���Ҳ֤����meta-judge�ͳ��ȿ��ƻ��Ƶ���Ҫ�ԡ�
�������ҽ���ģ��ѵ��������3��ʱ����ʼ���ֱ��ͼ�������Ԫ������ģ�Ͳ�û�У�����4��ʱ�Ա�������������
����������˶�ģ��������������ѵ������Ҫ�ԣ��Լ�meta-judge��һ��ɫ����Ч�ԡ�
�������1��ʾ������4�ֵ��������������ҽ���ģ�ͻ���Ԫ����ģ�ͣ�ƽ����Ӧ����(���ַ�Ϊ��λ)��û���������ӣ�֤�����ȿ��ƻ��Ƶ���Ч�ԡ�
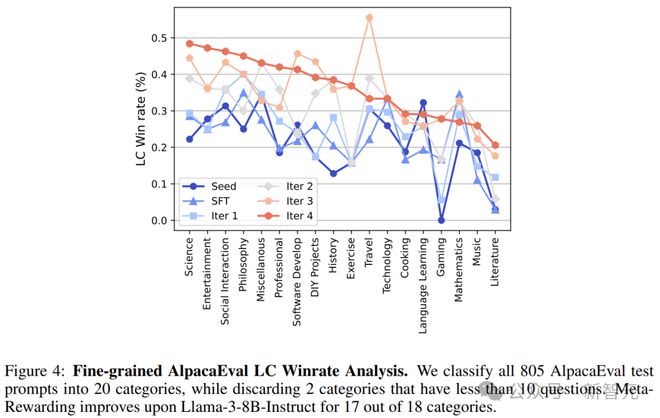
����Ԫ��������������������Ϊ���ԵĸĽ���
�������ȣ���AlpacaEval�е�805�����ϸ��Ϊ18����������ϸ���������Կ�����Ԫ���������Ľ�������������Ӧ(ͼ4)��������Ҫ����֪ʶ��������ѧ�ƣ������ѧ(Science)����Ϸ(Gaming)����ѧ(Literature)�ȡ�
����ֵ��ע����ǣ�����(Travel)����ѧ(Mathematics)�����࣬ģ�Ͳ�û��ʵ������������
�����ڶ���Ԫ�����Ľ��˶��ڸ��Ӻ���������Ļش�
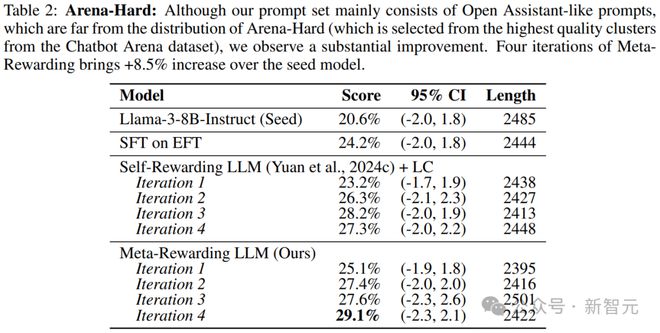
����ʵ���һ��ʹ��Arena-Hard������Ԫ���������ڻش��Ӻ;�����ս�Ե������ϵı��֡�
������2�е����������ʾ��Ԫ������4�ε����ж�����߷�����������ģ��(20.6%)��ȣ����������8.5%��
����������Ԫ�����ڽ�ѵ�����ֶԻ��������Ҳ��δ�������ֶԻ�������
�������Ľ�����MT-Bench�������Լ���ڽ�ѵ���������ݵ�����¶��ֶԻ���������ʧ��
����������±���ʾ��Ԫ����ģ�͵�4�ε�����������˵�һ�ֶԻ��÷֣���8.319(����ģ��)��ߵ�8.738�����ڶ��ֶԻ��÷ֽ��½��˲����� 0.1��
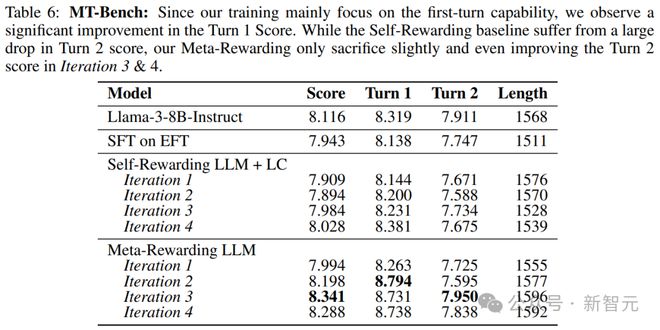
�������ǶԻ���ģ�������ҽ���+���ȿ���(Self-Rewarding + LC)�ľ�Ľ�����Ϊ����ͨ�����ڵڶ��ֶԻ��÷��ϣ��½����� 0.2��ͬʱû����ߵ�һ�ֶԻ��÷֡�
��������ģ������
����ʵ��������ģ�Ͷ�����ģ��Llama3-8B-Instruct������Ӧ���ж�ȷ�ԡ�
������ȱ���˹���ע������£�����ѡ�����Ԫ����ģ���뵱ǰ��ǿ���ж�ģ��gpt-4-1106-preview֮�����������ԡ�
���������������������в�ͬ�����ã���Ҫ��������������δ����ж�ģ������ƽ�֣����ʹ��������ָ�꣺��ƽ�ּ�Ϊ0.5��һ���Է���(agreement)������ƽ�ֽ����һ���Է�����
���������ʾ��ģ���ڽ���ѵ�����ж�����������ߡ�
������3�еķ�����ʾ�������ģ����ȣ����������������У�Ԫ������ǿ���GPT-4�ж�ģ��֮��������������ߡ�
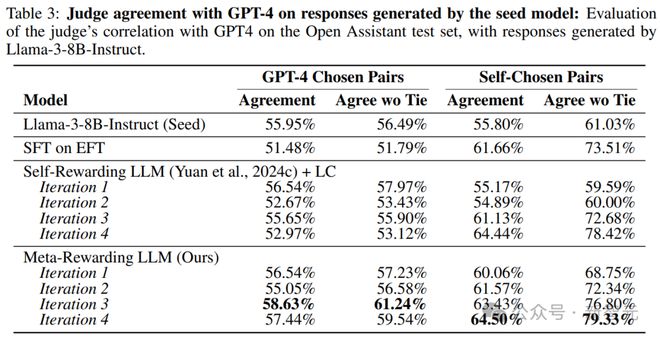
������Щ���������Ԫ���������ܹ��Ľ�ģ���ж�������ʹ���������������ӵ�����ģ��GPT-4������������ӽӽ���
�������⣬ʵ��Ա���ģ���жϽ����Open Assistant���ݼ���������Ӧ�����������(��7)������Ԫ����ѵ���������������ж�����ԡ�
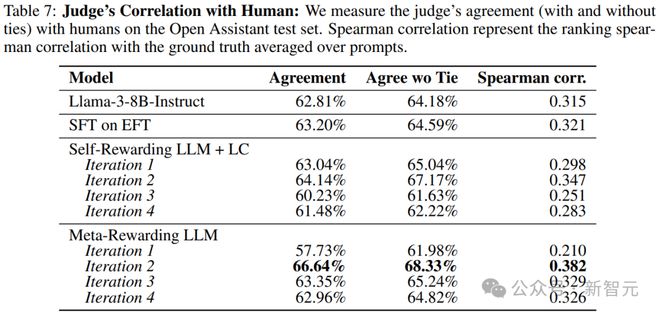
����Ȼ�������ָĽ��ں���ѵ��������û�г���������������ģ�����ɵ���Ӧ��������Ӧ֮��ķֲ����쵼�µġ�
��������
�������ȿ��ƻ���
�������ȿ��ƻ��ƶ��ڱ���ģ����Ӧ��ȫ���Ժͼ����֮���ƽ��������Ҫ��
����ʵ��Ƚ������һ��ѵ�������в�ͬ���ȿ��Ʋ���ρ�Ľ�������4��ʾ��
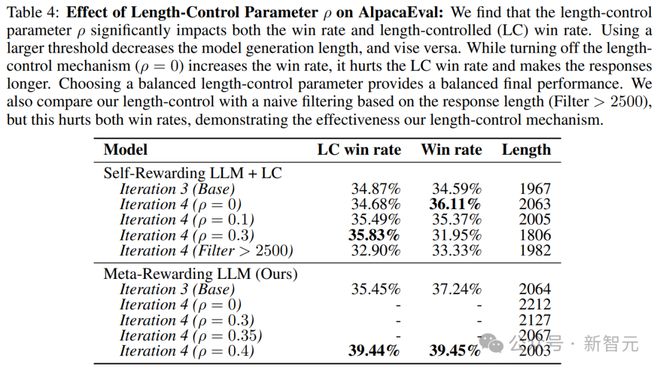
����ρ = 0���൱����ƫ������ѡ���в������κγ��ȿ��ơ�
��������Ԥ�ڵ�����������ѵ����ʽʹ��ģ�����ɵ���Ӧ��ù����߳���LCʤ�ʽ��͡�
����ʹ���ⲿ����ģ�ͽ���ѵ��
����Ԫ����������ģ���Լ���Ϊjudge������������������Ӧ;ʵ�鳢����ʹ��ǿ����ⲿ����ģ��Starling-RM-34B��Ϊ�Աȡ�
����Ȼ�����������StarlingRM-34Bδ���ڵ�һ�ε��������AlpacaEval��LCʤ��(24.63% vs. 27.85%)��������������䳤��ƫ����
����meta-judgeƫ��
������Ԫ����ѵ���ĵ�һ�ε���֮��meta-judge�������Ǹ������ڸ��߷������жϣ����5��ʾ��
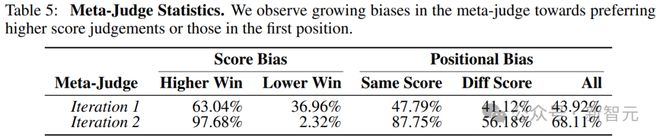
