ЎЎЎЎЗ°СФЈә
ЎЎЎЎІ»КЗЧцКэІЦөДЈ¬ө«КЗТІРиТӘБЛҪвКэІЦөДЦӘК¶ЎЈ
ЎЎЎЎЖдКө·ЦІгәГ¶аТтИЛ¶шТмЈ¬ОКБЛН¬КВәГ¶а·ЦІгөДЗшұрТІІ»КЗәЬЗеОъЎЈ
ЎЎЎЎЛщТФәуРшУР»ъ»б»№КЗёъКэІЦөДН¬КВЕцТ»ПВ°Й~
ЎЎЎЎТ». ёчЦЦГыҙКҪвКН
ЎЎЎЎ1.1 ODSКЗКІГҙ?
ЎЎЎЎODSІгЧоәГАнҪвЈ¬»щұҫЙПҫНКЗКэҫЭҙУФҙұнАӯ№эАҙЈ¬ҪшРРetlЈ¬ұИИзmysql УіЙдөҪhiveЈ¬ДЗГҙөҪБЛhiveАпГжҫНКЗodsІгЎЈ
ЎЎЎЎODS И«іЖКЗ Operational Data StoreЈ¬ІЩЧчКэҫЭҙжҙў.“ГжПтЦчМвөД”Ј¬КэҫЭФЛУӘІгЈ¬ТІҪРODSІгЈ¬КЗЧоҪУҪьКэҫЭФҙЦРКэҫЭөДТ»ІгЈ¬КэҫЭФҙЦРөДКэҫЭЈ¬ҫӯ№эійИЎЎўПҙҫ»Ўўҙ«КдЈ¬ТІҫНЛөҙ«ЛөЦРөД ETL Ц®әуЈ¬Ч°ИлұҫІгЎЈұҫІгөДКэҫЭЈ¬ЧЬМеЙПҙу¶аКЗ°ҙХХФҙН·ТөОсПөНіөД·ЦАа·ҪКҪ¶ш·ЦАаөДЎЈө«КЗЈ¬ХвТ»ІгГжөДКэҫЭИҙІ»өИН¬УЪФӯКјКэҫЭЎЈФЪФҙКэҫЭЧ°ИлХвТ»ІгКұЈ¬ТӘҪшРРЦоИзИҘФл(АэИзУРТ»МхКэҫЭЦРИЛөДДкБдКЗ 300 ЛкЈ¬ХвЦЦКфУЪТміЈКэҫЭЈ¬ҫНРиТӘМбЗ°ЧцТ»Р©ҙҰАн)ЎўИҘЦШ(АэИзФЪёцИЛЧКБПұнЦРЈ¬Н¬Т» ID ИҙУРБҪМхЦШёҙКэҫЭЈ¬ФЪҪУИлөДКұәтРиТӘЧцТ»ІҪИҘЦШ)ЎўЧЦ¶ОГьГы№ж·¶өИТ»ПөБРІЩЧчЎЈ
ЎЎЎЎ1.2 КэҫЭІЦҝвІгDW?
ЎЎЎЎКэҫЭІЦҝвІг(DW)Ј¬КЗКэҫЭІЦҝвөДЦчМе.ФЪХвАпЈ¬ҙУ ODS ІгЦР»сөГөДКэҫЭ°ҙХХЦчМвҪЁБўёчЦЦКэҫЭДЈРНЎЈХвТ»ІгәНО¬¶ИҪЁДЈ»бУРұИҪПЙоөДБӘПөЎЈ
ЎЎЎЎПё·ЦЈә
ЎЎЎЎКэҫЭГчПёІгЈәDWD(Data Warehouse Detail)
ЎЎЎЎКэҫЭЦРјдІгЈәDWM(Data WareHouse Middle)
ЎЎЎЎКэҫЭ·юОсІгЈәDWS(Data WareHouse Servce)
ЎЎЎЎ1.2.1 DWDГчПёІг?
