来自微软、MIT等机构的学者提出了一种创新的训练范式,攻破了大模型的推理缺陷。他们通过因果模型构建数据集,直接教模型学习公理,结果只有67M参数的微型Transformer竟能媲美GPT-4的推理能力。
「因果推理」绝对是当前GenAI热潮下的小众领域,但是它有一个大佬级的坚定支持者——Yann LeCun。
他在推特上的日常操作之一,就是炮轰Sora等生成模型,并为自己坚信的因果推理领域摇旗呐喊。
甚至,早在2019年VentureBeat的采访中,他就表达过这一观点:我们需要在深度学习模型中引入事件的因果关系,才能增强泛化能力,减少训练数据使用。
对于当前最流行的模型架构Transformer,我们能教它因果推理吗?
最近,来自微软MIT等机构的研究人员提出了一种训练大模型新范式——公理框架(Axiomatic Framework)。
论文中,作者从头开始训练了6700万参数的模型,仅使用了简单的因果链作为训练数据。

令人惊讶的是,在推断复杂图表中的因果关系时,67M模型的表现超越了十亿级参数LLM,甚至可以与GPT-4相媲美。
论文地址:https://arxiv.org/abs/2407.07612v1
微软MIT等团队最新方法的提出,是受到了图灵奖得主Judea Pearl启发。
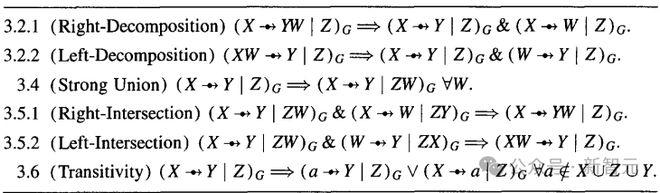
Pearl曾提出了结构化因果规则中的因果无关性公理,即直接通过符号化公理示例来教Transformer模型学习被动数据(passive data)。
这种方法不同于传统机器学习模型,使用由公理推导出的数据。
正如结果所示,通过公理训练,研究证明了Transformer模型可以学习因果,从而推断因果关系,并从相关性中识别因果性。

