今天凌晨,OpenAI开源了最新基准测试集SimpleQA,可以帮助开发者轻松检测、校准大模型的真实性能力。
目前,很多大模型会出现一本正经胡说八道的问题,例如,你提问NBA历史上得分最多的是谁,它回答是迈克尔乔丹,实际上是勒布朗詹姆斯。包括OpenAI自己发布的GPT-4o、o1-preview、o1mini等前沿模型都有这些“幻觉”难题。
所以,SimpleQA对于开发者来说,可以精准测试大模型能否输出正确的答案,并对模型的说谎能力进行校准然后进行大幅度优化完善模型能力。
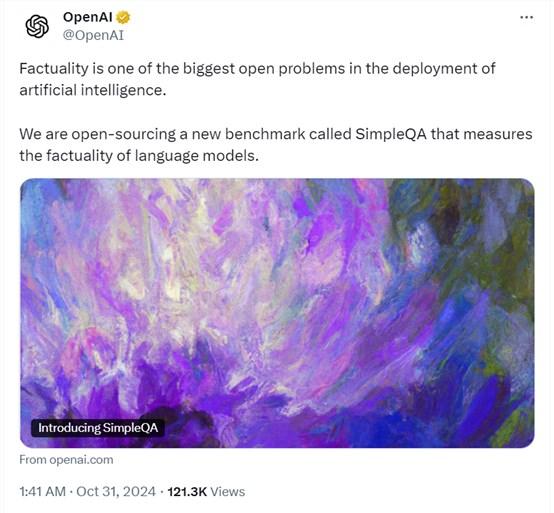
有网友表示,看了SimpleQA的测试数据才发现,o1-mini和o1-preview的性能差距这么大,o1-mini连GPT-4o都打不过。
令人惊讶的是,SimpleQA 被有意设计用来挑战像 GPT-4这样的高级模型,其中只包括至少有一次模型尝试失败的问题。这种对抗性的基准测试方法感觉像是一种大胆的转变,旨在揭示模型的局限性并推动模型的发展。
多整开源这是好事。别忘了你名字的初衷啊~

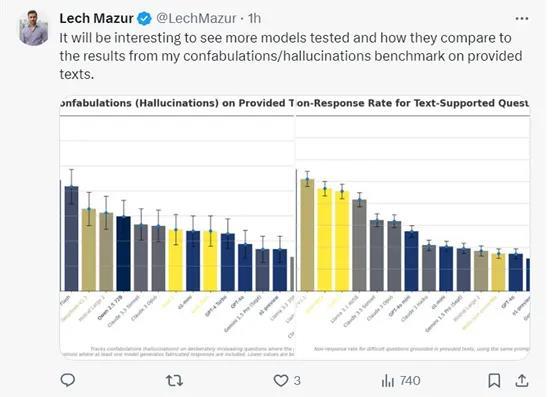
这很有趣,会看到更多的模型被测试,以及它们与我在提供的文本上进行的虚构/幻觉基准测试结果的比较。
很想看看o1模型的完整版测试。

完全同意事实性在人工智能中的重要性。SimpleQA 的引入可以显著提升我们对语言模型在这一领域表现的理解。这是一项及时的举措,准确的数据对于信任人工智能系统至关重要。期待看到这个基准测试的影响。
这很重要,因为确保大模型的事实性对于防止错误信息的传播至关重要,而 SimpleQA 提供了一种标准化的方法来评估和改进模型可靠性的这一关键方面。
很棒,重要的更新!

