ЎЎЎЎТэСФ
ЎЎЎЎФЖјЖЛгөДіцПЦОӘЖуТөөД№ЬАнЎўТөОсҝӘХ№ЎўЧКФҙХыәПөИҙшАҙБЛј«ҙуөДұгАыРФЈ¬ТІКЗКэЧЦ»ҜҪЁЙиөДәЛРД»щҪЁЦ®Т»ЎЈ¶шёЯҝЙУГРФәНОИ¶ЁРФКЗәвБҝТ»јТФЖ·юОсі§ЙМЧоәЛРДөДұкЧјЦ®Т»ЎЈ
ЎЎЎЎ»·РЕЧчОӘИ«ЗтБмПИөД»ҘБӘНшПыПўФЖ·юОсЙМЈ¬МṩȫГжSLA 99.95%өДИ«Зт№«УРФЖ·Ҫ °ёЈ¬ТФј°SLA99.99% өДИ«ЗтЧЁУРФЖ·Ҫ°ёЎЈИзәОЧцәГИ«ЗтНшВз·юОсЦ§іЕЈ¬№№ҪЁі¬өН СУКұөДSD-GMN НшВзЈ¬ұЈіЦИ«ЗтУГ»§100әБГлТФДЪөДЧојСУГ»§МеСйЎЈұҫҙОҪ«ПтДъҪІКц·юОсұіәуөДјјКх№ККВЈ¬°ьАЁ»·РЕИ«ЗтКөКұПыПўНшВзөДөДХыМе№ж»®ЎўФЛО¬јаІвәН·юОсЎўјјКхөьҙъТФј°іЦРшУЕ»ҜЎЈ

ЎЎЎЎДҝВј
ЎЎЎЎТ»ЎўИ«ЗтКөКұПыПўНшВзөДЦчТӘМфХҪ¶юЎў»·РЕИ«ЗтКөКұПыПўНшВзХыМе№ж»®ИэЎўФЛО¬јаІвәН·юОсЛДЎўУөұ§ұЯФөјЖЛгәНіЦРшөьҙъУЕ»ҜОеЎўҪбУп
ЎЎЎЎТ»ЎўИ«ЗтКөКұПыПўНшВзөДЦчТӘМфХҪ
ЎЎЎЎ»·РЕЧчОӘ№ъДЪЧоФзМṩȫЗтПыПўФЖ·юОсөДі§ЙМЈ¬ФЪМṩȫЗтКөКұПыПўНшВз·ҪГжГжБЩЦо¶аМфХҪЈ¬ ЦчТӘ°ьАЁРВРЛКРіЎ№ъјТ»щҙЎЙиК©ІоЎўСУКұёЯЈ¬ ТФј° DNS ҙнОуөИОКМвЎЈЖдЦРЈ¬ПыПўөДөҪҙпВКәНПыПўөДСУіЩКЗЧоЦШТӘөДәЛРДЦёұкЦ®Т»ЎЈ
ЎЎЎЎГж¶Ф№ъДЪУГ»§өДКұәтЈ¬»щУЪ№ъДЪөД 5G »щҙЎЙиК©өДБмПИРФЈ¬ПыПўСУіЩ»щұҫІ»ЛгОКМвЈ¬ №ъДЪХыМеНшВзСУКұХыМеҝЙҝШЎЈёщҫЭКэҫЭНіјЖПФКҫЈә“№ъДЪЧоВэөДЦШЗмКРКұСУЦРЦө 84msЈ¬ДЗКХ·ўПыПўөҘҙОНщ·өҫНКЗ 84msЈ¬ФЩјУЙПјёК®әБГлөД·юОсЖчҙҰАнКұјдЈ¬ХыМе КұјдҝШЦЖФЪ 100ms ЧуУТЈ¬УГ»§јёәхёРКЬІ»өҪСУіЩҙшАҙөДҪ»»ҘОКМвЎЈ”
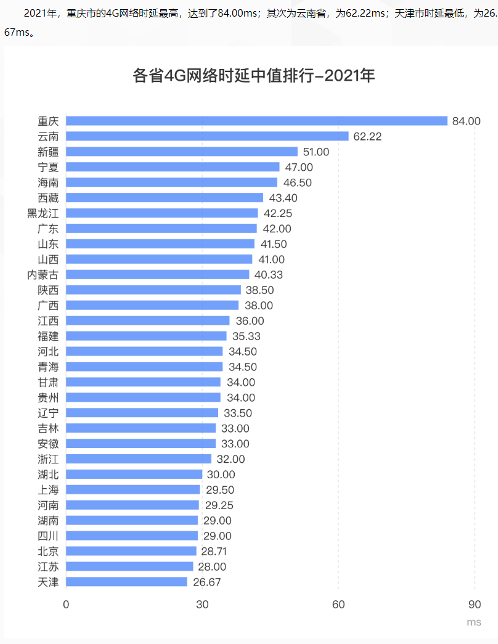
ЎЎЎЎТФЙПКэҫЭАҙЧФspeedtest.cn
ЎЎЎЎФзФЪ2014Дкөұ»·РЕПтәЈНвҝН»§Мṩ·юОсЦ®КұЈ¬КЬЦЖУЪ№ъНвНшВз»щҙЎЙиК©БјЭ¬І»ЖлЈ¬ ОТГЗ»б·ўПЦәЈНвөДХыМеНшВзСУіЩІоТмҫЮҙуЈ¬ОЮ·Ёёъ№ъДЪТ»СщНЁ№эІҝКр3ПЯЎў8 ПЯ bgp өД»ъ·ҝҫНДЬ»щұҫҝЙУГЈ¬»тХЯК№УГЧФјәФЬөД¶аПЯ»ъ·ҝ·Ҫ°ёЎЈ»·РЕИ«ЗтКөКұПыПў¶ЁТеОТГЗ КХ·ўөДПыПўГҝҙОСУКұ¶јКЗФЪ 1s ДЪЈ¬Т»ө©і¬№э 1s ОТГЗҫН»бёРҫхөҪУРГчПФөДСУіЩЎЈТтҙЛ ОТГЗөДДҝұкҫНКЗөҘёцҝН»§¶Л·ўЛНПыПўөҪҙп·юОсЖч¶ЛІ»ДЬі¬№э 100msЎЈЧоЦХХвёцОКМвҫНСЭұдіЙБЛОТГЗФЪГж¶ФәЈНвНшВзөДЗйҝцПВИзәОҪшРРҪвҫцҙҰАнАҙҙпөҪХвёцұкЧјЎЈ
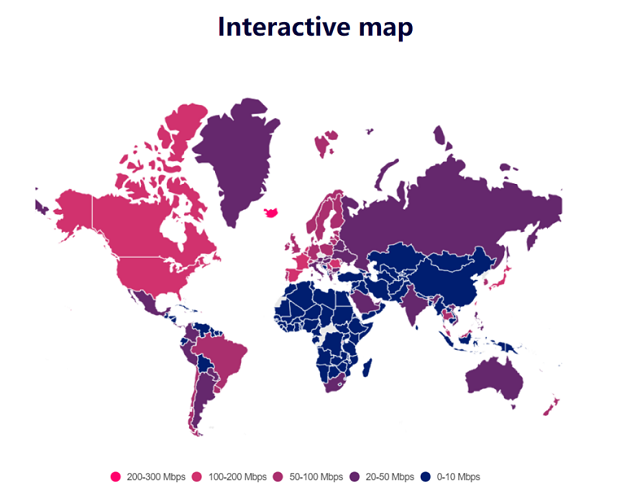
ЎЎЎЎТФЙПКэҫЭАҙЧФ
ЎЎЎЎhttps://www.cable.co.uk/broadband/world-wide-speed-league/2022/worldwide_speed_league_data.xlsx