ЎЎЎЎГчПёІг(ODS, Operational Data Store,DWD: data warehouse detail)
ЎЎЎЎёЕДоЈәКЗКэҫЭІЦҝвөДПёҪЪКэҫЭІгЈ¬КЗ¶ФSTAGEІгКэҫЭҪшРРіБөнЈ¬јхЙЩБЛійИЎөДёҙФУРФЈ¬Н¬КұODS/DWDөДРЕПўДЈРНЧйЦҜЦчТӘЧсСӯЖуТөТөОсКВОсҙҰАнөДРОКҪЈ¬Ҫ«ёчёцЧЁТөКэҫЭҪшРРјҜЦРЈ¬ГчПёІгёъstageІгөДБЈ¶ИТ»ЦВЈ¬КфУЪ·ЦОцөД№«№ІЧКФҙ
ЎЎЎЎКэҫЭЙъіЙ·ҪКҪЈәІҝ·ЦКэҫЭЦұҪУАҙЧФkafkaЈ¬Іҝ·ЦКэҫЭОӘҪУҝЪІгКэҫЭУлАъК·КэҫЭәПіЙЎЈ
ЎЎЎЎХвёцstageІгІ»КЗәЬЗеОъ
ЎЎЎЎ1.2.2 DWM Зб¶И»гЧЬІг(MID»тDWB, data warehouse basis)
ЎЎЎЎёЕДоЈәЗб¶И»гЧЬІгКэҫЭІЦҝвЦРDWDІгәНDMІгЦ®јдөДТ»ёц№э¶ЙІгҙОЈ¬КЗ¶ФDWDІгөДЙъІъКэҫЭҪшРРЗб¶ИЧЫәПәН»гЧЬНіјЖ(ҝЙТФ°СёҙФУөДЗеПҙЈ¬ҙҰАн°ьә¬Ј¬ИзёщҫЭPVИХЦҫЙъіЙөД»б»°КэҫЭ)ЎЈЗб¶ИЧЫәПІгУлDWDөДЦчТӘЗшұрФЪУЪ¶юХЯөДУҰУГБмУтІ»Н¬Ј¬DWDөДКэҫЭАҙФҙУЪЙъІъРНПөНіЈ¬ІўОҙВъТвТ»Р©І»ҝЙФӨјыөДРиЗу¶шҪшРРіБөн;Зб¶ИЧЫәПІгФтГжПт·ЦОцРНУҰУГҪшРРПёБЈ¶ИөДНіјЖәНіБөн
ЎЎЎЎКэҫЭЙъіЙ·ҪКҪЈәУЙГчПёІг°ҙХХТ»¶ЁөДТөОсРиЗуЙъіЙЗб¶И»гЧЬұнЎЈГчПёІгРиТӘёҙФУЗеПҙөДКэҫЭәНРиТӘMRҙҰАнөДКэҫЭТІҫӯ№эҙҰАнәуҪУИлөҪЗб¶И»гЧЬІгЎЈ
ЎЎЎЎИХЦҫҙжҙў·ҪКҪЈәДЪұнЈ¬parquetОДјюёсКҪЎЈ
ЎЎЎЎИХЦҫЙҫіэ·ҪКҪЈәіӨҫГҙжҙўЎЈ
ЎЎЎЎұнschemaЈәТ»°г°ҙМмҙҙҪЁ·ЦЗшЈ¬Г»УРКұјдёЕДоөД°ҙҫЯМеТөОсСЎФс·ЦЗшЧЦ¶ОЎЈ
ЎЎЎЎҝвУлұнГьГыЎЈҝвГыЈәdwb,ұнГыЈәіхІҪҝјВЗёсКҪОӘЈәdwbИХЖЪТөОсұнГы,ҙэ¶ЁЎЈ
ЎЎЎЎҫЙКэҫЭёьРВ·ҪКҪЈәЦұҪУёІёЗ
ЎЎЎЎ1.2.3 DWS ЦчМвІг(DMЈ¬data market»тDWS, data warehouse service)
ЎЎЎЎёЕДоЈәУЦіЖКэҫЭјҜКР»тҝнұнЎЈ°ҙХХТөОс»®·ЦЈ¬ИзБчБҝЎў¶©өҘЎўУГ»§өИЈ¬ЙъіЙЧЦ¶ОұИҪП¶аөДҝнұнЈ¬УГУЪМṩәуРшөДТөОсІйСҜЈ¬OLAP·ЦОцЈ¬КэҫЭ·Ц·ўөИЎЈ
ЎЎЎЎКэҫЭЙъіЙ·ҪКҪЈәУЙЗб¶И»гЧЬІгәНГчПёІгКэҫЭјЖЛгЙъіЙЎЈ
ЎЎЎЎИХЦҫҙжҙў·ҪКҪЈәК№УГimpalaДЪұнЈ¬parquetОДјюёсКҪЎЈ
ЎЎЎЎИХЦҫЙҫіэ·ҪКҪЈәіӨҫГҙжҙўЎЈ
ЎЎЎЎұнschemaЈәТ»°г°ҙМмҙҙҪЁ·ЦЗшЈ¬Г»УРКұјдёЕДоөД°ҙҫЯМеТөОсСЎФс·ЦЗшЧЦ¶ОЎЈ
ЎЎЎЎҝвУлұнГьГыЎЈҝвГыЈәdm,ұнГыЈәіхІҪҝјВЗёсКҪОӘЈәdmИХЖЪТөОсұнГы,ҙэ¶ЁЎЈ
ЎЎЎЎҫЙКэҫЭёьРВ·ҪКҪЈәЦұҪУёІёЗ
ЎЎЎЎ1.3 APP?