这暗示了,像GPT-4等大模型的训练,可以通过网络数据中的带噪声的公理化示例学习因果知识,而无需进行干预实验。

网友称赞道,「研究者的观点非常耐人寻味,因果推理一直是LLM的致命弱点,进一步发展这一领域,势在必行」。

「这类研究可能是通向半AGI的一条途径」。
研究背景
因果推理(causal reasoning)是一种推理过程,遵守有特定因果性的预定义公理或规则。
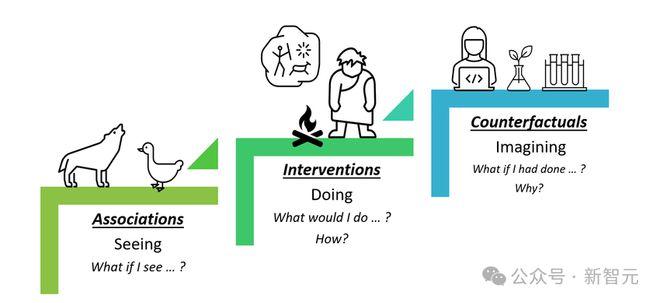
图灵奖得主Judea Pearl曾通过如下的「因果关系阶梯」(ladder of causation)定义了可能的因果推理类型。
通常因果推理所用的公理或规则并不会被直接引入,模型学习的只是数据。公理或规则作为归纳偏差被纳入模型,比如通过正则化、模型架构或变量选择等方式。
而这篇论文想要探讨的,就是模型能否从被动的符号演示中直接学习公理或规则。作者将这种方法称为「公理化训练」(axiomatic training)。
假设因果公理都可以以如下形式表示: <前提,假设,结果> ,其中结果只有「是」和「否」两种形式。
这基本类似于亚里士多德提出的「三段论」格式,比如Judeal Pearl书中提出的「碰撞公理」(collider axiom)就可以表示为:
这只是单个公理的表示,那么如何表达一个复杂系统中多个公理的组合呢?甚至,我们能用有限数量的公理表达任意因果模型吗?
此处,论文引用了Judea Pearl和David Galles在1997年发表的一项研究,他们证明了,对于给定的稳定概率因果模型,都存在一组有限公理,可以充分表征对应的有向因果图。
因果模型M=(X,U,F)被定义为内部变量X、外部变量U和一组结构方程F的集合,结构方程描述了变量X和U之间的因果关系。
模型M的另一种等效表示方式就是有向图G,用有向边Vi⭢Vj表示两个节点Vi和Vj之间的因果关系。
所谓的「稳定概率」(stable probabilistic)因果模型,是指他们对模型作出的稳定性假设,指M中所有的不相关性(X ↛ Y|Z)都是稳定的,写作:
在稳定性假设下,Galles和Pearl共描述了6个公理,而这篇论文主要关注传递性公理。对于稳定概率的因果模型,给定系统中的变量X、Y、Z,传递性公理可以写作:
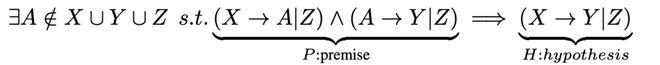
将上述表达式通过取反进一步简化,可以写出其含有因果相关性的版本:
其中表达式左侧即为前提,右侧即为假设。
这样的公理可以派生出数千个合成的符号表达式,从而用于向Transformer模型「教授」特定公理。
公理化训练
训练数据
上述含有前提和假设的公理能映射到「是」或「否」的标签,一条训练数据就可以表示为{(P,H,L)}的元组形式。
给定一个真实的因果图,就可以通过应用传递性公理(一次或多次),枚举出所有可能的N个元组{(P,H,L)},从而构建出数据集D。
比如,因果图中包含X1⭢X2⭢X3⭢…⭢Xn这样的链拓扑时,一个可能的前提是X1⭢X2∧X2⭢X3,相应的假设X1⭢X3的标签为「是」,而另一个假设X3⭢X1标签就为「否」。
值得注意的是,论文中为了表达的清晰性,使用了数学语言进行描述,但实际上用于训练的数据集只包含自然语言。
比如,上面例子中的前提应该表达为「X1导致X2,且X2导致X3」。
数据扰动:泛化的关键
之前有研究表明,以「扰动」(perturbation)形式增加训练数据的可变性与多样性,有助于提升模型的泛化能力。
因此,作者在不同层次上对训练数据引入结构化扰动,以最大化数据集分布的多样性。
1)节点名称:传递链上每个节点的名称都由1~3个字母/数字组成,长度和使用的特定字符是随机生成的。
2)因果图拓扑结构:主要包含两种类型
- 顺序结构(sequential):所有的因果边方向都是从后向前,共同形成一个典型的「传递链」,比如X⭢Y⭢Z这种形式