ЎЎЎЎҙУЙПГжКэҫЭЛдИ»ОЮ·Ёҝҙіцёчёц№ъјТөДКЦ»ъНшВзСУКұЈ¬ТФј°УЙУЪДіР©№ъјТөДНшВзіцҝЪФӯ ТтөјЦВҪб№ыІўІ»НкИ«ЧјИ·Ј¬ө«КЗҙуМеЙПОТГЗҝЙТФҝҙіцАҙНшВзВэөД¶јКЗТ»Р©РВРЛКРіЎөД №ъјТәНөШЗшЎЈХвР©өШЗшЦчТӘКЗ·ЗЦЮЎўДПГАЎўЦРСЗТФј°ОчСЗөИөШЗшЎЈ
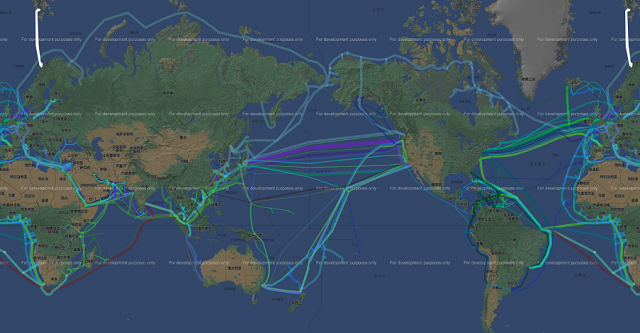
ЎЎЎЎОТГЗФЩАҙјЖЛгТ»ПВНшВзөДҙ«КдЛЩВКЈ¬УЙУЪ№ъјКНшВз»щұҫ¶јКЗ№вПЛАҙҪшРРҙ«өЭөДЎЈ№вПЛ СУКұјЖЛгЈәt=n*L/cЈ¬c ОӘ№вЛЩЈ¬ЖдЦР№вЛЩФјОӘ c=30 Нт№«Ап / Гл;№вПЛөДІДБПКЗ¶юСх »Ҝ№иЈ¬ЖдХЫЙдВК n ОӘ 1.44 ЧуУТЈ¬јЖЛгСУіЩөДКұәтҝЙТФҪьЛЖИПОӘ1.5ЎЈОТГЗУГХвёц№«КҪҝЙТФјЖЛгПВұұҫ©өҪЙПәЈөДСУіЩ:ЧоҝмҫНКЗ 11ms Нщ·өЎЈө«КЗКөјКЗйҝцҝЙДЬҫНКЗХвёцКэ ЧЦТӘіЛТФ 2»тіЛТФ 3өДКэЦөЎЈТтОӘХвАп»бУРёчёцВ·УЙҪЪөгөДЛрәДЈ¬ТФј°№вПЛҙУұұҫ©өҪ ЙПәЈҝЙДЬІўІ»КЗЦұПЯЈ¬¶шұИИзЦРГАәЈөЧ№вАВХвСщөДЈ¬УЙУЪУРұкЧўХыМеөДіӨ¶ИЈ¬ТтҙЛәЬ ИЭТЧјЖЛгХыМеСУКұЎЈ
ЎЎЎЎТФПВХвёцНшХҫКЗёщҫЭ Wikipedia ХыАнөДПЦФЪТСУРәНФЪҪЁөДәЈөЧ№вАВЎЈХвАпОТГЗҝЙТФұИ ҪПЗеіюөДҝҙөҪЈ¬ №ъјК№вАВЦчТӘКЗФЪСЗЦЮәНұұГАЦ®јдөДМ«ЖҪСуЈ¬ұұГАәНЕ·ЦЮЦ®јдөДҙуОч СуЎЈ(КэҫЭАҙФҙІОҝјНшЦ·Јә https://cablemap.info/_default.aspx )
ЎЎЎЎПЦФЪЈ¬ОТГЗТСҫӯХТөҪБЛәЛРДОКМвЈ¬Н¬Кұ¶ЁТеәГБЛДҝұкЈ¬ДЗҫНЯЈЖрРдЧУјУУНёЙ°Й!
ЎЎЎЎҙУТФЙПРЕПўЦРОТГЗҝЙТФҝҙөҪЈ¬ОТГЗРиТӘҪвҫцөДКЗИэёцОКМвЈә
ЎЎЎЎ- ёьҪьөДКэҫЭЦРРД
ЎЎЎЎ- ·З·ўҙп№ъјТөД Last mile УЕ»Ҝ
ЎЎЎЎ- В·ҫ¶СЎФс
ЎЎЎЎЧоәуОТГЗТІҪ«ҪйЙЬТ»ПВЙщНш»·РЕјҜНЕөДНшВз»щҙЎЙиК©ҫШХуЎЈ
ЎЎЎЎ¶юЎў»·РЕИ«ЗтКөКұПыПўНшВзХыМе№ж»®
ЎЎЎЎөЪТ»ЈәёьҪьөДКэҫЭЦРРД
ЎЎЎЎТтОӘЛщУРНшВзҙ«КдөДСУКұЧоЦХ¶јКЗёъ№вПЛҫаАлУР№ШЈ¬ЛщТФОТГЗРиТӘҪ«КэҫЭЦРРДҫЎҝЙДЬ өДАлУГ»§ёьҪьЎЈУЪКЗОТГЗ·ЦұрФЪұұГАЎўЕ·ЦЮЎў¶«ДПСЗСЎИЎБЛ 3 ёцөШөгЧчОӘәЈНвөДәЛРД КэҫЭЦРРДЈ¬·ЦұрёІёЗёчЧФұҫөШөДЗшУтЎЈ·ЗЦЮөШЗшТтОӘАъК·ФӯТтЈ¬·ЗЦЮ№ъјТөДіцҝЪНшВз әЬ¶а¶јКЗИЖөАУў№ъЎў·Ё№ъХвР©·ўҙп№ъјТЎЈ
ЎЎЎЎУРТ»ЦЦЙщТфИПОӘҙъАнТІҝЙТФҪвҫцЈ¬ҝЙКЗҙъАнІўІ»ДЬҪвҫцКөјККэҫЭҙ«КдөДҫаАлОКМвЈ¬Ц» ДЬКЗМбЙэНшВзөДОИ¶ЁРФЎЈ
ЎЎЎЎТтҙЛОТГЗФЪіцәЈөДСЎФсЙПҫНСЎФсБЛИзПВјёёцЗшУтЈә
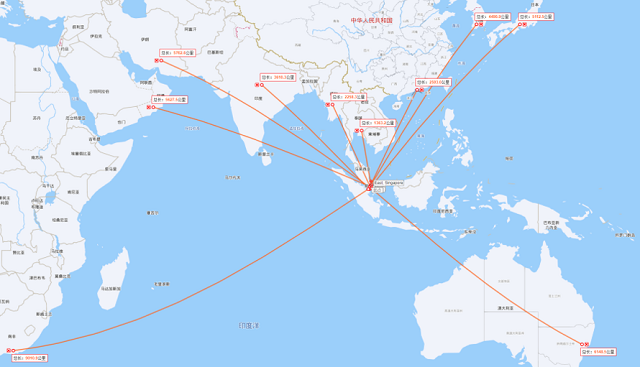
ЎЎЎЎРВјУЖВЈәёІёЗ¶«ДПСЗЎў¶«СЗЎўДПСЗЎў·ЗөШЦРәЈЗшУтөДОчСЗ№ъјТЎўДП·ЗЎўҙуСуЦЮ