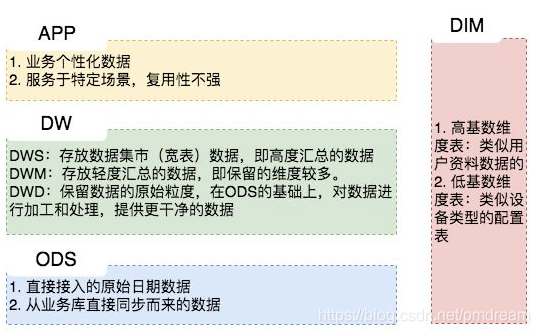
ЎЎЎЎКэҫЭІъЖ·Іг(APP)Ј¬ХвТ»ІгКЗМṩОӘКэҫЭІъЖ·К№УГөДҪб№ыКэҫЭЎЈ
ЎЎЎЎЦчТӘКЗМṩёшКэҫЭІъЖ·әНКэҫЭ·ЦОцК№УГөДКэҫЭЈ¬Т»°г»бҙж·ЕФЪ ESЎўMysql өИПөНіЦР№©ПЯЙППөНіК№УГЈ¬ТІҝЙДЬ»бҙжФЪ Hive »тХЯ Druid ЦР№©КэҫЭ·ЦОцәНКэҫЭНЪҫтК№УГЎЈ
ЎЎЎЎИзОТГЗҫӯіЈЛөөДұЁұнКэҫЭЈ¬»тХЯЛөДЗЦЦҙуҝнұнЈ¬Т»°гҫН·ЕФЪХвАпЎЈ
ЎЎЎЎУҰУГІг(App)
ЎЎЎЎёЕДоЈәУҰУГІгКЗёщҫЭТөОсРиТӘЈ¬УЙЗ°ГжИэІгКэҫЭНіјЖ¶шіцөДҪб№ыЈ¬ҝЙТФЦұҪУМṩІйСҜХ№ПЦЈ¬»төјИлЦБMysqlЦРК№УГЎЈ
ЎЎЎЎКэҫЭЙъіЙ·ҪКҪЈәУЙГчПёІгЎўЗб¶И»гЧЬІгЈ¬КэҫЭјҜКРІгЙъіЙЈ¬Т»°гТӘЗуКэҫЭЦчТӘАҙФҙУЪјҜКРІгЎЈ
ЎЎЎЎИХЦҫҙжҙў·ҪКҪЈәК№УГimpalaДЪұнЈ¬parquetОДјюёсКҪЎЈ
ЎЎЎЎИХЦҫЙҫіэ·ҪКҪЈәіӨҫГҙжҙўЎЈ
ЎЎЎЎұнschemaЈәТ»°г°ҙМмҙҙҪЁ·ЦЗшЈ¬Г»УРКұјдёЕДоөД°ҙҫЯМеТөОсСЎФс·ЦЗшЧЦ¶ОЎЈ
ЎЎЎЎҝвУлұнГьГыЎЈҝвГыЈәФЭ¶ЁaplЈ¬БнНвёщҫЭТөОсІ»Н¬Ј¬І»ПЮ¶ЁТ»¶ЁТӘТ»ёцҝвЎЈ(ЖдКөҫНҪРapp_)ҫНәГБЛ
ЎЎЎЎҫЙКэҫЭёьРВ·ҪКҪЈәЦұҪУёІёЗЎЈ
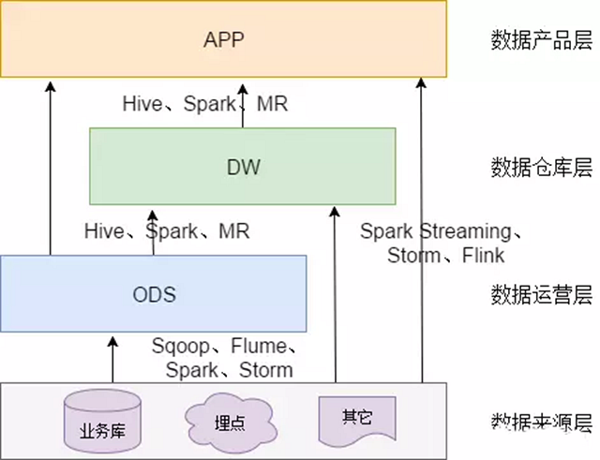
ЎЎЎЎ1.4 КэҫЭөДАҙФҙ
ЎЎЎЎКэҫЭЦчТӘ»бУРБҪёцҙуөДАҙФҙЈә
ЎЎЎЎТөОсҝвЈ¬ХвАпҫӯіЈ»бК№УГ Sqoop АҙійИЎ
ЎЎЎЎОТГЗТөОсҝвУГөДКЗdatabusАҙҪшРРҪУКХЈ¬ҙҰАнkafkaҫНәГБЛЎЈ