- 随机翻转(random flipping):给定一个顺序结构的传递链,对其中一些边进行随机翻转,从而引入复杂性。比如X⭢Y⭢Z可以被修改为X⭢Y⭠Z。
随机翻转可以在单一方向的链中添加分叉结构(X⭠Y⭢Z,fork)和碰撞结构(X⭢Y⭠Z,collider),它们是任何有向因果图的基本构建块,有助于提升模型进行跨结构泛化的能力。
3)链长度:训练集中加入了长度不等的链,包含3~6节点。
损失函数
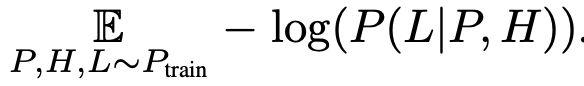
论文没有采用训练Transformer模型常用的next token预测损失,而是根据给定数据集中每个元组的真实标签进行定义,表示为:
位置编码
除了训练数据和损失函数之外,另一个重要因素是位置编码的选择。
之前有研究表明,位置编码机制对Transformer的序列长度泛化能力有明显影响,但不同的研究似乎得出了互相矛盾的结果。
因此,作者在研究中分别尝试了不同的方法,包括可学习位置编码(LPE)、正弦位置编码(SPE)和无位置编码(NoPE)。
训练和评估的整体流程如图1所示,Transformer模型在顺序链和带有随机翻转的链上训练,长度为3~6个节点。
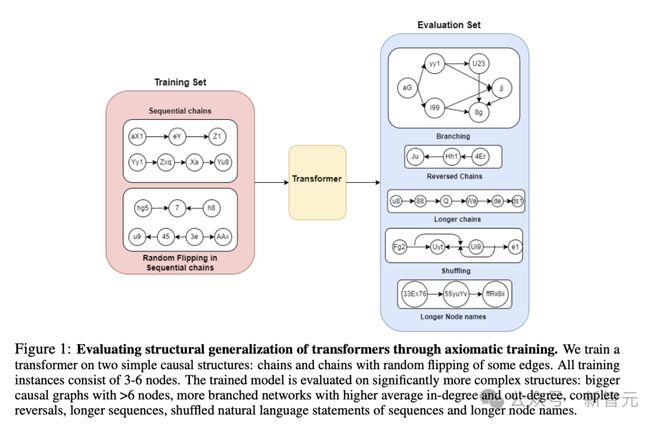
之后,训练过的模型在具有>6个节点的更复杂结构上进行评估,其中节点平均的出度(out-degree)和入度(in-degree)都更大,序列更长,且引入了分支、反转(reversal)等复杂变化。
实现细节:架构、分词器和训练过程
具体来说,研究人员基于GPT-2的架构,训练了一个拥有6700万参数的解码器模型。
该模型有12个注意力层、8个注意力头,以及512个嵌入维度。
值得一提的是,67M模型是在各种训练数据集上,从头开始训练的。为了理解位置编码(PE)的影响,他们考虑了正弦位置编码(SPE)、可学习位置编码(LPE)以及不使用位置编码(NoPE)三种情况。
所有模型都使用AdamW优化器进行训练,学习率为1e-4,训练100个epoch。
由于训练数据集遵循特定结构,研究人员还开发了一个自定义分词器(custom tokenizer)。
字母数字节点名称在字符级别进行分词,而像「causes」、「cause」、「Does」、「Yes」「No」这样的特殊术语则在词级别进行分词。
简言之,字符级分词用于字母数字节点名称,词级分词用于特殊术语。
这种方法可以避免在测试时,出现词汇表外(OOV)token,因为测试集中的字母数字节点名称可能与训练集中的不同。
采用这种方法后,6700万参数Transformer模型的词汇表大小为69。
实验结果
复杂因果场景的泛化
研究人员首先展示了,通过公理化训练的Transformer模型在泛化到更大、更复杂的因果图方面的表现,并将其与预训练的大模型进行了比较。
序列长度泛化
表1展示了不同模型在评估训练过程中,未见过的更长因果链时的准确率。
在基线预训练语言模型中,GPT-4在标准和随机翻转的因果链上都取得了最高的准确率。
令人惊讶的是,尽管TS2(NoPE)模型在训练过程中从未见过更长的序列,但它的表现能够与万亿参数规模的GPT-4模型相媲美。
虽然训练时只用到了长度为3~6个节点的因果链,但序列长度为7~13时,TS2(NoPE)在标准和随机翻转的链上,获得了比GPT-4更高或相当的准确率。
对于序列长度为14-15的情况下,其准确率有所下降(标准链为0.85,随机翻转链为0.78),但仍然显著高于Gemini-Pro 、Phi-3模型。
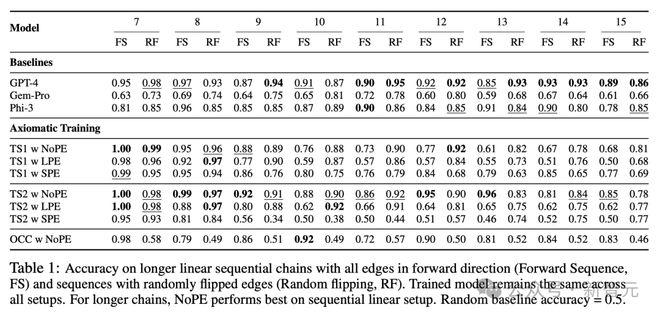
需要注意的是,随机预测会得到50%的准确率,这表明通过公理化训练的TS2(NoPE)模型,能够将其推理能力泛化到更长的序列上。
节点名称转变
对于在TS2数据集上训练的模型,研究人员还评估了其对变量名称变化的泛化能力(图 3)。