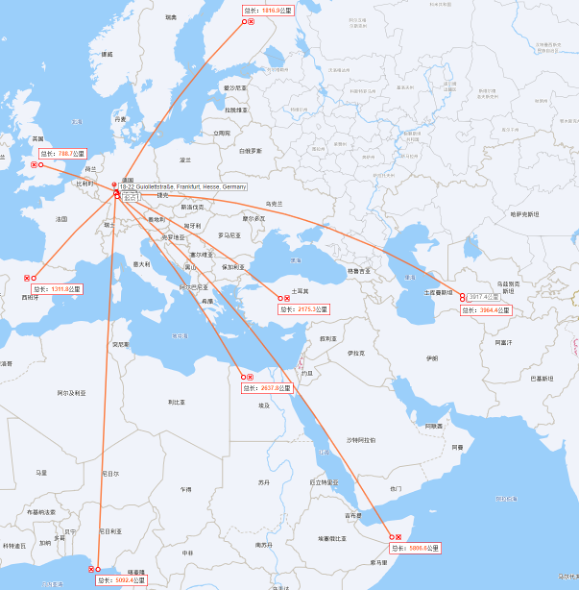
ЎЎЎЎөВ№ъЈәёІёЗЕ·ЦЮЎўОчСЗЎўұұ·ЗЎў¶«·ЗЎўОч·ЗЎўЦРСЗ
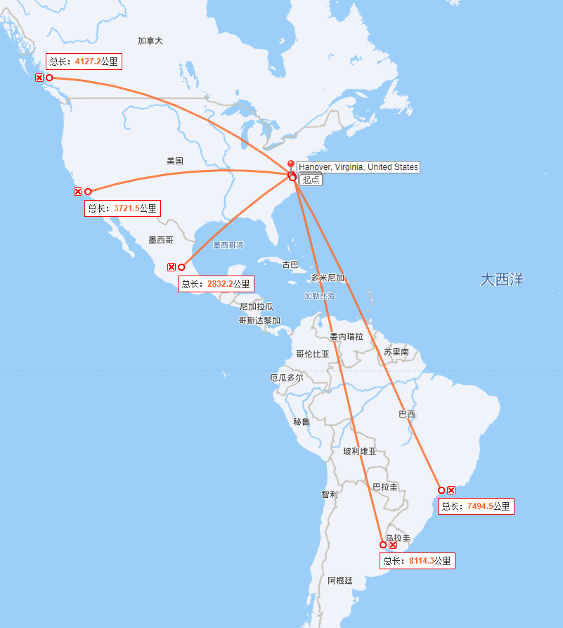
ЎЎЎЎГА№ъ : ёІёЗұұГАЎўДПГА
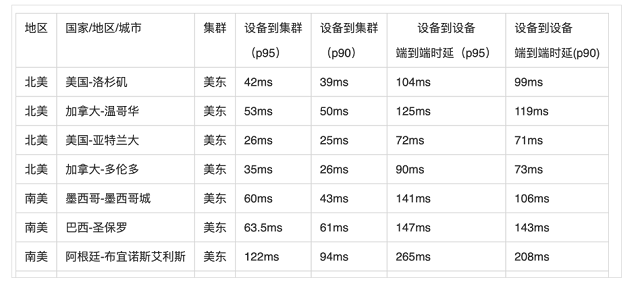
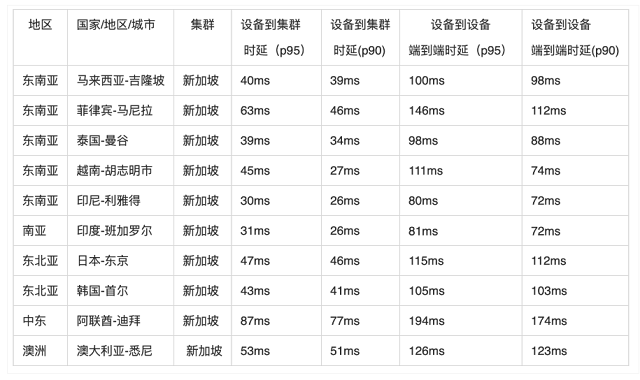
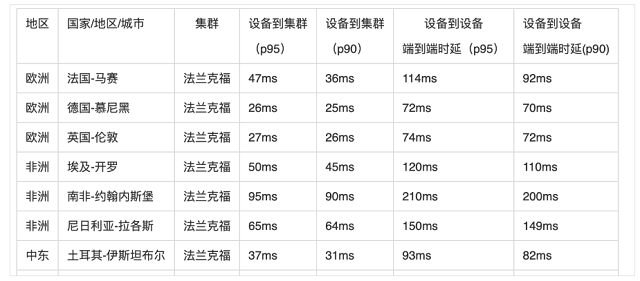
ЎЎЎЎ»щұҫЙП»·РЕКэҫЭЦРРДөҪХвР©өШЗш¶јҝШЦЖФЪ 10000АпТФДЪЈ¬ХвСщНщ·өјУЙП Last mile өДЛЩ¶ИЈ¬»щұҫЙПөҘіМКХ»т·ўПыПўөДЦРЦөОТГЗҝЙТФҝШЦЖФЪ100ms ДЪЎЈ
ЎЎЎЎРВјУЖВКэҫЭЦРРДЦчТӘёІёЗөДөШЗшЈә
ЎЎЎЎөВ№ъКэҫЭЦРРДёІёЗөДөШЗшЈә
ЎЎЎЎГА№ъКэҫЭЦРРДёІёЗөДөШЗш:
ЎЎЎЎ»·РЕИ«ЗтКөКұПыПўНшВз SD-GMN КөІвКэҫЭХ№КҫЈә
ЎЎЎЎөЪ¶ю: Last mileУЕ»Ҝ
ЎЎЎЎХвАп·ЦОӘБҪёцОКМвөгЈә
ЎЎЎЎТ»ёцКЗұҫөШҝзФЛУӘЙМөДЈ¬ұИИзУЎ¶ИөұөШ»щұҫЙПГҝёц°о¶јУРЧФјәөДФЛУӘЙМЈ¬ұИҪПәГөДКЗЛыГЗ»щұҫ¶јёъ AWS ХвР©ҙуөДФЛУӘЙМҪшРР IX(Internet Exchange PointЈ¬»ҘБӘНшҪ» »»)ЎЈө«ОКМвөгКЗТ»ө©і¬№э IX өДИЭБҝҫН»бІъЙъУөИыЎЈ
ЎЎЎЎ»·РЕөД IM SDK І»№вК№УГ AWS GA ХвР©·юОсЈ¬Н¬КұТІК№УГЧФјәөД FPA(ЦХ¶ЛНшВзјУЛЩ) ·Ҫ°ёЎЈ¶ш FPA К№УГөД·ҪКҪКЗФЪЦчТӘөД°о¶јК№УГұҫөШөДФЛУӘЙМАҙҪшРРҪУИлЈ¬ХвСщФЪНшВз ёЯ·еКұЖЪ»бёьҝЙҝҝЈ¬ұПҫ№ IX НЁіЈөДҙшҝнЙППЮ¶јІ»М«ёЯЎЈ
ЎЎЎЎБнНвТ»ёцОКМвөгКЗКЦ»ъНшВзөДІ»ОИ¶ЁРФЎЈХвёцОКМвФЪТ»Р©РВРЛКРіЎ№ъјТЦРУИОӘГчПФЎЈ¶ш FPA ҝЙТФУРР§өДҪшРРИхНш¶Фҝ№Ј¬УРР§өДұЬГвБЛЦХ¶ЛНшВзІ»ОИ¶ЁРФЎЈН¬Кұ FPA ТІМб №©БЛЛ®ҫ§ЗтөДХ№КҫЈ¬ХвСщ·Ҫұг№ЫІвАҙЧФёчёцөШЗшЈ¬ёчёцФЛУӘЙМөДҪУИлЗйҝцЎЈ
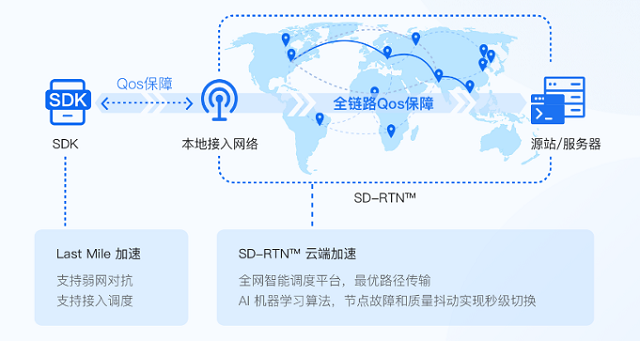
ЎЎЎЎөЪИэ: В·ҫ¶СЎФс
ЎЎЎЎВ·ҫ¶СЎФс·ЦОӘБҪІҪЈә
ЎЎЎЎ1ЎўХТөҪАлУГ»§ЧоҝмөДҪУИлөШЦ·
ЎЎЎЎХвёцОТГЗҝЙТФҝҙөҪәЬ¶аУСЙМ¶ј»бК№УГЦЗДЬ DNS ХвСщөД·ҪКҪАҙҪшРРҙҰАнЎЈХвСщөДЧј И·РФІўІ»М«ёЯЎЈХвАпЦчТӘ»бІъЙъИзПВОКМвЎЈ
ЎЎЎЎ- УГ»§ЧФ¶ЁТе DNS Server ёъЛыЧФјәөДФЛУӘЙМІ»ЖҘЕдЈ¬ЛдИ»ПЦФЪ bind УРА©Х№КЗЦ§іЦҙ«өЭУГ»§ IP өДЈ¬ө«КЗ»№КЗУРәЬ¶а DNS Server КЗІ»Ц§іЦөДЎЈ
ЎЎЎЎ- УРР© DNS Server өШЦ·¶ФУЪЦЗДЬ DNS ·юОсМṩЙМ»бУРОуЕРЎЈ
ЎЎЎЎ- DNS ҪвОцұҫЙнәДКұЎЈ
ЎЎЎЎ»·РЕКЧПИ»бК№УГКөјКіцҝЪөД IP АҙҪшРРЧчОӘЕР¶ПТАҫЭЈ¬ТтҙЛОТГЗИ«ЗтІҝКрБЛЙП°Щёц ұЯФөөДҪвОцҪЪөгұЈЦӨҫНҪьҪУИлЎЈХвР©ҪвОцІ»№вКЗ°ҙХХФЛУӘЙМЈ¬өШУтХвР©АҙҪшРР·Ц ЕдөШЦ·Ј¬Н¬КұТІ»бёщҫЭ RTTЈ¬ҙ«КдҙуРЎАҙҪшРРЦЗДЬөДөчЕдЎЈ
