10月27日消息:谷歌最新发布的PaLI-3视觉语言模型(PaLI-3)在小体量下实现了SOTA性能,引起广泛关注。这款模型以更小的体量和更快的推理速度实现更强大的性能,是谷歌去年推出的多模态大模型PaLI的升级版。
通过对比预训练方法,研究人员深入研究了视觉-文本(VIT)模型的潜力,从而在多语言模态检索中达到了SOTA水平。这一成功凸显了较小规模模型在实际应用和高效研究中的重要性,提供了强大性能和低参数需求的替代方案,有望推动视觉语言领域的发展。
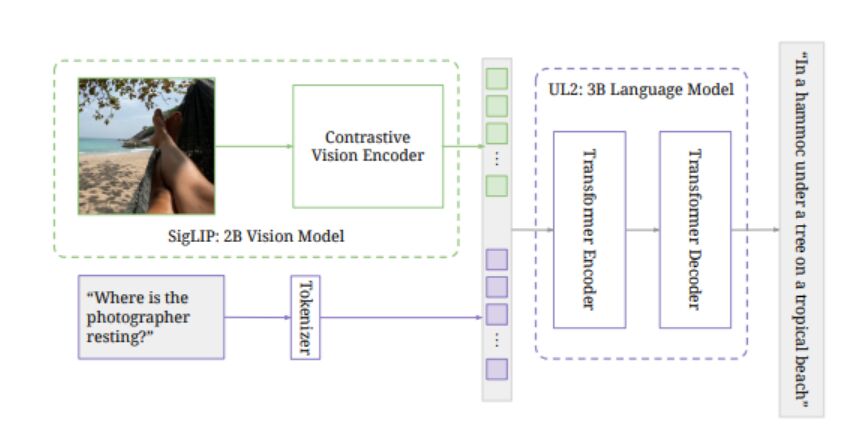
视觉语言模型在人工智能领域发挥着重要作用,PaLI-3将自然语言理解和图像识别完美融合,成为AI创新的先锋。与其他模型如OpenAI的CLIP和Google的BigGAN类似,这些具有文本描述和图像解码能力的模型推动了计算机视觉、内容生成和人机交互等领域的发展,成为科学研究和商业发展的核心力量。
PaLI-3的内部结构采用了预训练的VIT-G14作为图像编码器,并使用SigLIP的训练方法,其中VIT-G14的20亿参数是PaLI-3的基石。对比预训练在图像和文本嵌入后关联特征层面,将视觉和文本特征合并后输入到30亿参数的UL2编码-解码器语言模型中,实现了精确的文本生成,也可用于特征任务的查询提升,如视觉问答(VQA)。
总的来说,PaLI-3在视觉语言模型领域表现出色,特别在定位和视觉文本理解等任务中取得了卓越的性能。它的基于SigLIP的对比预训练方法开辟了多语言跨模态检索的新时代。这一模型在多个任务和数据集上都展现出杰出表现,为视觉语言领域的研究和应用带来了新的可能性。
虽然PaLI-3尚未完全开源,但已发布了多语言和英文SigLIP Base、Large和So400M模型,为感兴趣的研究人员提供了尝试的机会。这一创新有望影响视觉语言模型的未来发展方向,提供更高效的解决方案。
文章内容仅供阅读,不构成投资建议,请谨慎对待。投资者据此操作,风险自担。

奥维云网(AVC)推总数据显示,2024年1-9月明火炊具线上零售额94.2亿元,同比增加3.1%,其中抖音渠道表现优异,同比有14%的涨幅,传统电商略有下滑,同比降低2.3%。

“以前都要去窗口办,一套流程下来都要半个月了,现在方便多了!”打开“重庆公积金”微信小程序,按照提示流程提交相关材料,仅几秒钟,重庆市民曾某的账户就打进了21600元。

华硕ProArt创艺27 Pro PA279CRV显示器,凭借其优秀的性能配置和精准的色彩呈现能力,为您的创作工作带来实质性的帮助,双十一期间低至2799元,性价比很高,简直是创作者们的首选。


