�������һ��ʱ�俪Դ��ģ���г��dz����֣�����ƻ����Դ�� 70 �ڲ���Сģ��DCLM��Ȼ������������Meta��Llama 3.1 ��Mistral Large2 ��̿�Դ���ڶ����������Llama 3. 1 �����˱�ԴSOTAģ�͡�
����������Դ�ɺͱ�Դ��֮������۲�û��ͣ�����ļ���
����һ����Meta��Llama 3. 1 �������ʾ��“���ڣ���������ӭ��һ����Դ�������ʱ����”��һ����Sam Altman�ڡ���ʢ���ʱ����ģ�ֱ�Ӱѿ�Դ��Դ��ì�����������Һ���ʶ��̬���档
������ǰ��ʱ��������˹����ܴ���ϣ������ֱ��“��Դ��ʵ��һ������˰”����Ϊ��Դģ����������ǿ�������ɱ����ͣ��ٴ��������ۡ�
�������ʢҲ���������Ŀ���������Ϊ��Դ�ͱ�Դ��������Ӫ�DZ˴˹�ͬ��������ͬ��չ������“��Դ��ʵ��һ������˰”��һ�۵�����˷�����“��Դ������ģ������ѵģ�����ô��������˰�أ�˭����˰?”��“���������ҵ�ø��ѱ�Դ������ģ�ͣ��DzŽ�'����˰'���������պܸߵ�ģ����Ȩ�ѡ�API���ã�һ�껨��������ǧ��������ȥ�������裬����Ա�������ò�����(ģ��)��”
�����ⳡ���۵ĺ����漰��������չ�ķ����ģʽ����ӳ�˲�ͬ��������ߵĹ۵��������������̸�۴�����ģ�͵Ŀ�Դ�ͱ�Դ֮ǰ����Ҫ������“��Դ”��“��Դ”�������������
����“��Դ”һ��Դ����������ָ���������������й�����Դ���룬�����κ��˲鿴���ĺͷַ�����Դ�����Ŀ���ͨ����ѭ���ݺ�����ͬ٭������ԭ�ٽ�������ģ�顢ͨ�Źܵ��ͽ��������ĸĽ������ʹ�������Linux��Mozilla Firefox��
������Դ������ר��������������ҵ������ԭ������Դ���룬ֻ�ṩ������ɶ��ij���(������Ƹ�ʽ)��Դ������ɿ��������պͿ��ơ����ʹ�������Windows������
������Դ��һ����������ģʽ�����ڿ��š�������Э����������ҹ�ͬ���������Ŀ����Ľ����ƶ������IJ��Ͻ����㷺Ӧ�á�
����ѡ���Դ�������������п��ܳ�Ϊһ���ȶ���רע�IJ�Ʒ�����DZ�Դ����ͨ����Ҫ��Ǯ������������κδ����ȱ�ٹ��ܣ�ֻ�ܵȴ���������������⡣
��������ʲô�ǿ�Դ��ģ�ͣ�ҵ�粢û����Դ����һ�����һ����ȷ�Ĺ�ʶ��
����������ģ�͵Ŀ�Դ��������Դ�������������Ƶģ����ǻ��ڿ��š�������Э��������������ͬ���뿪���Ľ����ƶ�����������������ԡ�
����Ȼ������ʵ�ֺ�����������������
����������Դ��Ҫ���Ӧ�ó�����ߣ���Դ����Դ����ϵͣ���������ģ�͵Ŀ�Դ���漰����������Դ�����������ݣ����ҿ����и���ʹ�����ơ���ˣ���Ȼ���ߵĿ�Դ��ּ�ڴٽ����ºͼ�����������������ģ�Ϳ�Դ���ٸ���ĸ����ԣ�����������ʽҲ������ͬ��
���������Ҳǿ�������ߵ�����ģ�Ϳ�Դ�����ڴ��뿪Դ��“ģ�Ϳ�Դֻ���õ�һ�Ѳ�������Ҫ����SFT(�ල��)����ȫ���룬��ʹ���õ���ӦԴ���룬Ҳ��֪�������˶��ٱ�����ʲô����������ȥѵ����Щ����������������ʰ�����ߣ��õ���Щ����������������վ�ھ��˵ļ���ϵ���������”
����������ģ�͵�ȫ���̿�Դ������ģ�Ϳ������������̣��������ռ���ģ����ơ�ѵ�����������л��ڶ����������������������������ݼ��Ĺ�����ģ�ͼܹ��Ŀ��ţ���������ѵ�����̵Ĵ��빲����Ԥѵ��ģ��Ȩ�صķ�����
������ȥһ�꣬������ģ�͵�����������ӣ���������ǿ�Դ�ģ�����������ж����?