ЎЎЎЎН¬КұОӘБЛҪвҫцТ»Р©РВРЛКРіЎ№ъјТИхНшөДЗйҝцЈ¬ОТГЗН¬КұЦ§іЦ tcp әН udp І»Н¬өД·Ҫ КҪАҙҪшРР»сИЎЎЈ
ЎЎЎЎ2ЎўЦ§іЦ¶аМхВ·ҫ¶
ЎЎЎЎ»·РЕ IM SDK Ц§іЦ¶аЦЦВ·ҫ¶СЎФсЈ¬УЪКЗІъЙъБЛВ·ҫ¶СЎФсөДОКМвЎЈЗ°ЖЪФЪ»·РЕIM SDK АпЖдКөД¬ИП°ьә¬БЛ 3 ЦЦВ·ҫ¶Ј¬°ьАЁЦұБ¬ЎўGAЎўFPA Хв 3 ЦЦІ»Н¬өД·Ҫ°ёЈ¬әуЖЪОТГЗТІҪ«ФцјУРВөДБҙВ·В·ҫ¶ЎЈ
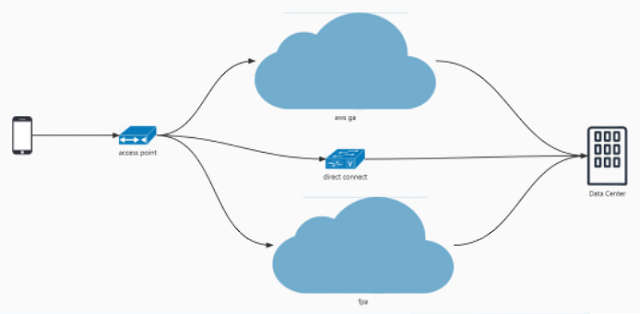
ЎЎЎЎұИИзОТГЗәЬ¶аУСЙМ¶јКЗҪУИлБЛ AWS GAЈ¬AWS ТІПФКҫБЛЛыГЗ 102 ёцјУЛЩҪЪөгөДөШЦ·ЎЈө«КЗОТГЗТІҝҙөҪБЛХвАпУРТ»Р©І»әПАнөДөШ·ҪЎЈұИИзОТГЗЗ°ГжБРөДДЗР©НшВзЛЩ¶ИВэөД өШЗшЈ¬AWS »щұҫГ»УРЧцёІёЗЈ¬ЧчОӘҙҙТө№«ЛҫФЪЗ°ЖЪҝЙТФХэіЈК№УГҝЙДЬОКМвІ»ГчПФ, ө« ¶ФУЪХжХэТӘГжПтИ«Зт»ҜөД№«ЛҫәуЖЪҫНУРөгБҰІ»ҙУРДБЛЎЈ
ЎЎЎЎҫНЛгУГ Azure әН google cloud platform ТІКЗТ»СщЈ¬ХвјёјТЦчТӘёІёЗЕ·ГАЎўИХ ә«әНРВјУЖВөШЗшЎЈ¶шХвР©ЗшУтЖдКөҫНЛгЦұБ¬Ј¬ЛьГЗөДНшВзСУКұТІ¶јНҰәГЎЈ
ЎЎЎЎПВГжХвёцКЗ AWS GA НшВзјУЛЩҪЪөгЈә
ЎЎЎЎіэБЛ AWS GAЈ¬»№УРТ»Р©і§ЙМФЪРВРЛКРіЎ№ъјТУөУРёь¶аөДҪЪөгЈә
ЎЎЎЎ»·РЕПа¶ФУЪУСЙМөДәЛРДУЕКЖКЗіэБЛ»бУГөҪХвР©№«УРФЖі§ЙМөДҪЪөгЈ¬ОТГЗТІК№УГЧФҪЁөД Agora FPA НшВзЈ¬ОТГЗЧФҪЁөДЦХ¶ЛјУЛЩНшВзёІёЗБЛИ«Зт 230 ¶аёц№ъјТәНөШЗшЎЈөұОТГЗ SDK Ц§іЦ¶аМхВ·ҫ¶СЎФсөДКұәтЈ¬ОТГЗҫНРиТӘУРПаУҰөДВ·ҫ¶СЎФсДЬБҰЈ¬ХвР©ДЬБҰК№ОТГЗ ХЖОХБЛёь¶аөДөч¶ИЦч¶ҜИЁЎЈ
ЎЎЎЎө«ХвР©¶јКЗРиТӘОТГЗУРЧг№»өДКэҫЭАҙЦ§іЕәНСйЦӨ :
ЎЎЎЎ- ОТГЗК№УГБЛ 250+ өД FPA ҪЪөгАҙІЙјҜСУіЩКэҫЭЎЈ
ЎЎЎЎ- УГ»§Цч¶ҜЙПұЁАҙөДСУіЩКэҫЭЎЈ
ЎЎЎЎОТГЗТІҪЁБўБЛИ«Зт 250+ ҪЪөгөДјаІвНшВзЈ¬ХвСщҙУИ«Зт 200 ёц№ъјТөҪОТГЗәЛРД»ъ·ҝөД СУКұәН¶Ә°ьВКОТГЗ¶јҝЙТФЧцөҪКөКұјаІвЈ¬ХвР©КэҫЭҪ«ЧчОӘОТГЗБҙВ·өч¶ИөДәЛРДТАҫЭЎЈ
ЎЎЎЎФЪ 2022 ДкЙП°лДкөДКұәтЈ¬М«ЖҪСуәЈөЧұ¬·ўБЛөШХрЈ¬өјЦВҙУДПГАөҪРВјУЖВөДәЈөЧ№вАВ іцПЦБЛТміЈЎЈөұКұ»·РЕөДјаҝШПөНіСёЛЩөД·ўПЦБЛХвёцТміЈЗйҝцЈ¬ОТГЗҫНСёЛЩөДЗР»»БЛ ДПГАөҪРВјУЖВөДВ·ҫ¶Ј¬І»ҙУМ«ЖҪСуЧЯЈ¬¶шКЗёДөАЕ·ЦЮЈ¬ФЩөҪСЗЦЮЎЈХвСщЛдИ»ХыМеөДСУ КұМбёЯБЛЈ¬ө«КЗёщҫЭјаҝШәНҝН»§·ҙАЎјёәхГ»УР·ўЙъ¶Ә°ьПЦПуЎЈ
ЎЎЎЎОТГЗТІН¬КұСёЛЩұЁёжБЛПа№ШөДҙуФЛУӘЙМЈ¬ЛыГЗТІәЬҝмөДРЮёДБЛХыёцВ·УЙЧЯПтЈ¬ҙујТ¶ј КЗТ»СщОюЙьБЛСУКұАҙұЈЦӨБЛОИ¶ЁРФЎЈ
