����������Ҫ�������������ݲֿ⽨����Я�������Ŷӵ������ʵ��������ҵ��ʹ�㡢ҵ��Ŀ�ꡢ��Ŀ�ܹ�����Ŀ�����ά��չ����
����һ��ҵ��ʹ��
������������ʵʱ���������࣬�������ֱ�¶������ҵ��ʹ��ҲԽ��Խ�࣬���磺
����ʵʱ�����̴ѿ���ģʽ
�����м����ݿɸ����Բ�
�������������ݿ�������
������������->�������ڳ�
����ʵʱ��/�������ҡ�������
����ʵʱѪԵ/������Ϣ/��ص�ȱʧ
����ʵʱ���� �����������
����ʵʱ���� ��ά�ż��� ������ϵ��
����������͵����⣬������ǵ���Ч�������������ȷ�������ϴ��飬ؽ��һ����ϵ����ƽ̨�������
��������ҵ��Ŀ��
����Χ����֪ҵ��ʹ�㣬�����ڹ�˾���еļ�����Դ���洢��Դ���������ֱ��淶�ȣ����ǵ�Ŀ��������Ч�������������⼸���������ϵͳ���衣����ͼ��
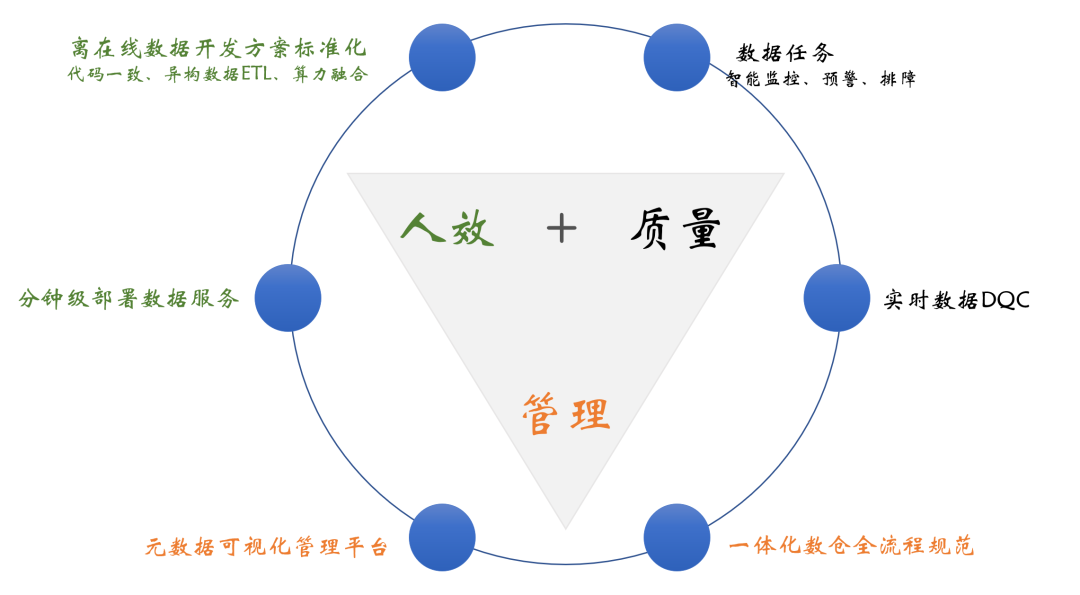
����2.1 ������
����ʵ�����������ݿ���������������������ݴ����������ߴ�����ݡ������ںϵ�
�������Ӽ����ݲ���ʵ��BIͬѧ��������ݽӿ�ע�ᡢ���������Եȿ��ӻ�����
����2.2 ��������
������������DQC�������ݶԲ��ԡ�ȫ��ȫ���Ƿ�ʱ���Ƿ�������һ�µ�
������������Ԥ�����������ӳ١�����ѹ��������ô����ϵͳ��Դ��������
����2.3 ��������
�������ӻ�����ƽ̨����ȫ��·ѪԵ�����ݱ�/�������������ʵȻ�����Ϣ
����һ�廯����ȫ���̹淶�������ݽ�ģ�淶�����������淶�����������淶���洢ѡ�淶��
����������Ŀ�ܹ�
������Ŀ�ܹ�����ͼ����ϵͳ��Ҫ������ԭʼ���� -> ���ݿ��� -> ���ݷ��� -> �������� -> ���ݹ�����ģ�飬�ṩʵʱ�����뼶���������ݷ�����Ӽ��������������ʵʱ���ݿ���ͬѧ��������ݷ���ʹ�á�
������ͬ������Դ���������Ⱦ�������ETL����������ݱ���������������ת�����߽�������Ԥ������ʹ�������ںϹ����Լ�ҵ�����ݴ���ģ����зֲ�����裬�����õ�����ʹ�����ݷ���ģ��ֱ�ӽ����ݽ�������api�������չ�ҵ��Ӧ��ʹ�ã�������·���ж�Ӧ����������ά������ϵ��
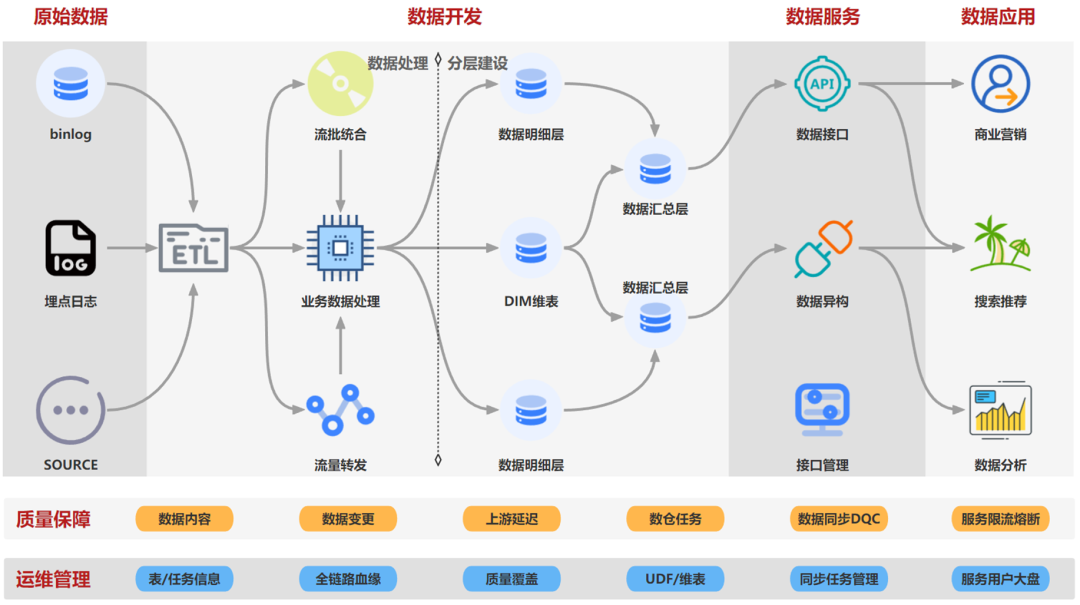
�����ġ���Ŀ����
����4.1 ���ݿ���
������ģ����Ҫ��������Ԥ�������ߡ����ݿ�������ѡ�͡�
����4.1.1 ����ת������
����������ڶࡢ��������Ҫ�����������⣺
����ͬά�ȵ�������Դ��������ʽ�����ж���
����ʹ�õ����������ռ�����ı�����Լ20%��ȫ��������Դ�˷����أ���ÿ�����ζ����ظ�����
���������������ݴ�����Ҫ��������(����������漰��ȫ��ʹ�÷�)
��������ͼ������ת�����ߣ��߱���̬����������Դ�������������ݴ��������ҽ���Ч���ݽ��б�����д�����Σ��ɽ���������⡣
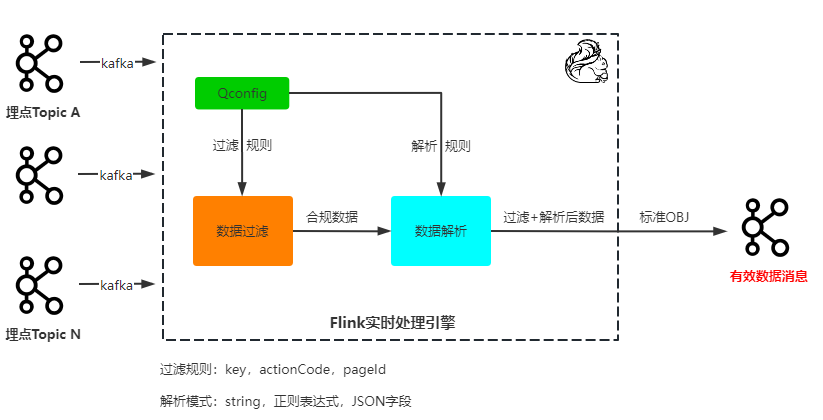
����4.1.2 ҵ�����ݴ��������ݽ�
��������1-���������ݼ��ں�
��������
���������ʼ��ʱ��ҵ������Ƚϵ�һ��������û���ʷ��ʵʱ���������ۺ��û���ʷ������ľ�����Ϣ�ȡ������������Գ�����������ݺ�ʵʱ���ݼۺϣ�����ֵ�͵ļӼ��˳����ַ��͵�append��ȥ�ػ��ܵȡ�
�����������
��������ͼ�����������ṩ�����ṩ������T+1��ʵʱ���ݽ���;���ݴ�����T+1��ʵʱ�����ں�;һ����У��;��̬�������洦����;���ݴ洢��֧�־ۺ�����ˮƽ��չ;��ǩӳ��ȡ�
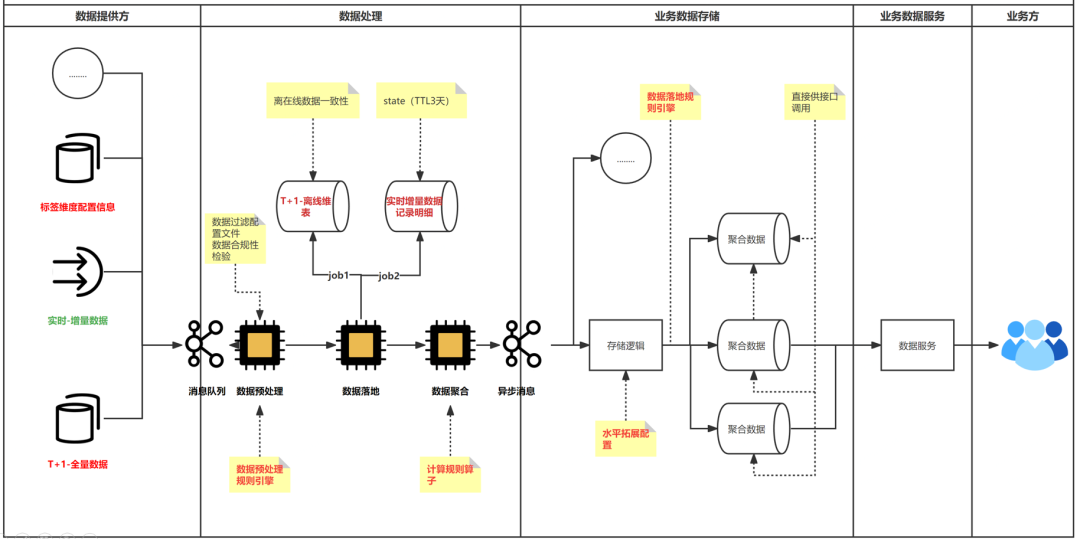
��������2 - ֧��SQL
��������
������Ȼ˵����1���������ƣ�
�����ֲ��ʱЧ��ǿ
��������������ӦѸ�٣��ɳнӴ����ĸ���UDF
������������ȴ���
������������java��̬
��������Ҳ�����������ƣ�
����BI SQL������Ա���������롢ǿ��������
����SQL�ܶೡ����ʹ��java�����ɱ��ߣ��ȶ��Բ�
����û����Ч�����ݷֲ�
�����������ݻ��������ã����Ҫ����������ݣ���Ҫ�ظ����㣬�˷Ѽ�����Դ
�����������
��������ͼ��kafka�������ݷֲ㹦�ܣ�Flink SQL�ļ������棬OLAP�������ݴ洢���ֲ��ѯ����ɵ��͵�����ϵͳ�ֲ㽨�衣
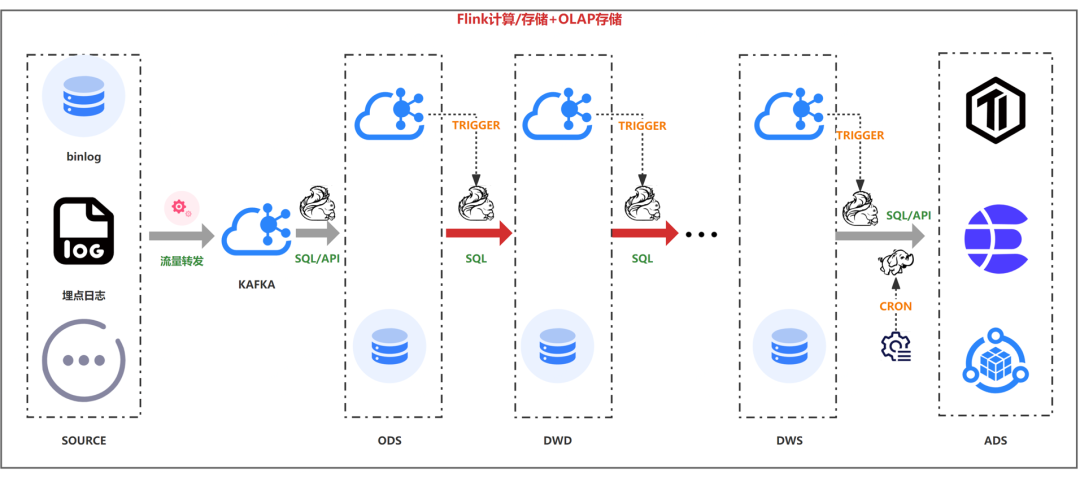
������������kafka��olap�洢�������������壬���ܻ�������ݲ�һ�µ����������kafka���������ݿ��쳣���ᵼ���м�ֲ�������쳣���������ս��������Ϊ�˽���������⣬����ͼ�������˴�ͳ���ݿ�ʹ�õ�binlogģʽ������kafka����ǿ����DB�����ݱ�����������ս��ǿ�����м�ֲ��������Dz��ܱ������big���µ����ݲ�һ�����⣬���ֳ����Ѿ��������á�
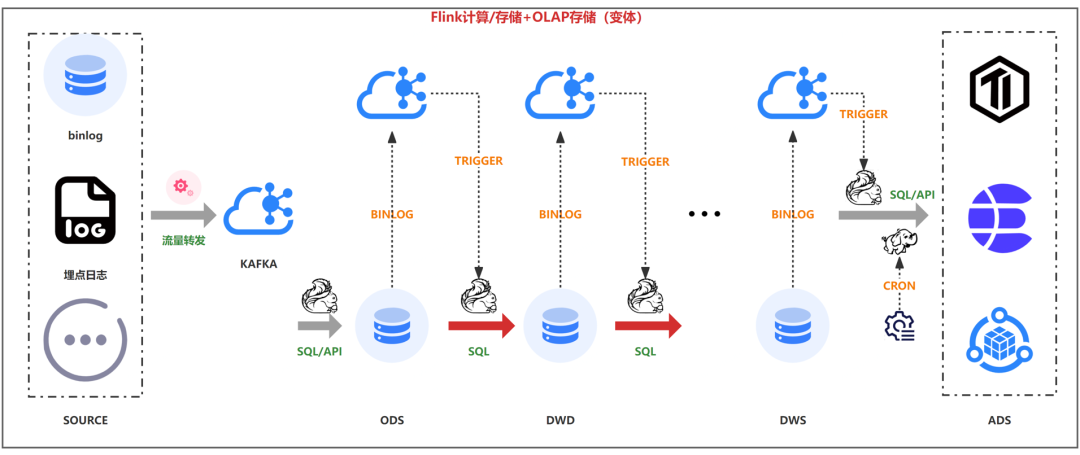
��������3
��������
������Ȼ˵����2���������ƣ�
����SQL��
������Ȼ�ֲ��ѯ
��������Ҳ�����������ƣ�
�������ݲ�һ�µ�����
����binlog��insert��ʱ��ûɶ���⣬���Ǹ��º�ɾ�����ø㣬���Ҹ��µ�ʱ��Ҫ��������ȥ�ز�����sql�ܲ��Ѻ�
������ʱ�����ݾۺϣ�����������max��min��flink״̬�����ײ��ȶ�
������Ҫ����kafka���������µ����ݸ�������
�����������
��������ͼ���ô洢����ļ���������kafka��binlogֻ����Ϊ���ݼ���Ĵ�������ֱ��ʹ��Flink UDF����ֱ��DB��ѯ��
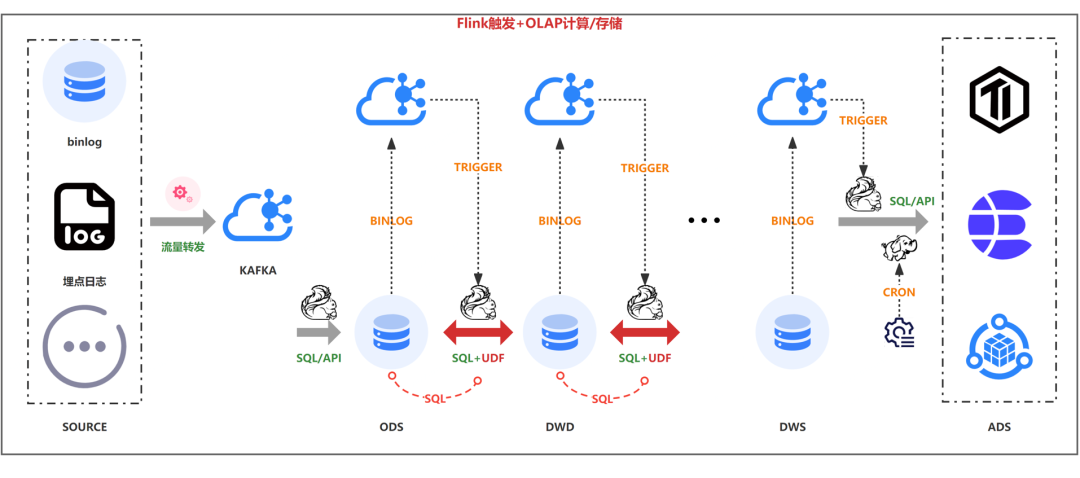
�������ƣ�
����SQL��
������Ȼ�ֲ��ѯ
��������һ��
����FLink״̬С
������֧�ֳ�ʱ��ij־û����ݾۺ�
�����������binlog����update�ȴ���������
�������ƣ�
������������������ǿ����olap�������ܣ�����������Դ��ʱ���window����������ˮƽ����db
