�����������������������Լ������չ���ı���������������ķ�ʽ�����罻������Ƕ�����������������˸��ߵ�Ҫ��
������ǰ����51CTO�����AISummitȫ���˹����ܼ�������ϣ�Soul�����㷨�������������������������ݽ���Soul������������ʵ��֮·����������Soul��һЩҵ����������Soul����������������һЩʵ�����顣
�����ֽ��ݽ������������£�ϣ���Դ������������
����Soul������Ӧ�ó���
����Soul��һ��������Ȥͼ���Ƽ��ľ��г����е��罻����������������£����������dz��࣬�����ڹ�ȥһ��ʱ������˺ܶ�����ݡ�Ŀǰ���һ�����ϰ���Сʱ�����������ȥ��������ͨ�����е�һЩ�����������ȵȣ�ֻͳ����Щ���������ƵƬ�εĻ������������������ƵƬ�Ρ�Soul������ҵ�������Ҫ�����¼�����
���������ɶ�
����Ⱥ����Դ������䣬�ܶ��û�����������������졣
������Ƶ�ɶ�
����Soulƽ̨���û�����ʵ���Dz�ϣ��¶���ģ���ϣ����¶�Լ��ģ��������Ǿ�����һ�����е�3D��Avatar�������ͷ���û�ʹ�ã������û����õ�ȥ�����Լ���������ѹ���ı����Լ���
��������ɱ��Ϸ
����Ҳ��һ�����䣬����Ҳ�����Ǻö���һ������Ϸ��
��������ƥ��
����һ���Ƚ�����ɫ�ij�������������ƥ�䣬����˵�����Ŵ�绰һ�������ǿ���һ��һ��ȥ���졣
����������Щ���������ǹ���������������������ҪΧ��������һ����Ȼ���˻��������ڶ����������������ɡ���Ҫ�ĸ����棺��һ������ʶ��������ϳ�;���������������������������ͼ�������õ��ij������������ߣ���Ҫ�������������������ʡ���Ч��������Щ����Ȼ��������ʶ�𣬱�������ʶ�𡢸���ʶ����Ӣ����������������ϳ���صģ���������ת��������ת���������ϳ���ص����顣������������������Ҫ������һЩ�����������Ρ������������εȵ�һЩ���������ļ�����
����������Щ�����㷨�����������кܶ�����Ӧ����ʽ���������������ļ�⣬������ǿ��������ˣ������������������⡢���������������Щ3D�Ŀռ���Ч�ȵȡ��������������˺�������������ҵ�����õ��ļ������н��ܡ�
���������������
�����������������ͨ������ƵƬ�ν���������ɫ�顢���������Щά�ȵ����ݽ��д��ǩ�������ǽ���ʶ��ͨ����ЩΥ���ǩ�ļ�����ˣ����������簲ȫ���������õ�������ĵļ������Ƕ˵�������ʶ�����������û�����Ƶת�����֣�Ȼ���ٸ����ε������Ա���ж����ʼ졣
�����˵��˵�����ʶ��ϵͳ
������ͼ������Ŀǰ����ʹ�õ�һ���˵�������ʶ���ܣ���������ץȡ�û���һ��Ƭ����Ƶ����������ȡ��Ŀǰ�õ��������кܶ࣬������Ҫ������Alfa-Bank��������һ���ֳ����³�������Wav2Letter����Ԥѵ���õ����������õ���Ƶ����֮������һ���˵��⣬���Ǽ��������Dz�����˵���������ƵƬ����û��������Ŀǰ�õ��Ļ�������һЩ���������VD��ģ��DNVD��
�����õ���Щ����֮�����ǻ��͵�һ����ѧ��ֵ�ģ�飬�����ѧģ�������ڿ�ʼ��ʱ�����õ�Transformer CDC��Ŀǰ�Ѿ���������Conformer CDC�����������ѧ���֮�����ǻ��һϵ�е����еķ������������������������������������������ʶ�����ٽ��ж��δ�֡�����������У������õ���ģ�ͻ����ϻ���һЩ���紫ͳ��EngelMģ�ͣ�����һЩĿǰ�Ƚ�������Transformer���ѧϰ��ģ�ͽ����ش�֡�������ǻ�����һ�����������羭��һЩ���ļ�⡢�ı��������˳������Щ���������յõ�һ��������ıȽ�ȷ��ʶ�����ֽ��������“2022��ȫ���˹����ܴ��”��
�����ڶ˵�������ʶ��ϵͳ���棬��ʵ���ǽ��Ķ˵�����Ҫ������ѧ����ⲿ��������ʹ���˶˵��˼�������������Ҫ����һЩ��ͳ�ĺ�һЩ��������ѧϰ��ʽ��
�����ڹ����������ϵͳ�����У�����ʵ�����������˺ܶ����⣬��������Ҫ���о�������
�����мල��ѧ����̫�� ��Ҳ�Ǵ��ͨ�������������顣��Ҫԭ����ǣ�һ����Ƶ�����Ҫ�������������ע���ڶ������ı�ע�ɱ�Ҳ�Ƿdz��ߵġ������ⲿ����������һ����Ҷ����Ե����⡣
����ģ��ʶ��Ч���� ����кܶ�ԭ��һ���DZ�������Ӣ������߶������ʱ����ͨ��ģ��ȥʶ��������ڱȽϲ������
����ģ���ٶ���
��������⼸�����⣬������Ҫ��ͨ������������ʽȥ����ġ�
��������Ԥ����
����Soul�ij������ұȽϸ��ӡ�����Ⱥ���ɶԣ�������ֶ���˽������������ABһֱ�ڶԻ�������������KTV���������һЩ�߳����˵������������������ڱ�ע���ݵ�ʱ����Ϊ���Ƚϰ����������ǻ�ѡȡ��Щ��������Ƚϸɾ������ݽ��б�ע��������ܻ��עһ��Сʱ�ɾ����ݡ����Ǹɾ������ݸ���ʵ���������ݵĸ������Dz�һ���ģ��������ǻ������Щ�ɾ�������һЩ����Ԥ����������һЩ����ļ��롢�ӻ��졢���٣��Ƚϰ��ٶȵ���һЩ���ߵ���һЩ��������������������СһЩ��������Щ�ȽϾ����һЩ����Ԥ������ʽ��
����������Щ��ʽ�����ǻ��������ҵ���³��ֵ�һЩ���⣬���ǻ���һЩ����Ե�����Ԥ���������������㡣����ղ��ᵽȺ���ɶԺ����׳��ֶ�˵���˽��������Σ��������ǻ���һ����˵����ƴ����Ƶ��Ҳ����˵��ABC����˵���˵���ƵƬ�����ǻ���һ��cut��һ��ȥ���������㡣
������Ϊ������Ƶͨ��������һЩ����������Ƶǰ����һЩ������3D�㷨��Ԥ�����������Զ��������������ܽ���ȵȣ�����˵����Ҳ��Ϊ���������ϵ�ʹ�ó���Ҳ����һЩ3D�㷨��Ԥ������
����������Щ��ʽ������Ԥ����֮�����ǿ��Եõ������Ե���Щ���ݣ�����������ġ���һЩ����ġ���������������������ݶ�������������������ǻ��һ��Сʱ����ɴ������Сʱ��������˾���Сʱ��ôһ�������������Ļ������ݵĸ��Ƕȡ���Ⱦͻ�dz��ߡ�
����ģ������
��������ʹ�õ�ģ�͵���Ҫ��ܻ���Conformer�ṹ�������Conformer�ṹ��߾��Ǿ����Encoder CDC��ܡ��ұ���һ��Attention Decoder�����Ǵ��ע����������ұ����Loss��ߣ�ԭ����Conformer�ṹ��һ��CE Loss����������߰���������Focal Loss����Ҫ��������ʹ��Focal Lossȥ���ϡ�赥Ԫ��ϡ������ѵ�������������⣬����ѵ��������⣬���ǿ��Խ���ġ�
������������Ӣ������棬��ЩӢ�ĵ���������ѵ�����������Ǻ��ٵģ���������������Ԫ��ѧ���õġ�ͨ��Focal Loss���ǿ�������LossȨ�ظ�����һЩ�����Ի���һ���������������ѵ�����õ����⣬�ܹ����һ����bad case��
�����ڶ����㣬������ѵ�������ϻһ��������������ѵ������Ҳ�����һЩ���ѵ���ķ�ʽ��������ǰ��ѵ����ʱ������ѵ��Decode�ⲿ�������ʱ�����ǻ��Dz��þ����Label����������Ϊ���롣��������ѵ��ģ�����������ڵ�ʱ�����ǻᰴ��һ������ȥ����һ����Ԥ�������Label��ΪDecoder�����룬����һЩTrick�����trick��Ҫ���ʲô?����ѵ��ģ����������ģ�͵�����������һ�µ�����ͨ�����ַ�ʽ�����ǿ��Խ��һ���ֵġ�
����������һ��������ǣ���ʵ�����Conformerģ��ԭ�����߱���Vnet����ESPnet�����ṩ��ģ�����棬Ĭ����һ������λ����Ϣ�����Ǿ���λ����Ϣ�����ܽ�����й�����ʱ���ʶ�����⣬�������ǻ�Ѿ���λ����Ϣ�ij����λ�ñ��������������⡣ͨ�����ַ�ʽ�����Խ��ʶ������г��ֵı���˵��Щ���ظ�������ż���Ķ��ֻ��߶��ʵ������������Ҳ�ǿ��Խ���ġ�
�����������ٶ�
������һ������ѧģ�ͣ����ǻ���Իع��ģ�ij����ֻ���Encoder CDC+WFST����ķ�ʽ���Ƚ��һ����ʶ����������NBest��10best����20best������20best�����ǻ��͵�Decorde Rescoreȥ��һ�������ش�֣������Ļ����Ա���ʱ�������Ĺ�ϵ������GPT���еĽ��м����������
�������˾�������ּ��ٵķ�ʽ�����ǻ����˻�������ķ�ʽ���������������ѧϰǰ�������Ĺ����У�����һ����ʹ��8Bit���м��㣬�����ں��ĵ�һ���֣�������ں����ⲿ��������Ȼʹ��16bit����Ҫ�����ٶȺ;��ȷ��������ǻ���һ���ʵ���ƽ�⡣
����������Щ�Ż�֮�����������ٶ��DZȽϿ�ġ����������ǵ�ʵ�����߹����У����ǻ�������һЩС���⣬�Ҿ���Ҳ����һ��Trick��
����������ģ�Ͳ����ϣ�������ģ�Ͳ����ϣ��������dz������ĵ��ı��Ƚ϶࣬����Ҳ�г���ģ�����Ҫͬһ��ģ�ͼ�Ҫ���˵������Ҫ���������������ģ�����棬���������ı�����ͨ���Ƚ��顢�Ƚ϶̣��������Ǿ���ʵ��֮�����Ƿ�����Ԫ���DZȽϺõģ���Ԫ����û�д���������
�������DZ�������Ļ��������ı��Ƚϳ��������ľ�ʽ���ķ���ԱȽϹ̶���������ʵ������У���Ԫ�DZ���Ԫ�õġ������������������ʹ�õ��ǻ���ķ����������ı������ı���ͬ��������ģ�͵Ľ�ģ��ʹ����“��Ԫ+��Ԫ”��ϵ�ģʽ�������“��Ԫ+��Ԫ”��ϲ��������Ǵ�ͳ������˵�IJ�ֵ�����Dz�û������ֵ�����ǰ����ĵ���Ԫ���ķ�����Ԫ�ĸ�������Ԫ���ķ��ù���ֱ����һ���ϲ�����ô�õ���arpaĿǰ�Ǹ�С�ģ��ڽ���Ĺ�����Ҳ�ȽϿ죬����Ҫһ������Դ�ռ�ñȽ�С����Ϊ��GPU�Ͻ���Ļ����Դ��С�ǹ̶��ġ�����˵��������Ҫ����һ��������ģ�ʹ�С������£���������ͨ������ģ������ʶ���Ч����
����������ѧģ�ͺ�����ģ�͵�һЩ�Ż���Trick֮��Ŀǰ���ǵ������ٶ�Ҳ�Ƿdz���ġ�ʵʱ�ʻ������ܵ�0.1��0.2��ˮƽ��
�����������
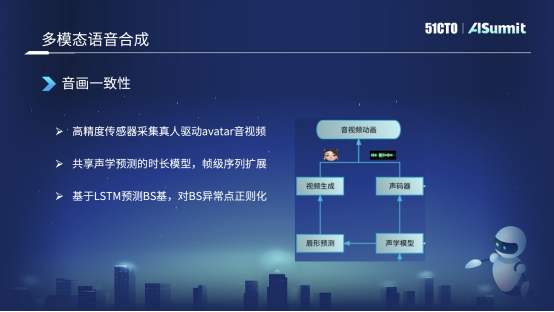