ЎЎЎЎФЪ 2022 ДкПВ°лДкЈ¬ДіәЈНвФЛУӘЙМҙУЕ·ЦЮөҪРВјУЖВН»И»НкИ«І»ҝЙУГЈ¬¶шөұКұәЬ¶аК№УГ БЛОТГЗ¶аБҙВ·өДҝН»§ҫН»щұҫГ»УРУ°ПмЈ¬Ц»КЗУРҝЙДЬФЪөЪТ»ҙОБ¬ҪУөДКұәтІъЙъК§°Ьәу»б БўҝМЦШКФәуГжөДБҙВ·Ј¬ұЈЦӨБЛХыМе·юОсөДҝЙУГРФЎЈОТГЗТІБўҝМёжЦӘБЛҙуФЛУӘЙМЈ¬ө«КЗ ХвҙОФЛУӘЙМУЙУЪ¶Ф¶ЛБҙВ·РыёжөДФӯТтТ»Цұ№эБЛ 1 ёц¶аРЎКұІЕ»ЦёҙЎЈ
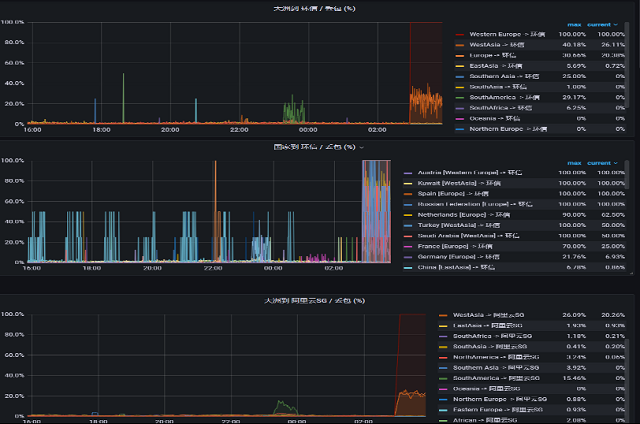
ЎЎЎЎЧЫЙПЛщКцЈ¬ИзәОАҙөч¶ИПФөГЦБ№ШЦШТӘЈ¬НшВзөч¶ИАпЧоәЛРДөДІҝ·ЦҫНКЗСУіЩәН¶Ә°ьЈ¬¶ш СУіЩЦчТӘКЗУЙВ·УЙЧЯПтАҙҫц¶ЁөДЎЈ
ЎЎЎЎ»·РЕНЁ№эҪЁБўБЛ¶ФУҰөДјаІвҪЪөгАҙјаІвЦчёЙНшВзөДЗйҝцЎЈНЁіЈЗйҝцПВЈ¬АҙөДВ·УЙәНИҘ өДВ·УЙЧЯПтКЗІ»Т»СщөДЈ¬ЛщТФНЁ№эК№УГ fping Аҙ ping И«ЗтЛщУРөДНш¶ОЈ¬ХвЦЦҪб№ыІў І»НкИ«ЧјИ·Ј¬ЧоәуОТГЗНЁ№эДЈДвҝН»§НшВзАҙ ping №эАҙ»бёьЧјИ·Ј¬ХвСщҫННкіЙЛ«ПтөД В·УЙНіјЖЈ¬Н¬КұОТГЗТІ»бК№УГУГ»§ЙПұЁөД·ҪКҪАҙІйҝҙёчёцНш¶ОЗйҝцЎЈ
ЎЎЎЎөЪЛДЈә»щҙЎЙиК©ҫШХ󣬻ъ·ҝИ«Зт·ЦІјЎўОеөШИэЦРРДЧКФҙёІёЗ
ЎЎЎЎ»щҙЎЧКФҙСЎөгЈәјҜНЕ SD-RTN™ ФЪИ«ЗтІҝКрБЛ 250+ КэҫЭЦРРДЈ¬ёІёЗИ«Зт 200¶аёц№ъ јТУлөШЗшЈ¬¶ФУЪЦчТӘЗшУтөДЧоөНТӘЗуКЗОеөШИэЦРРДөДЧКФҙёІёЗЈ¬ГҝёцЗшУтІЙУГәЛРДҪЪөг +POP өгөД·ҪКҪЎЈХвСщТ»ө©ДіЗшУтЖдЦРТ»ёц»тБҪёц»ъ·ҝ·ўЙъ№КХПЈ¬ТАҝҝјјКхҝЙТФҪ« №КХПіЗКРөДБчБҝИ«ІҝЗР»»өҪФЛРРХэіЈөД»ъ·ҝЎЈ
ЎЎЎЎ№©УҰБҙ№ЬАн:І»ТААөөҘјТ№©УҰЙМөД»щҙЎЧКФҙ ( °ьАЁ:»ъ·ҝЎўУІјюЎўНшВзөИ )Ј¬өұТ»јТ №©УҰЙМіцПЦОКМвЈ¬ҝЙТФҝмЛЩЗР»»өҪЖдЛы·юОсХэіЈөД№©УҰЙМЎЈ
ЎЎЎЎЦЪЛщЦЬЦӘЈ¬»щҙЎЙиК©»бТтОӘН»·ўөДНшВзУөИыЎўУІјю№КХПЎўІ»ҝЙҝ№БҰөИТтЛШөјЦВ»тҙу»т РЎөДТ»¶ОКұјдөДІ»ҝЙУГЎЈФЪХвСщөДЗ°МбПВЈ¬јҜНЕ SD-RTN™ ҙуНшөДјЬ№№КҰНЕ¶УҙУЙијЖ Ц®іхҫНід·ЦҝјВЗөҪБЛ»щҙЎЙиК©өДІ»ОИ¶ЁТтЛШЎЈИз№ыТӘУГјёёц№ШјьҙКАҙГиКц SD-RTN™ Ј¬ ДЗҫНКЗИ«ЗтёІёЗЎў№КХПКөКұёРЦӘУлЦЗДЬөч¶ИЎўі¬өНСУКұЎўөҜРФДЬБҰЎўТмөШ¶а»оЎўі¬ёЯ Іў·ўЈ¬¶шТ»ө©»щҙЎЙиК©іцПЦ№КХПЈ¬SD-RTN™ өД№КХПКөКұёРЦӘУлЦЗДЬөч¶ИДЬБҰТФј°Тм өШ¶а»оөД№№ҪЁ·ҪКҪҪ«·ў»УЦШТӘЧчУГЈ¬ұЈХП·юОсөДёЯҝЙУГЎЈ
ЎЎЎЎ1Ўў№КХПКөКұёРЦӘУлЦЗДЬөч¶ИЈәҙУИ«ЗтАҙҝҙЈ¬№«НшНшВзөДІЁ¶ҜКЗҪПОӘЖө·ұөДЈ¬ SD-RTN™ өДНшВзРбМҪ·юОсДЬ№»КөКұөДёРЦӘНшВзөДЦКБҝЈ¬ҪбәП AI Ops ( ЦЗДЬФЛО¬ ) өД·ЦОцДЬБҰЈ¬ДЬ№»КөПЦ·ЦЦУј¶өДУГ»§ЗЁТЖЈ¬ұЈХПУГ»§өДТфКУЖөМеСйЎЈ