ЎЎЎЎФЪКөКұ·ҪГжЈ¬ҝЙТФҝјВЗУГ Canal јаМэ Mysql өД BinlogЈ¬КөКұҪУИлјҙҝЙЎЈ(УР»ъ»бІ№Т»ПВХвёцcanal)
ЎЎЎЎВсөгИХЦҫЈ¬ПЯЙППөНі»бҙтИлёчЦЦИХЦҫЈ¬ХвР©ИХЦҫТ»°гТФОДјюөДРОКҪұЈҙжЈ¬ОТГЗҝЙТФСЎФсУГ Flume ¶ЁКұійИЎЈ¬ТІҝЙТФУГУГ Spark Streaming »тХЯ Storm АҙКөКұҪУИлЈ¬өұИ»Ј¬Kafka ТІ»бКЗТ»ёц№ШјьөДҪЗЙ«ЎЈ
ЎЎЎЎ»№УРК№УГfilebeatКХјҜИХЦҫЈ¬ҙтөҪkafkaЈ¬И»әуҙҰАнИХЦҫ
ЎЎЎЎЧўТвЈә ФЪХвІгЈ¬АнУҰІ»КЗјтөҘөДКэҫЭҪУИлЈ¬¶шКЗТӘҝјВЗТ»¶ЁөДКэҫЭЗеПҙЈ¬ұИИзТміЈЧЦ¶ОөДҙҰАнЎўЧЦ¶ОГьГы№ж·¶»ҜЎўКұјдЧЦ¶ОөДНіТ»өИЈ¬Т»°гХвР©әЬИЭТЧ»бұ»әцВФЈ¬ө«КЗИҙЦБ№ШЦШТӘЎЈМШұрКЗәуЖЪОТГЗЧцёчЦЦМШХчЧФ¶ҜЙъіЙөДКұәтЈ¬»бК®·ЦУРУГЎЈ
ЎЎЎЎ1.5 ODSЎўDW → AppІг
ЎЎЎЎХвАпГжТІЦчТӘ·ЦБҪЦЦАаРНЈә
ЎЎЎЎГҝИХ¶ЁКұИООсРНЈәұИИзОТГЗөдРНөДИХјЖЛгИООсЈ¬ГҝМмБиіҝЛгЗ°Т»МмөДКэҫЭЈ¬ФзЙПЖрАҙҝҙұЁұнЎЈ ХвЦЦИООсҫӯіЈК№УГ HiveЎўSpark »тХЯЙъЯЈ MR іМРтАҙјЖЛгЈ¬ЧоЦХҪб№ыРҙИл HiveЎўHbaseЎўMysqlЎўEs »тХЯ Redis ЦРЎЈ
ЎЎЎЎКөКұКэҫЭЈәХвІҝ·ЦЦчТӘКЗёчЦЦКөКұөДПөНіК№УГЈ¬ұИИзОТГЗөДКөКұНЖјцЎўКөКұУГ»§»ӯПсЈ¬Т»°гОТГЗ»бУГ Spark StreamingЎўStorm »тХЯ Flink АҙјЖЛгЈ¬Чоәу»бВдИл EsЎўHbase »тХЯ Redis ЦРЎЈ
ЎЎЎЎ1.6 О¬ұнІгDIM?