结果发现,TS2(NoPE)对节点名称的变化很稳健,在引入新的、更长的名称时仍能保持较高的准确率。它还保持了对新节点名称较长序列的通用性,其表现与GPT-4相似。
因果序列顺序
与长度和节点名称的变化不同,反转(reversal)以及分支(branching)操作改变了因果结构,因此能更好地评估模型是否学习到了对结构的准确表示。
在表2b中,TS2(NoPE)在长度不超过8的因果链上,获得的准确率高于Gemini Pro、Phi-3。长度为9时,TS2(NoPE)的准确率为0.73,与Gemini Pro(0.74)相当。
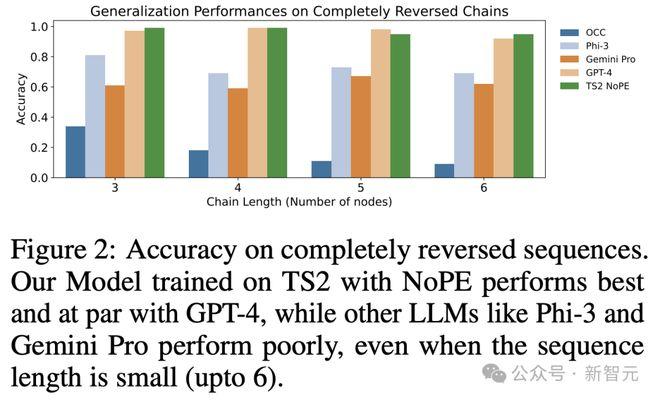
在表2a中,研究者还观察到对完全反转序列进行评估的类似模式。
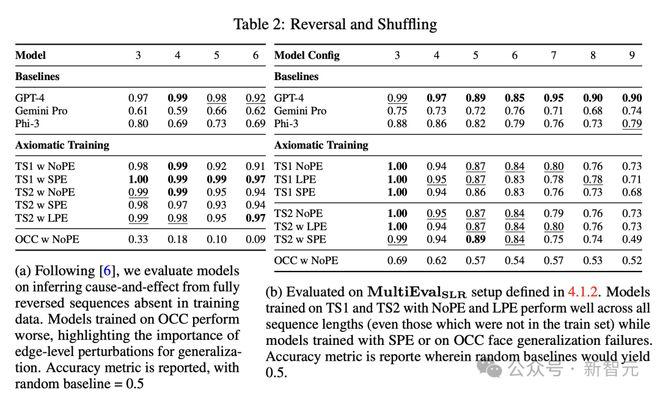
在这项任务中,公理训练模型TS2(NoPE)在限制链长度为3-6时,表现优于GPT-4。特别是,其准确率(长度为 6 的链为0.94)大大高于Gemini Pro和Phi-3(分别为0.62和0.69)。
分支(Branching)
分支可能是最有挑战性的任务,因为它引入了在训练期间未见的新结构。
虽然GPT-4在图大小不断增大的情况下获得了最佳准确率,但TS2(NoPE)模型在除一个节点外的所有图大小上,都比Gemini Pro获得了更高的准确率。
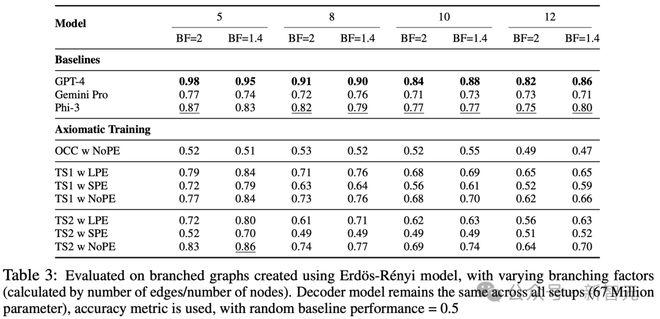
即使在有12个节点和1.4个分支因子的图形上进行评估,TS2(NoPE)模型也能获得70%的准确率,明显优于随机模型(50%)。
总结
在所有评估设置中,公理化训练模型TS2(NoPE)的性能明显优于随机基线,即使因果链的长度超过其训练数据。
特别是,模型没有在完全反转的链上进行训练,它的表现也与规模更大的GPT-4模型相当(图 2)。
在其他任务中,它的准确性往往优于或与Gemini Pro、Phi-3等十亿参数规模的模型相当。
这些结果表明,经过公理训练的模型可以从简单因果序列的演示中,学会推理更复杂的因果结构。这表明公理训练在因果图推理方面的潜力。
其他结果:数据多样性和位置编码的作用
位置编码的作用
比较不同位置编码选择的模型性能,研究人员发现没有位置编码的模型在更长的序列(最长到15个节点的链)和复杂的、未见过的图结构上都能很好地泛化,尽管它们仅在3-6个节点的链上进行训练。
使用正弦位置编码(SPE)和可学习位置编码(LPE)的模型在更长的链上表现也不错,但当节点名称长度增加时表现较差,即使是在节点数较少的链上也是如此(图3)。
这种使用SPE和LPE的泛化失败,突出了模型无法处理训练集中序列的微小扰动。
此外,SPE在不同的结构维度上表现不佳(如分支)以及基于顺序的设置(shuffling和反转)。
可学习的位置编码在长度达9的线性链上表现良好,但之后急剧下降。
总的来说,研究结果扩展了早期关于不使用位置编码(NoPE)有效性的研究,将其应用于理解因果序列的任务,并在测试时泛化到更长的长度和复杂的结构。
数据扰动的重要性
除了位置编码外,训练数据中序列的多样性也起着重要作用。
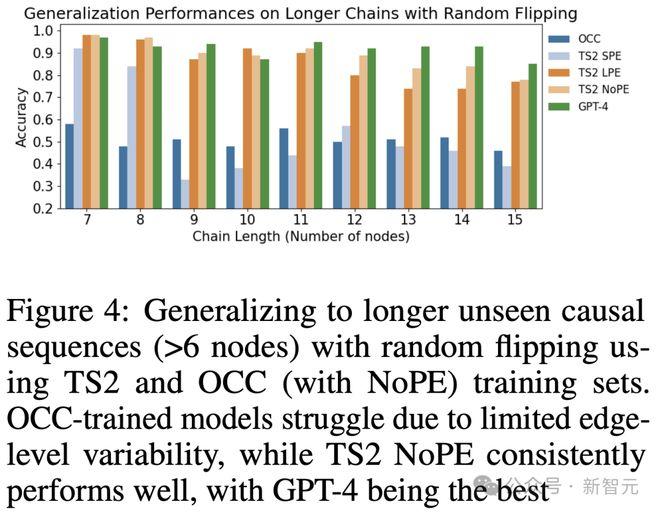
仅在因果链上,训练的模型可以泛化到较长的链(表 1),但不能泛化到其他DAG结构(见图4中的翻转,图2中的反转,表3中的分支)。
在TS1或TS1上训练的模型在所有情况下都具有通用性,包括随机翻转、顺序排列和分支;因此突出了通过随机翻转在边水平上纳入可变性的影响。
不过,在不同任务中,研究发现TS2的准确率高于TS1,即使TS1因随机翻转而产生了更多变化。
这表明,虽然扰动有助于结构泛化,但过度的扰动可能会阻碍结构泛化。
使用公理训练从相关性推断因果关系
接下来,作者研究这种能力是否可以转移到其他因果任务上。
为此,研究人员将公理化训练应用于一个任务,该任务是从观察数据中的相关性陈述推断因果关系。
如图5所示,每个数据实例包括用自然语言描述的3到6个节点图的相关关系;目标是推断假设的真值,判断任何给定节点之间是否存在直接或间接关系,以及可能存在的碰撞节点和混杂因素。