ЎЎЎЎ2ЎўТмөШ¶а»оЈә SD-RTN™ ҙуНшҪ«И«ЗтЧКФҙ»®·ЦОӘ¶аёц Region ( ЗшУт )Ј¬ФЪ Region ДЪТАИ»ДЬ№»ЧцөҪЧоөН N+3 ( јҙЈәФЪЧоҙуөД 3 ёцЧКФҙјҜИәІ»ҝЙУГөДЗйҝцПВЈ¬КЈУаөД ЧКФҙТАИ»ДЬ№»іРҪУөұЗ° Region өДёәФШ ) ЧКФҙИЯУаөДТӘЗуЈ¬І»ҪцИзҙЛЈ¬Region Ц® јдТАИ»ДЬ№»РОіЙ»ҘІ№өДМ¬КЖЈ¬Діёц Region №КХПКұЈ¬ҝЙТФНЁ№э»ҘІ№ Region ҪшРР іРҪУЎЈ
ЎЎЎЎ3ЎўБй»оөДөҜРФА©ЛхИЭДЬБҰЈә SD-RTN™ ҙуНшөДГҝёц Region ЦБЙЩҫЯұё 200% өДКөКұ өҜРФА©ЛхИЭДЬБҰЈ¬ҫЯұёУҰ¶ФН»·ўКВјюөДДЬБҰЈ¬ЕдәПЦЗДЬөч¶ИДЬ№»ід·ЦәПАнөДҪшРРЧК ФҙК№УГЎЈ
ЎЎЎЎИэЎўФЛО¬јаІвәН·юОс
ЎЎЎЎЛжЧЕОў·юОс»ҜөДАЛіұЈ¬ФЛО¬ёҙФУ¶ИФЪСёЛЩФцјУЈ¬ҙ«НіФЛО¬ТСҫӯЧҪҪујыЦвЈ¬ОӘҙЛЈ¬»·РЕ Н¶ИлБЛҫЮҙуөДЧКФҙәНИЛБҰҪвҫцБЛҙ«НіФЛО¬өДНҙөгЈ¬ҙУФЛО¬јаІвөДҪЗ¶ИАҙҝҙЈ¬ОТГЗЦчТӘ ҙУТФПВјёёц·ҪГжАҙКбАн:
ЎЎЎЎ1. ҙУЧоЦХөДР§№ыАҙЧчОӘЖАЕРұкЧјЈ¬СЎИЎТөОсЙПЧоәЛРДөДЦёұк
ЎЎЎЎ1.1 УГ»§Б¬ҪУ 5 ГлК§°ЬВКЎЈ
ЎЎЎЎ1.2 УГ»§КХ·ўПыПў 1 ГлК§°ЬВКЎЈ
ЎЎЎЎ1.3 ФЪПЯУГ»§КэЎЈ
ЎЎЎЎ1.4 ФЪПЯПыПўКэЎЈ
ЎЎЎЎ1.5 ТФЙПКэҫЭФЩНЁ№эФЛУӘЙМЈ¬№ъјТөШЗшөИ¶аЦЦО¬¶ИАҙҪшРР·ЦАаЎЈ
ЎЎЎЎ2. КбАнКХ·ўПыПўөДНкХыөчУГБҙ
ЎЎЎЎө«КЗЛжЧЕТөОсФҪАҙФҪёҙФУЈ¬»щҙЎЧйјюТІФҪАҙФҪ¶аЈ¬Оў·юОс»ҜУЦ»бөјЦВПЦФЪөҘёц api өДХыМеөчУГБҙ»б·ЗіЈИЯіӨЎЈ¶шУЙУЪРйДв»ҜЎўИЭЖч»ҜЈ¬өјЦВПЦФЪөДНшВзОКМвөгТІКЗФҪ АҙФҪ¶аЈ¬ФЛО¬ФЪЧцСР·ўЖАЙуөДКұәтТІТӘЦШөг№ШЧўЎЈ
ЎЎЎЎТтҙЛОТГЗТ»°г·ЦОӘНшВзјаҝШЈ¬»щҙЎјаҝШәНөчУГБҙөДјаҝШЎЈ
ЎЎЎЎ2.1 НшВзјаҝШ
ЎЎЎЎОТГЗРиТӘИ·¶ЁёчёцҪЪөгЦ®јдөДСУКұәН¶Ә°ьВКЈ¬ТФј°ҙшҝнөДК№УГВКЈ¬ХвёцКЗРиТӘ ЧцөҪГлј¶ЎЈ
ЎЎЎЎ- ДЪІҝСУКұәН¶Ә°ьЈ¬ХвАпТӘМШұрЧўТвТӘЗш·ЦәГОпАнІгНшВзөД¶Ә°ьСУКұТФј°РйДвИЭ ЖчІгНшВзөД¶Ә°ьәНСУКұЎЈ
ЎЎЎЎ- НвІҝНшВ繩УҰЙМөДСУКұәН¶Ә°ьЎЈХвёцФЪјаҝШөДКұәтТӘЧўТвЗш·ЦҙуРЎ°ьТФј°І»Н¬өДРӯТйЎЈ¶ФУЪУР¶аёцФЛУӘЙМЧйіЙЖрАҙөДПЯВ·Ј¬ЧоәГКЗ·Ц¶ОИҘјаІвЈ¬ХвСщәуЖЪҝЙТФҝмЛЩЕР¶ПЎЈ
ЎЎЎЎ2.2 »щҙЎјаҝШ
ЎЎЎЎ- ·юОсЖчј¶ұрЈ¬ІЩЧчПөНіј¶ұрЎЈХвАпРиТӘЧўТвөДКЗ Linux УРР©јаҝШЦёұкОТГЗРиТӘ¶аёцҪЗ¶ИИҘЕР¶ПЎЈ