SimpleQA简单介绍
在数据收集阶段,SimpleQA的问题参考答案由两名独立的 AI 训练员确定,并且训练员在创建问题时被要求提供支持答案的网页链接,以确保答案有可靠的依据。
例如,对于 “谁是苹果公司的创始人之一” 这样常识性问题,训练员会根据历史资料和官方信息确定答案为 史蒂夫乔布斯等,并附上如苹果公司官方网站等相关链接作为证据。
同时,问题的设计使得预测答案易于评估,只允许有一个明确且无可争议的答案,避免了模糊性和歧义性。比如 “哪一年 iPhone 首次发布”,答案明确为“2007年”,而不是一个范围或模糊的表述。
SimpleQA的评估问题和答案都非常简短,这使得运行速度快且操作简单。在评估模型回答时,通过 OpenAI API进行评分也十分迅速。数据集中包含4326个问题,能够在一定程度上降低不同次运行之间的方差,使评估结果更加稳定可靠。
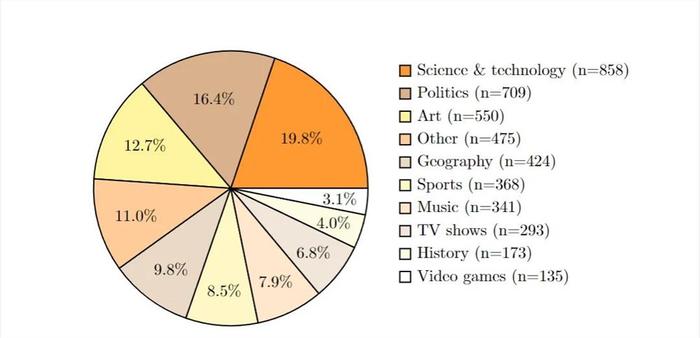
例如,在对多个模型进行测试时,不会因为数据集本身的不稳定性而导致结果出现较大波动,从而能够更准确地比较模型之间的性能差异。
SimpleQA的评估集非常多元化。涵盖历史、科学技术、艺术、地理、电视节目等多个领域。这种多样性使得评估结果更具普遍性和代表性,能够全面地检验模型在不同知识领域的事实性回答能力。
另一个好处是它的校准测量功能。通过询问模型对其答案的信心,研究者可以了解模型是否知道它们知道什么,这是一个很重要的校准现象。如果一个模型能够准确地评估自己的信心水平,那么它就是一个校准良好的模型。
OpenAI通过SimpleQA对GPT-4o、o1-preview、o1mini、Claude-3-haiku、Claude-3-sonnet等前沿模型进行了综合测试。结果显示,较大模型通常具有更高的性能,但即使是前沿模型在SimpleQA 上的表现也并非完美。
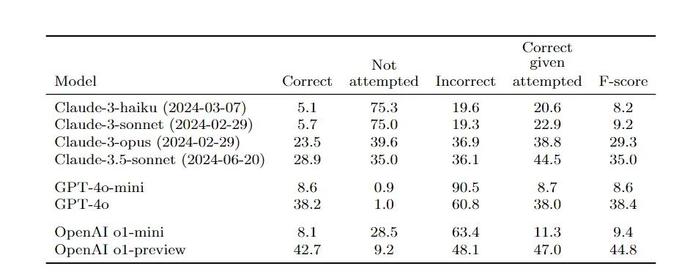
例如,GPT -4o 在回答一些问题时能够给出较高比例的正确答案,但仍有部分错误回答和未尝试回答的情况。同时,通过测量模型的校准情况,发现模型虽然有一定的信心概念,但普遍存在高估自己信心的问题,模型的信心水平与实际回答的准确性之间存在差距。
文章内容仅供阅读,不构成投资建议,请谨慎对待。投资者据此操作,风险自担。

奥维云网(AVC)推总数据显示,2024年1-9月明火炊具线上零售额94.2亿元,同比增加3.1%,其中抖音渠道表现优异,同比有14%的涨幅,传统电商略有下滑,同比降低2.3%。

“以前都要去窗口办,一套流程下来都要半个月了,现在方便多了!”打开“重庆公积金”微信小程序,按照提示流程提交相关材料,仅几秒钟,重庆市民曾某的账户就打进了21600元。

华硕ProArt创艺27 Pro PA279CRV显示器,凭借其优秀的性能配置和精准的色彩呈现能力,为您的创作工作带来实质性的帮助,双十一期间低至2799元,性价比很高,简直是创作者们的首选。