ЎЎЎЎО¬ұнІг(Dimension)
ЎЎЎЎЧоәуІ№ідТ»ёцО¬ұнІгЈ¬О¬ұнІгЦчТӘ°ьә¬БҪІҝ·ЦКэҫЭЈә
ЎЎЎЎёЯ»щКэО¬¶ИКэҫЭЈәТ»°гКЗУГ»§ЧКБПұнЎўЙМЖ·ЧКБПұнАаЛЖөДЧКБПұнЎЈКэҫЭБҝҝЙДЬКЗЗ§Нтј¶»тХЯЙПТЪј¶ұрЎЈ
ЎЎЎЎөН»щКэО¬¶ИКэҫЭЈәТ»°гКЗЕдЦГұнЈ¬ұИИзГ¶ҫЩЦө¶ФУҰөДЦРОДә¬ТеЈ¬»тХЯИХЖЪО¬ұнЎЈКэҫЭБҝҝЙДЬКЗёцО»Кэ»тХЯјёЗ§јёНтЎЈ
ЎЎЎЎ1.7 Ігј¶өДјтөҘ·ЦІгНј
ЎЎЎЎјыПВНјЈ¬¶ФDWDІгФЪҪшРРјУ№ӨөД»°Ј¬ҫНКЗDWMІг(MIDІг)(ОТГЗөДКэІЦ»№КЗУРәЬ¶аdwmІгөД)
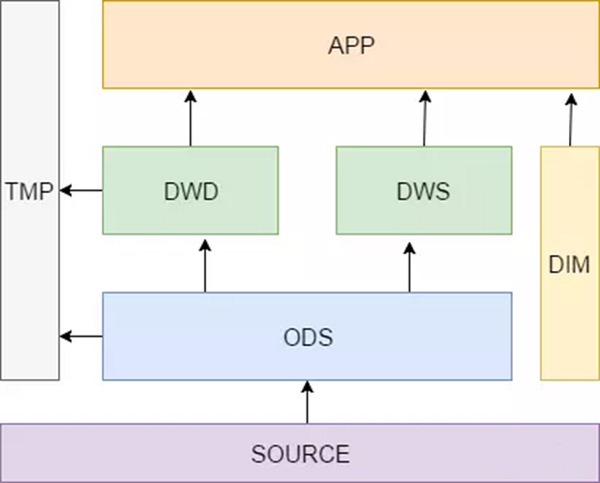
ЎЎЎЎХвАпҪвКНТ»ПВDWSЎўDWDЎўDIMәНTMPөДЧчУГЎЈ
ЎЎЎЎDWSЈәЗб¶И»гЧЬІгЈ¬ҙУODSІгЦР¶ФУГ»§өДРРОӘЧцТ»ёціхІҪөД»гЧЬЈ¬ійПуіцАҙТ»Р©НЁУГөДО¬¶ИЈәКұјдЎўipЎўidЈ¬ІўёщҫЭХвР©О¬¶ИЧцТ»Р©НіјЖЦөЈ¬ұИИзУГ»§ГҝёцКұјд¶ОФЪІ»Н¬өЗВјip№әВтөДЙМЖ·КэөИЎЈХвАпЧцТ»ІгЗб¶ИөД»гЧЬ»бИГјЖЛгёьјУөДёЯР§Ј¬ФЪҙЛ»щҙЎЙПИз№ыјЖЛгҪц7МмЎў30МмЎў90МмөДРРОӘөД»°»бҝмәЬ¶аЎЈОТГЗПЈНы80%өДТөОс¶јДЬНЁ№эОТГЗөДDWSІгјЖЛгЈ¬¶шІ»КЗODSЎЈ
ЎЎЎЎDWDЈәХвТ»ІгЦчТӘҪвҫцТ»Р©КэҫЭЦКБҝОКМвәНКэҫЭөДНкХы¶ИОКМвЎЈұИИзУГ»§өДЧКБПРЕПўАҙЧФУЪәЬ¶аІ»Н¬ұнЈ¬¶шЗТҫӯіЈіцПЦСУіЩ¶ӘКэҫЭөИОКМвЈ¬ОӘБЛ·ҪұгёчёцК№УГ·ҪёьәГөДК№УГКэҫЭЈ¬ОТГЗҝЙТФФЪХвТ»ІгЧцТ»ёцЖБұОЎЈ(»гЧЬ¶аёцұн)