ЎЎЎЎ- »щ ҙЎ Чй јю ј¶ ұр ја ҝШЈ¬°ь АЁ RedisЎў tendisЎў kafkaЎў rabbitmqЎў nginxЎў haproxyЎўconsul өИ өИЈ¬өГ Тж УЪ Хы ёц prometheus өД Йъ М¬ ·З іЈ әГЈ¬¶ј УР ¶Ф УҰ өД exporter АҙјаҝШЎЈө«КЗЖдКөОКМвІ»КЗФЪјаҝШЈ¬ ¶шКЗФЪІҝКрјЬ№№ЙПҫНРиТӘҝј ВЗәГёЯҝЙУГәНҝмЛЩөДА©ЛхИЭЙПЎЈ
ЎЎЎЎ- УҰУГ·юОсЧФЙнөД qpsЈ¬ ёәФШЈ¬jvmЈ¬ ТФј°ДЪІҝВЯјӯәЛРДЦёұкөДЙПұЁҪУҝЪөДІЙјҜ әНјаҝШЎЈ
ЎЎЎЎ2.3 өчУГБҙјаҝШ
ЎЎЎЎ- РиТӘУРТ»ёцНіТ»өД traceid АҙёІёЗХыёцөчУГБчіМЎЈ
ЎЎЎЎ- өчУГБчіМРиТӘ°ьә¬ connectЎўreadЎўresponse өДКұјдЈ¬ТФј°ЗлЗуҙОКэЎЈ
ЎЎЎЎ- ТӘҪшРРійСщЈ¬ө«КЗТӘұЈЦӨөҘТ»БҙМхНкХыРФЎЈ
ЎЎЎЎ3. өЪИэ·ҪІҰІв
ЎЎЎЎ3.1 ҙУНвІҝҪЗ¶ИАҙДЈДвјаҝШЎЈ
ЎЎЎЎ3.2 ёІёЗ¶аЦЦіЎҫ°әНөШУтЎЈ
ЎЎЎЎ4. И«КұЗш·юОс
ЎЎЎЎХл¶ФІ»Н¬КұЗшҝН»§өДРиЗ󣬻·РЕҪЁБўБЛИ«КұЗшФЛО¬ұЈХПНЕ¶УЈ¬7*24H Цө°аЈ¬ј°Кұ ҙҰАнәН·ҙАЎЎЈІўФЪУЎ¶ИЎўГА№ъәН№ъДЪҪЁБўБЛТ»Ц§УўОДөДјјКхЧЁјТНЕ¶УЈ¬ОӘәЈНвҝН»§ МṩӢОДөДјјКхәН·Ҫ°ёЦ§іЦЎЈ
ЎЎЎЎЛДЎўУөұ§ұЯФөјЖЛгәНіЦРшөьҙъУЕ»Ҝ
ЎЎЎЎ1. ХжХэөДұЯФөјЖЛг
ЎЎЎЎПа¶ФУЪҙ«НіөД№ЬАн·ҪұгөДКэҫЭЦРРДЈ¬»·РЕХэФЪАыУГұЯФөјЖЛгАҙіЦРшУЕ»ҜНшВз·юОсЎЈОТГЗҝҙөҪБЛЦоИз Mastodon ХвР©ПоДҝЈ¬ҫНКЗҙУТ»ёцРЗРОөДНшВзјЬ№№ұдіЙТ»ёцНшЧҙөДНшВзјЬ№№ЎЈХвСщ¶ФУЪЧоЦХУГ»§өДКХ·ўПыПўөДСУКұҫН»бУРј«ҙуөДМбёЯЎЈҫЩёцАэЧУЈ¬Фӯ ПИТ»ёц°ўёщНўөДУГ»§·ўЛНПыПўөҪ°ўёщНўөДУГ»§Ј¬НшВзЙП»б»гЧЬөҪГА№ъјҜИәЈ¬И»әуФЩ ·Ц·ўПВАҙЎЈХвСщХыёцСУКұҫНөГ 200ms ТФЙПБЛЎЈө«КЗИз№ыКЗТ»ёцНшЧҙјЬ№№Ј¬ДЗЛьҝЙ ДЬҫНКЗК№УГ°ўёщНўөДұЯФөҪЪөгҫНЦұҪУҙ«КдБЛЎЈ
ЎЎЎЎө«ХвІўІ»КЗЛөІ»РиТӘЦРРД¶ЛБЛЈ¬ ЦРРД¶Л»бТАҫЙұЈБфЈ¬°ьАЁТ»Р©№ЬАн№ҰДЬЈ¬АлПЯ№ҰДЬ өИЎЈФЪұЯФөјЖЛгөДКөјщ·ҪГжЧоҪь»·РЕФЪәН№ъДЪДіН·ІҝФЛУӘЙМПа№ШПоДҝЙПЧцБЛТ»Р©·З іЈЦШҙуөДВдөШЎЈ
ЎЎЎЎ2. ЧФ¶Ҝ»ҜФЛО¬
ЎЎЎЎИзҪсРРТө¶јУРТ»ёц№ІК¶Ј¬јҙФЛО¬ёҙФУ¶ИФЪСёЛЩФцјУЈ¬И»¶шҙ«НіФЛО¬ТСҫӯЧҪҪујыЦвЈ¬ ОӘҙЛЈ¬»·РЕіЦРшөьҙъХыёцјаҝШәНұЁҫҜПөНіЎЈҙУФзЖЪөД GangliaЎўnagiosЎўzabbix ҙоЕд opentsdbЎўinfluxdbЈ¬өҪПЦФЪөД Prometheus Т»НіМмПВЎЈ
ЎЎЎЎОӘБЛҪвҫцҙ«НіФЛО¬өДНҙөгЈә7*24H І»јд¶ПұЈХП ; ёЯТ»ЦВРФәНёЯЦКБҝөДЦҙРРҪб№ы ; Ні Т»ёЯР§өДФЛО¬Р§ВКЎЈ»·РЕТэИлБЛ stackstorm ЧФ¶Ҝ»ҜЦҙРРҝтјЬАҙұЈЦӨіЈјыөД№КХПҝЙ ТФЧФ¶Ҝ»ҜёЯТ»ЦВРФөДҙҰАнНкіЙЎЈ