����sinkʱ��س�����ϱ���ϣ����磺group by����ʵ�������Ե�upsert��udf�ľۺ�û�����flinkԭ���ľۺ�
�������������������ó�������Ҫ���ݲ�ͬ��ҵ�����ӳ������з���ѡ�͡�Ŀǰ����86%�ij���������ʹ�÷���3���гнӣ���������Flink 1.16����������һ������Լӳ֣����ڻ����ɸ���ȫ��������
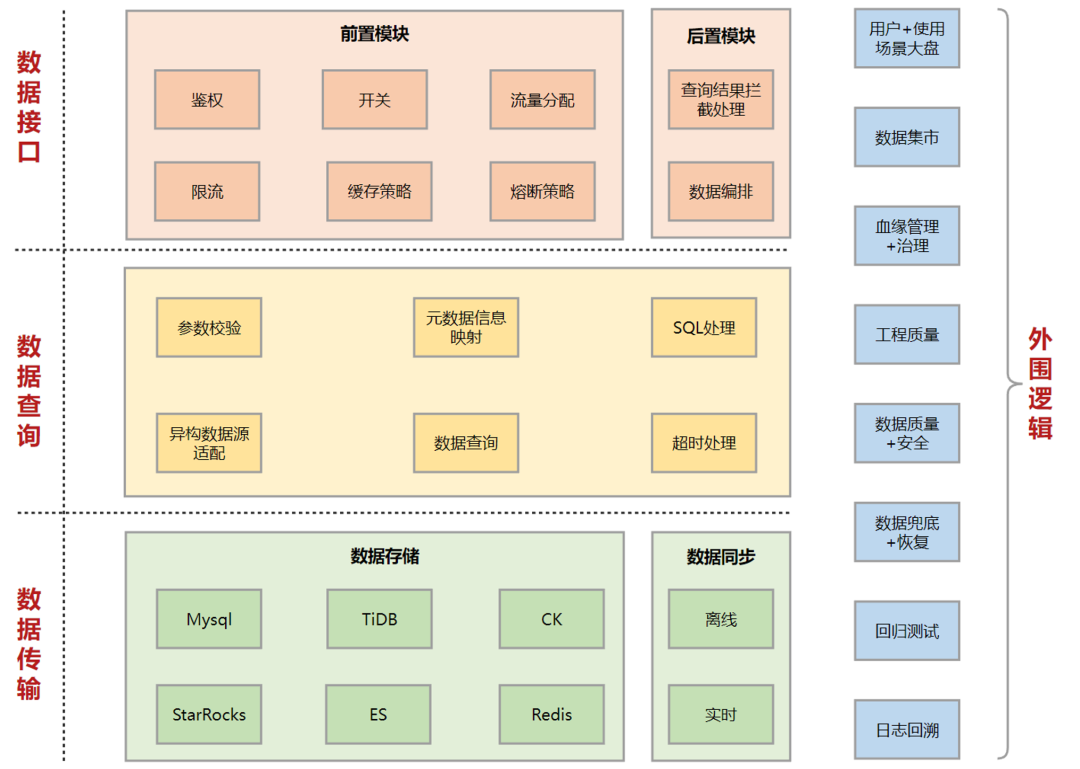
����4.2 ���ݷ���
������ģ���ṩ������ͬ�� -> ���ݴ洢 -> ���ݲ�ѯ -> ���ݷ����������������ʵ�ַ��Ӽ������ݷ������������ɽ�Լ90%�Ŀ�����ʱ��ʵ������������DQCǿ���������̲�DQC�쳣���ס��ͻ���->�ӿڼ������Դ����/����/�۶ϡ�ȫ��·ѪԵ(�ͻ���->�����->��->hive��->hiveѪԵ)�����ȣ��ṩ�˰�����и�������Ҫ��ӿڲ������ά����������
�����ܹ����£�
����4.3 ��������
������ģ����Ҫ��Ϊ����������������������������
����4.3.1 ��������
������ȷ��/��ʱ��/�ȶ���
�����ò����ַ�Ϊ���ݲ����仯����������һ���ԡ����ݶ�ȡһ���ԡ�������ȷ��/��ʱ�Եȡ�����ͼ��ʾ�����ݱ��������쳣���ɽ����ݴ��빫˾��hickwall�澯��̨��������Ԥ������澯���������ݣ����ж�ʱ����ִ���û��Զ����sql��䣬������д��澯��̨����ʵ���뼶�ͷ��Ӽ�Ԥ����
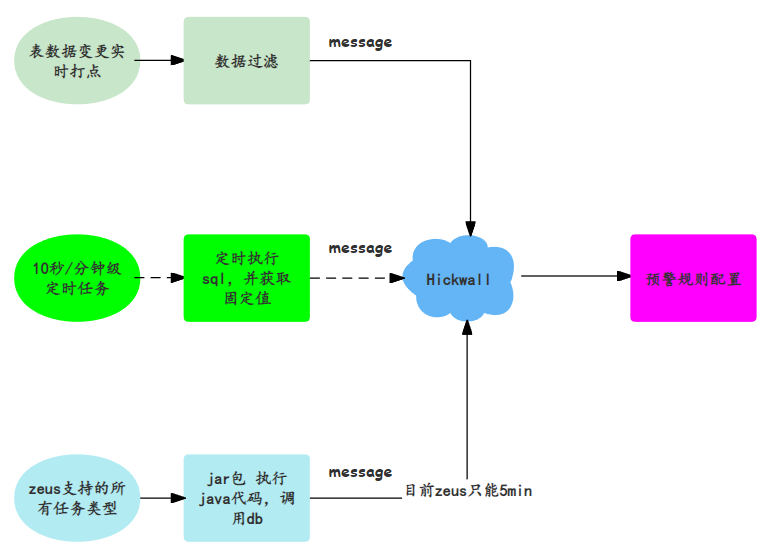
������ȡһ����
��������ͼ�����ݶ�ȡʱ��������ڿ�������ϲ�ѯ���������ij�ű��������⣬���������²���չʾ�������ݣ�ֻ��չʾ��ʷ�ϵ���ȷ���ݣ����ñ��ָ���Ż�ȫ��չʾ��
�����磺��¶��Ҫ����1�ͱ�2������������(��1/��2)�������2���������쳣�����2Сʱû���ݣ�����¶���û�ʱ��ҵ����Ҫֻ��չʾ2Сʱ֮ǰ�����ݣ��쳣���ݸ���ǰ���쳣���� ����flink watermark�ĸ������ȷ���ݶ���������ԡ�
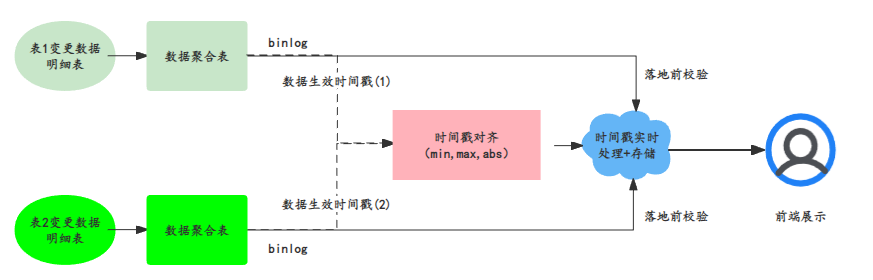
����������һ����
�����������ߺ�ʵʱ������һ���ԡ�����ͼ�����Dz��ý�Ϊ�ķ�����ֱ�ӽ�ʵʱ����ͬ����hudi������ʹ��hudi�������ߺ�ʵʱ���ݶԱȣ�����澯��̨��
����ͼƬ
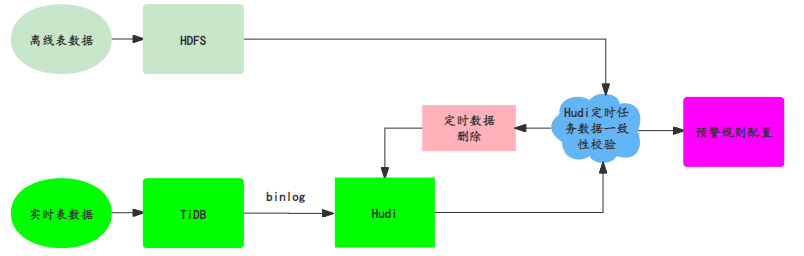
����4.3.2 ��������
������������
�������й�˾�Զ���Ԥ����㡢�澯��̨������ƽ̨�ȹ��ߣ��ɽ����ε���Ϣ�����Ƿ��ӳ١����Ƿ��쳣�ȹؼ�ָ����м��Ԥ����
������ǰ����
�����ɽ����ݴ�����������¡��ӳ١���ѹ����Դ�ȹؼ�ָ����м��Ԥ����������������ʱ���쳣
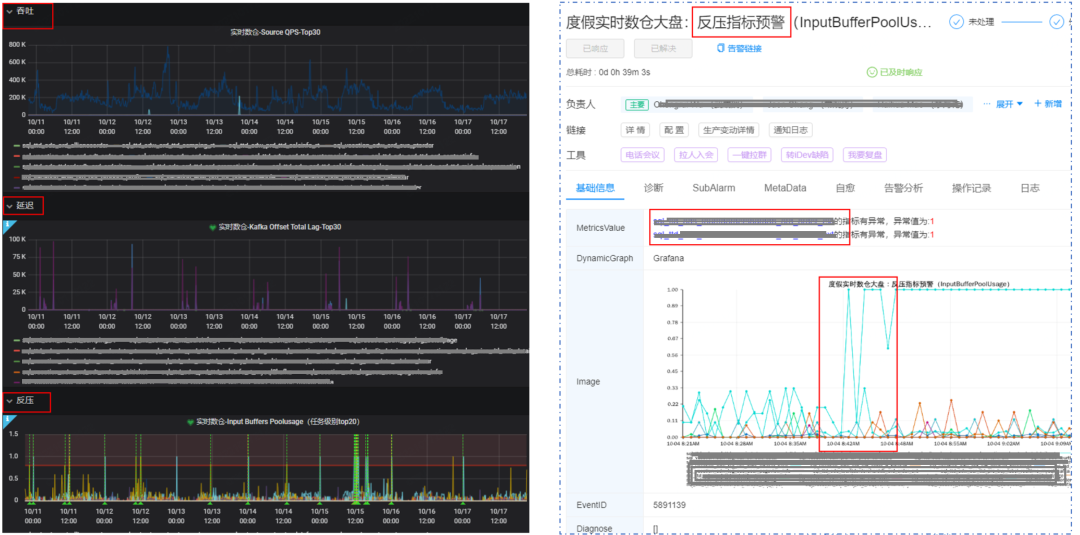
����4.4 ���ݹ���
������ģ��ɽ����ݴ����������ȸ�ģ����д������ṩ���ӻ��Ĺ���ƽ̨���磺��ѪԵ/������Ϣ��DQC���á�����״̬����صȡ�
������ͼΪ�����ݱ�������������������ѪԵ��ϵ��
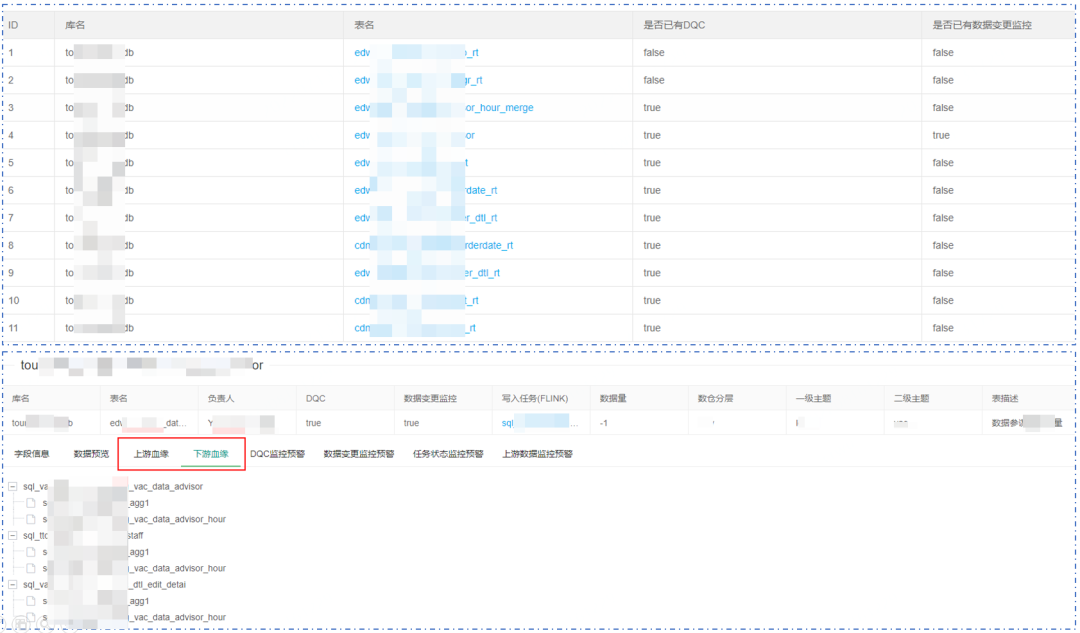
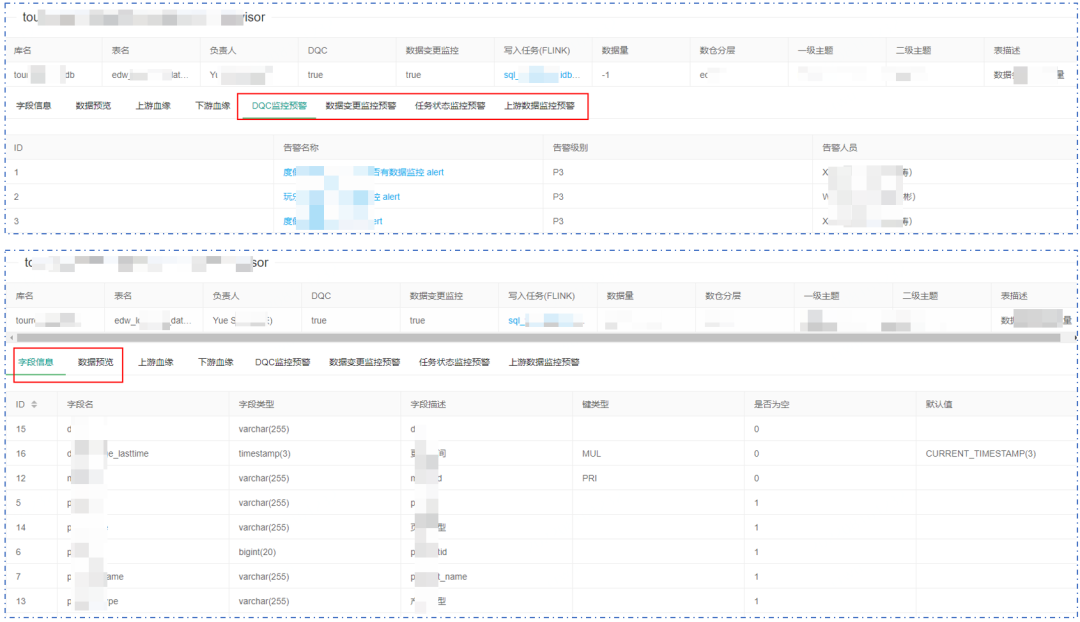
������ͼΪ���ݱ�������Ϣ����
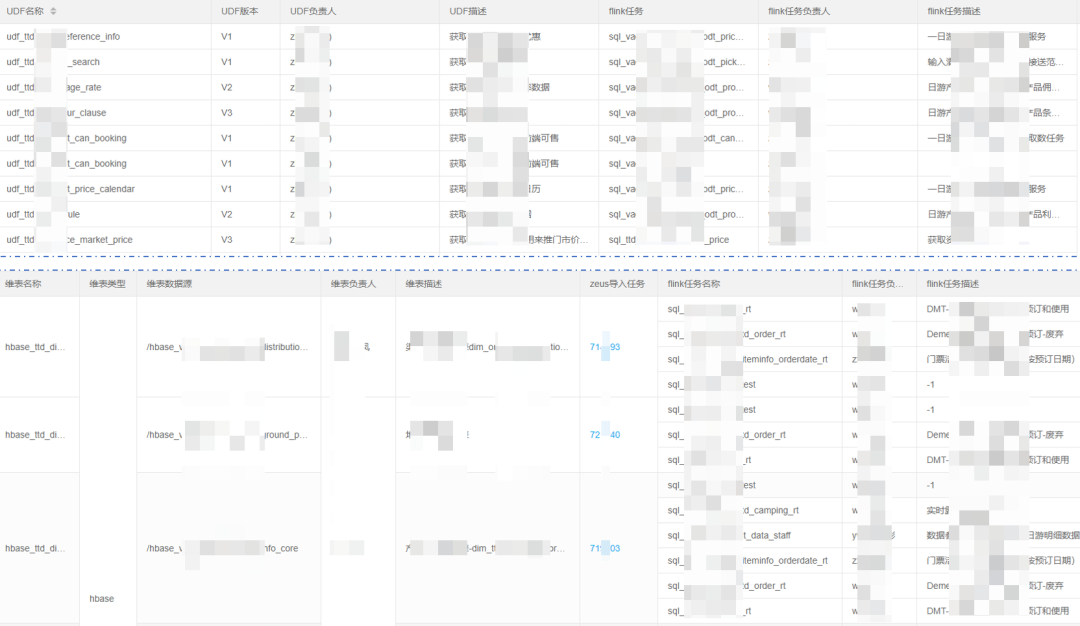
������ͼΪ����UDF���Ļ�����Ϣ����
�����塢չ��
����Ŀǰ��ϵͳ�������Ѿ��ܳн��ŶӾ���������ݿ������������ǻ��ڿɿ��ԡ��ȶ��ԡ������ԵȲ������̽������������������������ϵ�������Զ����ݻָ����ߡ�������ά����������������һ�廯̽���ȡ�
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