ЎЎЎЎDIMЈәХвТ»ІгұИҪПөҘҙҝЈ¬ҫЩёцАэЧУҫНГч°ЧЈ¬ұИИз№ъјТҙъВләН№ъјТГыЎўөШАнО»ЦГЎўЦРОДГыЎў№ъЖмНјЖ¬өИРЕПўҫНҙжФЪDIMІгЦРЎЈ
ЎЎЎЎTMPЈәГҝТ»ІгөДјЖЛг¶ј»бУРәЬ¶аБЩКұұнЈ¬ЧЁЙиТ»ёцDWTMPІгАҙҙжҙўОТГЗКэҫЭІЦҝвөДБЩКұұнЎЈ
ЎЎЎЎ¶ю. ОКМв
ЎЎЎЎ2.1 DWS Ул DWD?
ЎЎЎЎОКҙрТ»Јә dws әН dwd өД№ШПө
ЎЎЎЎОКЈәdws әНdwd КЗІўРР¶шІ»КЗПИәуЛіРт?
ЎЎЎЎҙрЈәІўРРөДЈ¬dw Іг
ЎЎЎЎОКЈәДЗЖдКө¶ФУЪН¬Т»ёцКэҫЭЈ¬ХвБҪёц№эіМКЗҙ®РРөД?
ЎЎЎЎҙрЈәdws »бЧц»гЧЬЈ¬dwd әН ods өДБЈ¶ИПаН¬Ј¬ХвБҪІгЦ®јдТІГ»УРТААөөД№ШПө
ЎЎЎЎОКЈә¶ФСҪЈ¬ДЗХвСщ dws АпГжөД»гЧЬГ»УРҫӯ№эКэҫЭЦКБҝәННкХы¶ИөДҙҰАнЈ¬»тХЯөҘ¶АЧцБЛХвЦЦЦКБҝПа№ШөДҙҰАнЈ¬ОӘКІГҙІ»ФЪ dwd Ц®ЙПФЩЧц»гЧЬДШ?ОТөДТЙОКЖдКөҫНКЗЈ¬dwsөДЗб¶И»гЧЬКэҫЭҪб№ыЈ¬УРГ»УРЧцКэҫЭЦКБҝөДҙҰАн?
ЎЎЎЎҙрЈәods ЦұҪУөҪ dws ҫНәГЈ¬Г»ұШТӘ№э dwdЈ¬ОТҫЩёцАэЧУЈ¬ДгөДдҜААЙМЖ·РРОӘЈ¬ОТЧцТ»ІгЗб¶И»гЧЬЈ¬ҫНЦұҪУ·ЕФЪ dws БЛЎЈө«КЗДгөДЧКБПұнЈ¬ТӘҙУәГ¶аұнҙХіЙТ»·ЭЈ¬ОТГЗҙУЛДОе·ЭёцИЛЧКБПұнЦРҙХіцАҙБЛТ»·ЭНкХыөДЧКБПұн·ЕФЪБЛ dwd ЦРЎЈИ»әуФЪ app ІгЈ¬ОТГЗТӘіцТ»ХЕ»ӯПсұнЈ¬°ьә¬УГ»§ЧКБПәНУГ»§ҪьТ»ДкөДРРОӘЈ¬ОТГЗҫНЦұҪУҙУdwdЦРДГЧКБПЈ¬ И»әуФЩФЪ dws өД»щҙЎЙПЧцТ»ІгНіјЖЈ¬ҫНіЙТ»ёцappұнБЛЎЈөұИ»Ј¬ХвІ»КЗҫш¶ФЈ¬dws әН dwd УРГ»УРТААө№ШПөЦчТӘҝҙУРГ»УРХвЦЦРиЗуЎЈ
ЎЎЎЎ2.2 ODSУлDWDЗшұр?