�����������±��´�ѧ���˹������о�ѧ��Andreas Liesenfeld�ͼ�������ѧ��Mark DingemanseҲ���֣���Ȼ“��Դ”һ�ʱ��㷺ʹ�ã�������ģ�����ֻ��“����Ȩ��”������ϵͳ������������������涼������������
��������Meta�����ȿƼ��佫�������ģ�ͱ��Ϊ“��Դ”��ȴ��δ�����ײ㼼����ص���Ҫ��Ϣ����������������ǣ���Դ���ٵ�AI��ҵ�ͻ����ı��ָ����˳��ޡ�
�������о��Ŷӷ�����һϵ������“��Դ”������ģ����Ŀ���Ӵ��롢���ݡ�Ȩ�ء�API���ĵ��ȶ������������ʵ�ʿ��ų̶ȡ��о�����OpenAI��ChatGPT��Ϊ��Դ�IJο��㣬����“��Դ”��Ŀ����ʵ״����

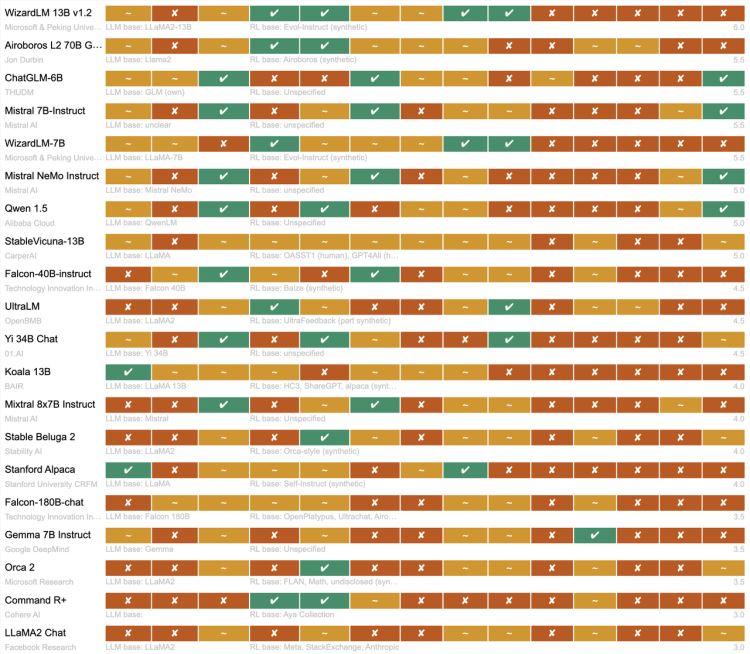

����✔Ϊ���ţ�~Ϊ���ֿ��ţ�XΪ���
���������ʾ����Ŀ���������������������а�Allen Institute for AI��OLMo����ŵĿ�Դģ�ͣ������BigScience��BloomZ�����߶����ɷ�Ӫ����֯������
�������ijƣ�Meta��Llama�Լ�Google DeepMind��Gemma ��Ȼ�Գƿ�Դ�ţ���ʵ����ֻ�ǿ���Ȩ�أ��ⲿ�о���Ա���Է��ʺ�ʹ��Ԥѵ��ģ�ͣ�����������ģ�ͣ�Ҳ��֪��ģ���������ض������������
�������LLaMA3 ��Mistral Large2 �ķ��������˹㷺��ע����ģ���ڿ����Է��棬LLaMA3 ������ģ��Ȩ�أ��û����Է��ʺ�ʹ����ЩԤѵ����ָ�������ģ��Ȩ�أ�����Meta���ṩ��һЩ�������룬����ģ�͵�Ԥѵ����ָ����������δ�ṩ������ѵ�����룬LLaMA 3 ��ѵ������Ҳ��δ�������������LMeta�����˹���LLaMA 3.1 405B ��һ�� 93 ҳ�ļ������档
����Mistral Large2 ��������ƣ���ģ��Ȩ�غ� API ���汣���˽ϸߵĿ��Ŷȣ��������������ѵ�����ݷ���Ŀ��ų̶Ƚϵͣ�������һ��ƽ����ҵ����Ϳ����ԵIJ��ԣ������о�ʹ�õ�����ҵʹ���������ơ�
�����ȸ��ʾ���ù�˾������ģ��ʱ“�������Ϸdz���ȷ”�����ǽ�Gemma��Ϊ���Ŷ��ǿ�Դ��“���еĿ�Դ���������ֱ��Ӧ���� AI ϵͳ��”
���������о���һ����Ҫ������ŷ�˵��˹����ܷ������÷�����Чʱ���Թ���Ϊ���ŵ�ģ��ʵʩ�Ͽ��ɵļ�ܣ���˹��ڿ�Դ�Ķ�����ܻ��ø�����Ҫ��
�����о���Ա��ʾ�����µ�Ψһ;����ͨ������ģ�ͣ�Ϊ����Ҫ�㹻����Ϣ�������Լ��İ汾��������ˣ�ģ�ͻ����������飬���磬һ��ģ���ڴ������������Ͻ�����ѵ������ô��ͨ���ض����Կ��ܲ�����һ��ɾ͡�
��������Ҳ����˶�Ŀ�Դ��������ij��ָе�������ϲ��ChatGPT�dz��ܻ�ӭ�������ں��������������Ƕ���ѵ�����ݻ�����Ļ���ֶ�һ����֪��������Щϣ�����õ��˽�ģ�ͻ���ڹ���Ӧ�õ�����˵������һ������������Դ�������ʹ�ùؼ��Ļ����о���Ϊ���ܡ�
����������Ҳ�Թ��ڲ��ֿ�Դ������ģ�͵Ŀ�Դ���������ͳ�ƣ�

�����ӱ������ǿ��Կ������ͺ����������ƣ���Դ��Ϊ����ģ�ͻ��������о���������������Ҫ����Ϊ�о�������Ŀ�����ƶ����н�������ҵ��չ���������ڿ������о��ɹ���
��������ҵ��˾����������Դ���ƣ���������Ϊǿ���ģ�ͣ���ͨ���ʵ��Ŀ�Դ�����ھ����л�����ơ�
������GPT- 3 ��BERT��������ԴΪ��ģ����̬ϵͳ��������Ҫ���ƶ�����
����ͨ��������ܹ���ѵ���������о���Ա�Ϳ����߿�������Щ�����Ͻ��н�һ����̽���Ľ�������������ǰ�صļ�����Ӧ�á�
������Դ��ģ�͵ij������������˿������ż��������ߺ���С��ҵ�ܹ�������Щ�Ƚ���AI�����������ش��㿪ʼ����ģ�ͣ��Ӷ���ʡ�˴�����ʱ�����Դ����ʹ�ø��ഴ����Ŀ�Ͳ�Ʒ���Կ�����أ��ƶ���������ҵ�ķ�չ�����������ڿ�Դƽ̨�ϻ��������Ż�������Ӧ�ð�����Ҳ�ٽ��˼��������Ӧ�á�
�����Խ����Ϳ��ж��ԣ���Դ������ģ���ṩ�˱�����Դ��ѧ�������ֿ�����ͨ���о���ʹ����Щģ�ͣ��ܿ��������Ƚ�AI����������ѧϰ���ߣ�Ϊ��ҵ��������ѪҺ��
����Ȼ����������ģ�͵Ŀ����Բ��ǼĶ�Ԫ���ԡ�����Transformer��ϵͳ�ܹ�����ѵ�����̼�Ϊ���ӣ����Լ���Ϊ���Ż��ա���Դ��ģ�Ͳ���һ���ı�ǩ������һ�����ף�����ȫ��Դ�����ֿ�Դ���̶ȸ��졣
����������ģ�͵Ŀ�Դ��һ��Ӷ�ϸ�µĹ�������������ģ�Ͷ����뿪Դ��
��������Ӧ��“���°��”�ķ�ʽҪ��ȫ�濪Դ����Ϊ���漰������������Դ�Ͱ�ȫ��������Ҫƽ����밲ȫ�����������Ρ�����Ƽ��������������һ������Ԫ���Ĺ���ʽ���ܹ���һ�����ḻ�ļ�����̬ϵͳ��
������Դ�ͱ�Դģ�͵Ĺ�ϵ�������������������ҵ�п�Դ�ͱ�Դ�����Ĺ��档
������Դģ�ʹٽ��˼����Ĺ㷺�����ʹ��£�Ϊ�о��ߺ���ҵ�ṩ�˸�������ԣ�����Դģ�����ƶ���������ҵ�ı������������ߵ����Ծ��������˳����Ľ��Ķ�����ҲΪ�û��ṩ�˶�������ѡ��
�������翪Դ��ר��������ͬ�����˽����������̬����Դ�ͱ�Դ��ģ��֮��Ҳ���Ƕ�Ԫ���������ߵIJ��淢չ���ƶ�AI�������Ͻ��������㲻ͬӦ�ó����������Ҫ���������գ��û����г��������ʺ��Լ���ѡ��
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