这个任务比应用传递性公理要困难得多。
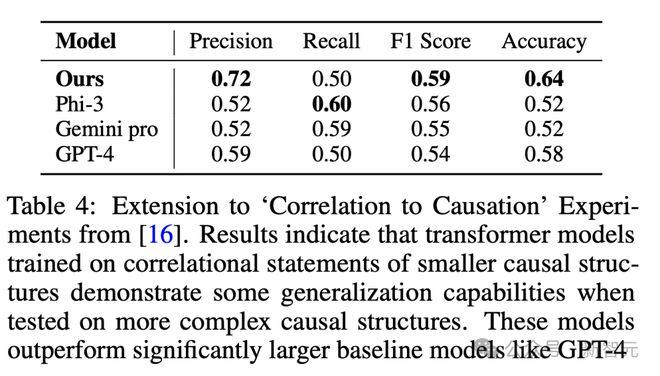
由于任务的复杂性,结果发现像Gemini Pro、Phi-3这样的预训练模型的表现与随机猜测相似(准确率为52%)。
虽然GPT-4的表现稍好一些,但其性能仍然较低(准确率为58%)。
值得注意的是,研究者的小型Transformer模型表现优于所有基线模型,准确率达到64%,比GPT-4高出6%。
通过进一步探索不同的训练设置,公理化训练的Transformer模型可能会在这类因果推理任务上得到进一步的优化。
总的来说,研究人员认为公理化训练是教Transformer模型学习因果关系的一种很有前景的方法。
受Judea Pearl愿景的启发,这项工作代表着一个潜在的新科学前沿——因果关系研究和语言模型的交叉点上。
文章内容仅供阅读,不构成投资建议,请谨慎对待。投资者据此操作,风险自担。

奥维云网(AVC)推总数据显示,2024年1-9月明火炊具线上零售额94.2亿元,同比增加3.1%,其中抖音渠道表现优异,同比有14%的涨幅,传统电商略有下滑,同比降低2.3%。

“以前都要去窗口办,一套流程下来都要半个月了,现在方便多了!”打开“重庆公积金”微信小程序,按照提示流程提交相关材料,仅几秒钟,重庆市民曾某的账户就打进了21600元。

华硕ProArt创艺27 Pro PA279CRV显示器,凭借其优秀的性能配置和精准的色彩呈现能力,为您的创作工作带来实质性的帮助,双十一期间低至2799元,性价比很高,简直是创作者们的首选。