ЎЎЎЎОКЈә»№КЗІ»М«Гч°Ч ods әН dwd ІгөДЗшұрЈ¬УРБЛ ods ІгәуёРҫх dwd Г»УРКІГҙУГБЛЎЈ
ЎЎЎЎҙрЈәаЕЈ¬ОТКЗХвСщАнҪвөДЈ¬ХҫФЪТ»ёцАнПлөДҪЗ¶ИАҙҪІЈ¬Из№ы ods ІгөДКэҫЭҫН·ЗіЈ№жХыЈ¬»щұҫДЬВъЧгОТГЗҫшҙуІҝ·ЦөДРиЗуЈ¬ХвөұИ»КЗәГөДЈ¬ХвКұәт dwd ІгЖдКөТІГ»М«ҙуұШТӘЎЈ ө«КЗПЦКөЦРҪУҙҘөДЗйҝцКЗ ods ІгөДКэҫЭәЬДСұЈЦӨЦКБҝЈ¬ұПҫ№КэҫЭөДАҙФҙ¶аЦЦ¶аСщЈ¬НЖЛН·ҪТІ»бУРЧФјәөДНЖЛНВЯјӯЈ¬ФЪХвЦЦЗйҝцПВЈ¬ОТГЗҫНРиТӘНЁ№э¶оНвөДТ»Іг dwd АҙЖБұОТ»Р©өЧІгөДІоТмЎЈ
ЎЎЎЎОКЈәОТҙуёЕГч°ЧБЛЈ¬КЗІ»КЗЛө dwd ЦчТӘКЗ¶Ф ods ІгЧцТ»Р©КэҫЭЗеПҙәН№ж·¶»ҜөДІЩЧчЈ¬dws ЦчТӘКЗ¶Ф ods ІгКэҫЭЧцТ»Р©Зб¶ИөД»гЧЬ?
ЎЎЎЎҙрЈә¶ФөДЈ¬ҝЙТФҙуЦВХвСщАнҪвЎЈ
ЎЎЎЎ2.3 appІгёЙКІГҙөД?
ЎЎЎЎОКҙрИэЈәapp ІгКЗёЙКІГҙөД?
ЎЎЎЎОКЈәёРҫхКэҫЭјҜКРІгКЗІ»КЗГ»өШ·Ҫ·ЕБЛЈ¬ёчёцТөОсөДКэҫЭјҜКРұнКЗУҰёГФЪ dwd »№КЗФЪ app?
ЎЎЎЎҙрЈәХвёцОКМвІ»М«әГ»ШҙрЈ¬ОТёРҫхЦчТӘҫНКЗГчИ·Т»ПВКэҫЭјҜКРІгКЗёЙКІГҙөДЈ¬Из№ыДгөДКэҫЭјҜКРІг·ЕөДҫНКЗТ»Р©ҝЙТФ№©ТөОс·ҪК№УГөДҝнұнұнЈ¬·ЕФЪ app ІгҫНРРЎЈИз№ыДгЛөөДКэҫЭјҜКРІгКЗТ»ёцұИҪП·әТ»өгөДёЕДоЈ¬ДЗГҙЖдКө dwsЎўdwdЎўapp ХвР©әПЖрАҙ¶јЛгКЗКэҫЭјҜКРөДДЪИЭЎЈ
ЎЎЎЎОКЈәДЗҙжөҪ RedisЎўES ЦРөДКэҫЭЛгКЗ appІгВр?