������Ҫ��ͨ�������������Ρ����顢��̬����Щ���ݽ������ɣ��������û�����ѹ�����߸���Ȼ�������ɵ�ȥ����ⱳ����Ҫ�ĺ��ļ���֮һ���Ƕ�ģ̬�����ϳɡ�
������ģ̬�����ϳ�
������ͼ��Ŀǰ����ʹ�õ������ϳ�ϵͳ�Ļ�����ܡ��������ǻ��ȡ�û����������֣�����“2022ȫ���˹����ܴ��”��Ȼ�����ǻ��͵��ı��������ģ�飬���ģ����Ҫ�Ƕ��ı�����һЩ������ķ�������������ı�����������һЩ�ִʣ�����Ҫһ������ת�ƣ�������ת�����أ�����һЩ����Ԥ��ȵȹ��ܡ���������ı�����֮�����ǾͿ����õ��û�����仰��һЩ����ѧ����������������͵���ѧģ�����档��ѧģ��Ŀǰ������Ҫ��ʹ�õĻ���FastSpeech����������һЩģ�͵ĸĽ���ѵ����
������ѧģ�͵õ���ѧ����������÷������������ʱ�����������ȵ���Ϣ���������������������֡�һ�������ǻ��͵����������棬��Ҫ�������������ǿ���������Ƶ���Ρ�����һ���������͵�����Ԥ�����棬����ͨ������Ԥ��ģ�����Ԥ������ζ�Ӧ��BSϵ�����õ�BS����ֵ֮�����ǻ��͵���Ƶ����ģ�飬�ⲿ�������Ӿ��ŶӸ��𣬿�����������ͷ���Ǵ����Ρ���������������������������ǻ������ͷ�����Ƶ����һ���ϲ���������������Ƶ���������������������ģ̬�����ϳɵĻ�����ܡ��������̡�
������ģ̬�����ϳɹ����е���Ҫ���⣺
���������������������Ƚϲ
�����ϳ����ʽϲ
���������ӳٴ��ͺ������Բ���
����Soul�Ĵ�����ʽ���ڸĽ��˵��˵�����ʶ��ϵͳ�����ơ�
��������Ԥ����
�������ǵ�������Դ�DZȽ϶�ģ�������ͼ���ǵ�һ���ǻ�ɼ�¼�ơ��ڶ�����Ȼ���Ƿdz���л��Դ�����ݹ�˾�����ῪԴһЩ���⣬����Ҳ����������һЩʵ�顣����������ƽ̨���ڹ�˾������һЩ������Ӫ����Ƶ��������Ƶ��ʱ������һЩ���������������������������ɫҲ�Ƿdz����ʵġ����ģ�һЩ�������������ݣ������ڶԻ��Ĺ����У���Щ��ɫ�����Ƚϸߣ���������Ҳ����ȡһЩ��Ȼ����һЩԤ��ע����Ҫ����һЩ�ڲ���ʵ���Ԥѵ����
���������Щ���ݸ����ԣ���������һЩ����Ԥ����������̾��ƴ�ӣ��ղ��ᵽ�ڲɼ��Ĺ����У��������г��ж̵ģ�����Ϊ�����������ʱ�������ǻ�Ѷ̾���һ��cut�����������ǻ�ȥ��һЩ����������̫���Ļ�Ҳ����һЩӰ�졣
�����ڶ�������ȥ�룬�������õ�����Щ�������ݻ���Ӫ����Ƶ������������������ǻ�ͨ��һЩ������ǿ�ķ�ʽ������ȥ����
������������ʵ���ڵı�ע���DZ�ע����ת�֣������صı߽����ڻ����ϾͲ���Ϊ��ע�ˣ���������ͨ����ͨ������MFAǿ�ƶ���ķ�ʽȥ������صı߽���Ϣ��
����Ȼ��������������Ļ��DZȽ�����ģ���Ϊ����Ӫ����Ƶ�����������б������֣�����˵���ǻ���һ���������룬��ѱ������ָ�ȥ������ȡ���������ݡ����ǻ���һЩ��������������һЩVAD��VAD��Ҫ���ڶԻ����������������棬��ͨ��VADȥ����Ч������������ȥ��һЩԤ��ע����Ԥѵ����
����ģ������
������������FastSpeech�Ĺ����У�������Ҫ������������ĸĶ���������ͼ�����һ����FastSpeech�Ļ���ģ�ͣ������������˵�һ���仯�������ǻ�����غ��������н��ģ��������������´�ҵ��ı�ǰ��ת���������������У���������ͼһ����“���”���ֵ������������С��������ǻ��������ұ��ⲿ�֣������֣��������һ�������������У�ֻ�����أ�û���������ұ���ֻ��������û�����ء������Ļ����ǻ�ֱ����͵�һ��ProNet(��)���棬��õ�����Embedding������Embedding��cut��һ�������֮ǰ������Embedding�ķ�ʽ�������Ļ����ô����������Խ��ϡ�跢�������⣬��������Щ�����������ǵ�ѵ���������棬���������ǻ����϶����Խ���ġ�
�����ڶ������ǸĶ��ķ�ʽ��ԭ���ķ�ʽ����Ԥ��һ��ʱ���������ұ����ͼ��Ȼ���ٻ������ʱ�����ǰ�������������չ��Ȼ��Ԥ��������Pitch�����������ǻ���һ��˳�����ǻ�������ؼ���ȥԤ��Pitch��Energy��Ȼ��Ԥ����֮�����DzŻ�ȥ��������һ��֡�����ʱ������չ�������ĺô����ǣ����������������صķ��������У����ķ����ͱȽ��ȶ������������dz����µ�һ���仯��
��������������������Decoder�ⲿ�֣������������ⲿ�֣�Decoder�ⲿ����������һ������仯��ԭ����Decoder�������õ�����Attention�ķ�ʽ���������ڻ���������Iconv����Convolution�ķ�ʽ������ô�������ΪSelf-Attention����Ȼ�ܲ����ǿ�����ʷ��Ϣ����������Ϣ�����Ƕ���ģ�������DZȽϲ�ġ�����˵����Convolution֮�������ڴ������־ֲ���ģ�����������һЩ�������ڷ�����ʱ�ղ��ᵽ�����ַ����Ƚ���������ģ���������������ǿ��Խ���ġ���������Ŀǰ��һЩ��Ҫ�ı仯��
����������ѧģ��
��������Ǻϳɿ��Σ��ұ��Ǻϳ����������ǹ�����ѧģ�������һЩEncoder��ʱ����Ϣ��
����������Ҫ������������������һ���ǣ���������ʵ�IJɼ���һЩ�߾��ȵ����ݣ��������ǻ���һЩ�������һЩ�߾��ȴ�������ȥ���������Ѿ�Ԥ��õ�Avatar���õ��߷ֱ��ʵ�����Ƶ����һЩ��ע�������ͻ�õ����֡���Ƶ����Ƶ������ͬ����һЩ���ݡ�
�����ڶ���������ǣ�����Ҳ�ᵽ������ô�������һ������?��Ϊ�����ʼ����ͨ���ϳɣ��ı��ϳ��������õ�����֮�����ǻ���һ�����������ε�Ԥ�⣬����������������֡���ԳƵ�����Ŀǰ������ͨ�����ֺϳɿ��κͺϳ�����������ѧģ�͵ķ�ʽ��������֡�����н�����չ֮��ȥ����Ŀǰ�ǿ��Ա�֤��֡�����ǿ��Զ���ģ��ܹ���֤����һ���ԡ�
�����������Ŀǰ��û�л������еķ�ʽȥԤ����λ���BS���������ǻ���LSTM�����ַ�ʽȥԤ��BS����Ԥ���BSϵ��֮�������п���Ԥ�����Щ�쳣�����ǻ�����һЩ������������������BS��̫�����̫С�����ᵼ�¿����ŵ�̫�������仯̫С�����Ƕ�������һ����Χ������̫���ˣ��������һ�������ķ�Χ֮�ڡ�Ŀǰ�������ǿ��Ա�֤����һ���Եġ�
����δ��չ��
����һ�Ƕ�ģ̬ʶ���ڸ�������£���Ƶ��Ͽ�������ģ̬ʶ�����ʶ��ȷ�ʡ�
�������Ƕ�ģ̬�������ϳ�ʵʱ����ת�������Ա����û�����С������Щ������ֻ�ǰ��û�����ɫת��������һ����ɫ���档
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