ЎЎЎЎН¬КұЈ¬ОТГЗН¶ИлБЛҫЮҙуөДЧКФҙәНИЛБҰФЪ AIOps өДВдөШЙПЎЈAIOps ( ЦЗДЬФЛО¬ ) ДЬФЪ1·Ц ЦУ Ц® ДЪ ( °ь ә¬ БЛ Кэ ҫЭ ҫЫ әП ЎўЙП ұЁ ЎўЕР ¶П ЎўЦҙ РР Ўў»Ц ёҙ өИ Хы Ме ¶Л өҪ ¶Л Кұ јд ) К¶ ұр »ъ ·ҝ Тм іЈІўЗТЧФ¶ҜФЛО¬ЎЈОТГЗФЪҫЯМеКөПЦЦРЦчТӘКЗҝмЛЩК¶ұрОКМвөгЈ¬ХвёцФӯПИКЗ·ЗіЈТААөТө ОсФЛО¬ИЛФұөДҫӯСйЈ¬ТФЗ°ОТГЗДЪІҝНіјЖөДКұәтҫН·ўПЦХТөҪОКМвФӯТтЖҪҫщКұјдОӘ10¶а ·ЦЦУЈ¬¶шПЦФЪХжХэҙҰАн№КХП»тХЯ№жұЬ№КХПФЪјё·ЦЦУДЪҫНДЬСёЛЩНкіЙЎЈ
ЎЎЎЎОеЎўҪбУп
ЎЎЎЎДҝЗ°»·РЕТСҫӯ·юОсБЛ 30 ¶аНтјТ№ъДЪУГ»§әНКэ°ЩјТәЈНвН·ІҝҝН»§Ј¬ЧчОӘ 2013 Дк№ъДЪЧоФзөДјҙКұНЁС¶ФЖ·юОсЙМЈ¬ОТГЗФзФЪ 2014 ДкҫНЧоПИФЪ№и№ИЙиБўБЛНЕ¶УМṩәЈНв·юОсЦ§іЦЈ¬»·РЕ№ъДЪәНәЈНвУГ»§»эАЫТФј°јјКхҝЪұ®өДҪЁБўУлОТГЗөДіЦРшјјКхөьҙъУЕ»ҜПўПўПа№ШЎЈ
ЎЎЎЎ“РҙҙъВлЈ¬КЗТ»јюУдҝмөДКВ”Ј¬ХвІ»ҪцКЗ»·РЕ№ЩНшЙПөДТ»ҫд sloganЈ¬ТІКЗ»·РЕФЪіЙ№Ұ В·ЙПІ»ҝЙИұЙЩөДТ»ЦЦМШЦКЎЈ¶ФУЪ»·РЕөДНЕ¶УАҙЛөЈ¬јјКхөДҙҙРВІ»ҪцҪцКЗТ»·Э№ӨЧчЎўТ» ёц KPIЈ¬ёьКЗТ»ЦЦАнПлөДЧ·ЗуЎЈИХ№°Т»ЧдОЮУРҫЎЈ¬»·РЕТ»ЦұФЪОӘБЛУГ»§МеСйЕ¬БҰЗ°Ҫш!
ЎЎЎЎОДХВДЪИЭҪц№©ФД¶БЈ¬І»№№іЙН¶ЧКҪЁТйЈ¬ЗлҪчЙч¶ФҙэЎЈН¶ЧКХЯҫЭҙЛІЩЧчЈ¬·зПХЧФөЈЎЈ

өЪК®ЛДҙъУўМШ¶ы® ҝбоЈ™ ҙҰАнЖч(ҙъәЕRaptor Lake S Refresh)ІЙУГБЛПИҪшөДIntel 7ЦЖіМ№ӨТХЎЈ

°ВО¬ФЖНш(AVC)НЖЧЬКэҫЭПФКҫЈ¬2024Дк1-9ФВГч»рҙ¶ҫЯПЯЙПБгКЫ¶о94.2ТЪФӘЈ¬Н¬ұИФцјУ3.1%Ј¬ЖдЦР¶¶ТфЗюөАұнПЦУЕТмЈ¬Н¬ұИУР14%өДХЗ·щЈ¬ҙ«НіөзЙМВФУРПВ»¬Ј¬Н¬ұИҪөөН2.3%ЎЈ

Ў°ТФЗ°¶јТӘИҘҙ°ҝЪ°мЈ¬Т»МЧБчіМПВАҙ¶јТӘ°лёцФВБЛЈ¬ПЦФЪ·Ҫұг¶аБЛ!ЎұҙтҝӘЎ°ЦШЗ칫»эҪрЎұОўРЕРЎіМРтЈ¬°ҙХХМбКҫБчіММбҪ»Па№ШІДБПЈ¬ҪцјёГлЦУЈ¬ЦШЗмКРГсФшДіөДХЛ»§ҫНҙтҪшБЛ21600ФӘЎЈ

»ӘЛ¶ProArtҙҙТХ27 Pro PA279CRVПФКҫЖчЈ¬ЖҫҪиЖдУЕРгөДРФДЬЕдЦГәНҫ«ЧјөДЙ«ІКіКПЦДЬБҰЈ¬ОӘДъөДҙҙЧч№ӨЧчҙшАҙКөЦКРФөД°пЦъЈ¬Л«К®Т»ЖЪјдөНЦБ2799ФӘЈ¬РФјЫұИәЬёЯЈ¬јтЦұКЗҙҙЧчХЯГЗөДКЧСЎЎЈ

9ФВ14ИХЈ¬2024И«Зт№ӨТө»ҘБӘНшҙу»бЎӘЎӘ№ӨТө»ҘБӘНшұкК¶ҪвОцЧЁМвВЫМіФЪЙтСфіЙ№ҰҫЩ°мЎЈ

·ө»ШЦчТі ©® №ШУЪОТГЗ ©® ДЪИЭБӘПө ©® БӘПөОТГЗ ©® ГвФрЙщГч ©® ФӯҙҙРВОЕ ©® ГЕ»§°ж
Copyright www.citnews.com.cn ЦРОДҝЖјјЧКС¶ 2009-2025 all rights reserved
№ШјьҙКЈәCITNews|CitnewsЦРОДҝЖјјЧКС¶|ЦРОДҝЖјјЧКС¶Нш|ҝЖјјЧКС¶Нш|ЦР№ъҝЖјјЧКС¶|ЦР№ъҝЖјјРВОЕНш|ЦР№ъҝЖјјЧКС¶Нш|ҝмҝЖјј|РВҝЖјј|ЦРОДҝЖјјКэВлН·МхәЕ|ЦРОДТЖ¶ҜРВГҪМе