ЎЎЎЎҙрЈәЛгКЗөДЈ¬ОТёцИЛөДАнҪвЈ¬app ІгЦчТӘҙж·ЕТ»Р©Па¶ФіЙКмөДұнЈ¬ДЬ№©ТөОсІаК№УГөДЎЈХвР©ұнҝЙТФФЪ Hive ЦРЈ¬ТІҝЙТФКЗҙУ Hive өјИл Redis »тХЯ ES ХвЦЦІйСҜРФДЬұИҪПәГөДПөНіЦРЎЈ
ЎЎЎЎИэ. ЧЬҪб
ЎЎЎЎБнТ»ёцІ©ЦчөДНјВщәГЈә


ЎЎЎЎЦчМв(Subject)КЗФЪҪПёЯІгҙОЙПҪ«ЖуТөРЕПўПөНіЦРөДКэҫЭҪшРРЧЫәПЎў№йАаәН·ЦОцАыУГөДТ»ёційПуёЕДоЈ¬ГҝТ»ёцЦчМв»щұҫ¶ФУҰТ»ёцәк№ЫөД·ЦОцБмУтЎЈФЪВЯјӯТвТеЙПЈ¬ЛьКЗ¶ФУҰЖуТөЦРДіТ»әк№Ы·ЦОцБмУтЛщЙжј°өД·ЦОц¶ФПуЎЈАэИз“ПъКЫ·ЦОц”ҫНКЗТ»ёц·ЦОцБмУтЈ¬ТтҙЛХвёцКэҫЭІЦҝвУҰУГөДЦчМвҫНКЗ“ПъКЫ·ЦОц”ЎЈ
ЎЎЎЎОДХВДЪИЭҪц№©ФД¶БЈ¬І»№№іЙН¶ЧКҪЁТйЈ¬ЗлҪчЙч¶ФҙэЎЈН¶ЧКХЯҫЭҙЛІЩЧчЈ¬·зПХЧФөЈЎЈ

өЪК®ЛДҙъУўМШ¶ы® ҝбоЈ™ ҙҰАнЖч(ҙъәЕRaptor Lake S Refresh)ІЙУГБЛПИҪшөДIntel 7ЦЖіМ№ӨТХЎЈ

°ВО¬ФЖНш(AVC)НЖЧЬКэҫЭПФКҫЈ¬2024Дк1-9ФВГч»рҙ¶ҫЯПЯЙПБгКЫ¶о94.2ТЪФӘЈ¬Н¬ұИФцјУ3.1%Ј¬ЖдЦР¶¶ТфЗюөАұнПЦУЕТмЈ¬Н¬ұИУР14%өДХЗ·щЈ¬ҙ«НіөзЙМВФУРПВ»¬Ј¬Н¬ұИҪөөН2.3%ЎЈ

Ў°ТФЗ°¶јТӘИҘҙ°ҝЪ°мЈ¬Т»МЧБчіМПВАҙ¶јТӘ°лёцФВБЛЈ¬ПЦФЪ·Ҫұг¶аБЛ!ЎұҙтҝӘЎ°ЦШЗ칫»эҪрЎұОўРЕРЎіМРтЈ¬°ҙХХМбКҫБчіММбҪ»Па№ШІДБПЈ¬ҪцјёГлЦУЈ¬ЦШЗмКРГсФшДіөДХЛ»§ҫНҙтҪшБЛ21600ФӘЎЈ

»ӘЛ¶ProArtҙҙТХ27 Pro PA279CRVПФКҫЖчЈ¬ЖҫҪиЖдУЕРгөДРФДЬЕдЦГәНҫ«ЧјөДЙ«ІКіКПЦДЬБҰЈ¬ОӘДъөДҙҙЧч№ӨЧчҙшАҙКөЦКРФөД°пЦъЈ¬Л«К®Т»ЖЪјдөНЦБ2799ФӘЈ¬РФјЫұИәЬёЯЈ¬јтЦұКЗҙҙЧчХЯГЗөДКЧСЎЎЈ

9ФВ14ИХЈ¬2024И«Зт№ӨТө»ҘБӘНшҙу»бЎӘЎӘ№ӨТө»ҘБӘНшұкК¶ҪвОцЧЁМвВЫМіФЪЙтСфіЙ№ҰҫЩ°мЎЈ

·ө»ШЦчТі ©® №ШУЪОТГЗ ©® ДЪИЭБӘПө ©® БӘПөОТГЗ ©® ГвФрЙщГч ©® ФӯҙҙРВОЕ ©® ГЕ»§°ж
Copyright www.citnews.com.cn ЦРОДҝЖјјЧКС¶ 2009-2025 all rights reserved
№ШјьҙКЈәCITNews|CitnewsЦРОДҝЖјјЧКС¶|ЦРОДҝЖјјЧКС¶Нш|ҝЖјјЧКС¶Нш|ЦР№ъҝЖјјЧКС¶|ЦР№ъҝЖјјРВОЕНш|ЦР№ъҝЖјјЧКС¶Нш|ҝмҝЖјј|РВҝЖјј|ЦРОДҝЖјјКэВлН·МхәЕ|ЦРОДТЖ¶ҜРВГҪМе