�������ַ���ƫ�������ؽ��жϵ����ֲַ�������5����б������λ��ƫ��������Ҳ������ѵ�������������ӵ����ƣ��ر����ڱȽ�������ͬ�������ж�ʱ��
�����ж����ֱ仯��Ϊ�˵�����Ԫ����ѵ�������������ж����ֲַ��ı仯��ʵ��ʹ���뽱����ģ������ͬ����֤��ʾ��
����ʹ��Llama-3-8B-Instruct��ÿ����ʾ������7����Ӧ��Ȼ��Ϊÿ����Ӧ����11���жϡ�ͼ5�����ֲַ��Ŀ��ӻ����ܶ���ʹ�ø�˹���ܶȹ���ġ�
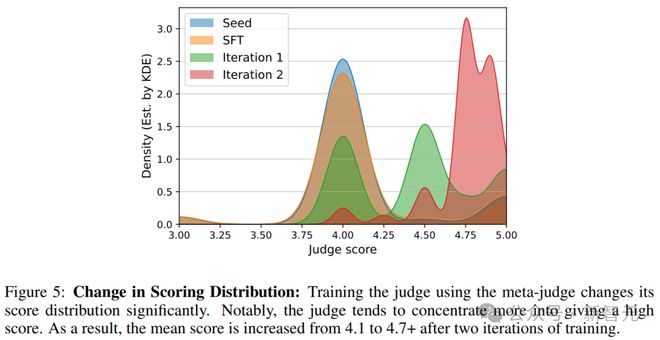
�����ɼ���ʹ��meta-judgeѵ���жϽ�һ�������������ɸ߷ֵĿ����ԡ�
����Ȼ�����ж�ѵ����ǰ���ε���ʹ�������ڷ���4.5��4.75��4.9�ķ��������ݸ���ָʾ��Щ����Ӧ����������
����������Щ�Ǹ߷֣��������ṩ�˸�ϸ�µ����������������ֲ�ͬ��������Ӧ��
��������
����ʵ�������һ���»��ƣ�ͨ��ʹ��meta-judgeΪ��Ϊjudge��ģ�ͷ���Ԫ����(meta-rewards)���Ӷ����ģ�͵�����������
�����������Խ���(Self-Rewarding)��ܵ�һ����Ҫ���ƣ���ȱ����ģ������������ѵ����
����Ϊ��ʹԪ����ѵ��(Meta-Rewarding training)������Ч��ʵ�黹������һ���µij��ȿ��Ƽ������Ի�����ʹ��AI��������ѵ��ʱ���ֵij��ȱ�ը���⡣
����ͨ���Զ�������AlpacaEval��Arena-Hard��MT-Bench��Ԫ������������Ч��Ҳ�õ�����֤��
����ֵ��ע����ǣ���ʹ��û�ж������෴��������£����ַ���Ҳ�����Ľ���Llama-3-8B-Instruct������Խ�������������෴����ǿ���߷����Խ���(Self-Rewarding)��SPPO��
�������⣬����ģ�͵���������ʱ���������������к�ǿ���AI����(�� gpt-4-1106-preview)��������ϱ��ֳ������ĸĽ���
����������ԣ��о�����ṩ��������֤�ݣ�֤�������κ����෴�������ҸĽ�ģ����ʵ�ֳ�������(super alignment)��һ����ǰ;�ķ���
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
