��������Transformer�Ĵ�����ģ��(LLM)���к�ǿ������������������LLMһ���ܹ���ȡ���ı�����Ȼ�ܵ��������ơ�
�������������Ĵ��ڽ�С�⣬LLM�����ܻ������������ݳ��ȵ����Ӷ��½���������������δ����ģ�͵������Ĵ��ڳ�������Ҳ����ˡ�
�������֮�£�����ȴ�����Ķ�������������ܳ����ı���
����LLM���������Ķ������ϴ��ڲ������Ҫԭ�������Ķ�������LLM���ֵ����뾫ȷ�����ݣ����Ҹù�����Ա���;������ȷ����Ϣ�����ᱻ���������Ķ����̸�ע������ģ����Ҫ����Ϣ����������ȷ���ʵ������ܼ������ʱ�䡣
���������Ķ�Ҳ��һ�������Ĺ��̣�����ش�����ʱ����Ҫ��ԭ���н��м�����
����Ϊ�˽����Щ���ƣ�����Google DeepMind��Google Research���о���Ա�����һ��ȫ�µ�LLMϵͳReadAgent����������ν���ʽ�Ķ����ĵ�������������Ч�����ij���������20����

�����������ӣ�https://arxiv.org/abs/2402.09727
���������ཻ��ʽ�Ķ����ĵ����������о���Ա��ReadAgentʵ��Ϊһ������ʾϵͳ��ʹ��LLMs�ĸ����Թ��ܣ�
����1. ��������Щ���ݴ洢�ڼ���Ƭ��(memory episode)��;
����2. ������Ƭ��ѹ���ɳ�ΪҪ�����ļ��Ƭ�μ��䣬
����3. ���ReadAgent��Ҫ�����Լ������������ϸ�ڣ����ȡ�ж�(action)������ԭʼ�ı��еĶ��䡣
������ʵ�������У���ȼ�����ԭʼ�������ġ�Ҫ�����(gist memories)������ReadAgent���������ĵ��Ķ���������(QuALITY��NarrativeQA��QMSum)�ϵ����ܱ��ֶ����ڻ��ߣ�ͬʱ����Ч�����Ĵ�����չ��3-20����
����ReadAgent���
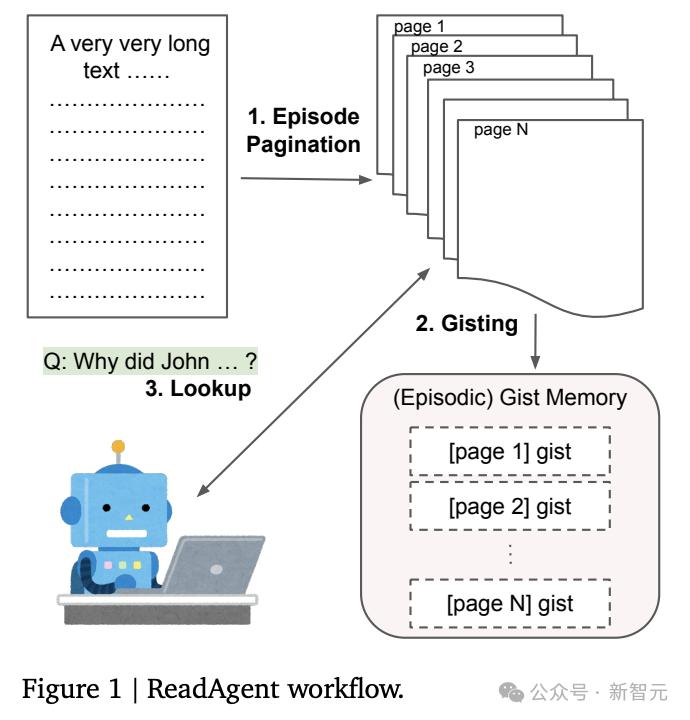
����1. Ҫ�����(gist memory)
����Ҫ�������ԭʼ�����������ı���Ķ�Ҫ������ϣ�����gist�������������裺��ҳ(pagination)�ͼ�����Ҫ(memory gisting)��
����Ƭ�η�ҳ(episode pagination)
������ReadAgent�Ķ����ı�ʱ��ͨ��ѡ����ͣ�Ķ���λ���������ڼ���Ƭ���д洢��Щ���ݡ�

����ÿһ������ΪLLM�ṩ�����ı�������һ����ͣ�㿪ʼ�����ڴﵽ���������ʱ����;��ʾLLMѡ�����֮����ĸ��㽫����Ȼ����ͣ�㣬Ȼ��ǰһ���͵�ǰ��ͣ��֮���������Ϊһ��episode��Ҳ���Խ���ҳ(page)��
����������Ҫ(memory gisting)
��������ÿһҳ����ʾLLM��ȷ�е���������ΪҪ���ժҪ��

����2. ���к�˳������
��������Ҫ�������ҳ��أ�����ֻ����ʾLLM���ҳ���һҳ�����Ǵ𰸣����ڸ����ض������������ٴ��Ķ�����Ҫ�����ֲ��Ҳ��ԣ�ͬʱ���в�������ҳ��(ReadAgent-P)��ÿ�β���һ��ҳ��(ReadAgent-S)��
����ReadAgent-P
��������˵�����ʴ������У�ͨ�����LLM����һ�����Բ��ҵ����ҳ������Ҳ��ָʾ��ʹ�þ������ٵ�ҳ�棬�Ա��ⲻ��Ҫ�ļ��㿪��������Ϣ(distracting information)��

����ReadAgent-S
����˳����Ҳ����У�ģ��һ������һҳ���ھ���չ��(expand)�ĸ�ҳ��֮ǰ���Ȳ鿴֮ǰչ������ҳ�棬�Ӷ�ʹģ���ܹ����ʱȲ��в��Ҹ������Ϣ��Ԥ����ijЩ��������±��ֵø��á�

��������ģ�͵Ľ�������Խ�࣬�����ɱ�ҲԽ�ߡ�
����3. ���㿪���Ϳ���չ��
����Ƭ�η�ҳ��������Ҫ�ͽ���ʽ������Ҫ����������Ҳ����DZ�ڵļ��㿪���������忪����һ��С��������Լ����ʹ�ø÷����ļ��㿪���������볤�ȵ����Ӷ�����������
�������ڲ��Һ���Ӧ���������Ҫ��(conditioned gists)����ȫ�ģ�������ͬһ�������е�����Խ�࣬�ɱ�Ҳ��Խ�͡�
����4. ReadAgent����
������ʹ�ó��ı�ʱ���û����ܻ���ǰ֪��Ҫ�������������������£���Ҫ�����������ʾ�а�������������ʹ��LLM���Ը��õ�ѹ���������ص���Ϣ���Ӷ����Ч�ʲ����ٸ�����Ϣ��������ReadAgent
������ͨ�õ����������£�������Ҫʱ���ܲ�֪�����������߿���֪�������Ҫ����Ҫ���ڶ����ͬ����������ش�����ı�������ȡ�
������ˣ�ͨ���ų�ע�Ჽ���е�����LLM���Բ������㷺���õ���Ҫ�������Ǽ���ѹ�������Ӹ���ע��������Ϣ����������ReadAgent��
������ƪ������ֻ̽�������������ã�����ijЩ����£��������ÿ��ܸ������ơ�
����������Ҫ(iterative gisting)
��������һ�κܳ����¼���ʷ������Ի��ȣ����Կ���ͨ��������Ҫ����һ��ѹ���ɼ�����ʵ�ָ����������ģ���Ӧ������Ļ����ɼ����ģ����
����ʵ����
�����о���Ա������ReadAgent���������������ʴ���ս�еij��ĵ��Ķ�����������QuALITY��NarrativeQA��QMSum��
������ȻReadAgent����Ҫѵ�������о���Ա��Ȼѡ����ѵ�����Ͽ�����һ��ģ�Ͳ�����֤�����Ժ�/�����Ͻ����˲��ԣ��Ա�������ϵͳ�������ķ��ա�
����ѡ�õ�ģ��Ϊָ�������PaLM 2-Lģ�͡�
��������ָ��Ϊѹ����(compression rate, CR)�����㷽�����£�

����LLM������
����NarrativeQA��QMSum����һ������������ʽ�IJο��ظ���ͨ��ʹ������ROUGE-F֮����ƥ�������������
��������֮�⣬�о���Աʹ���Զ�LLM��������������Щ���ݼ�����Ϊ�˹����������������

��������������ʾ�У����ϸ�LLM��������ʾ�������ж��Ƿ���ھ�ȷƥ�䣬������LLM��������ʾ�������ж��Ƿ���ھ�ȷƥ���ƥ�䡣
�������ڴˣ��о���Ա�������������ָ�꣺LLM-Rating-1(LR-1)��һ���ϸ��������������������ʾ���о�ȷƥ��İٷֱ�;LLM-Rating-2(LR-2)���㾫ȷƥ��Ͳ���ƥ��İٷֱȡ�
�������������Ķ�����
����QuALITY
����QuALITY��һ����ѡ�ʴ�����ÿ����������ĸ��𰸣�ʹ�����Զ����ͬ��Դ���ı����ݡ�

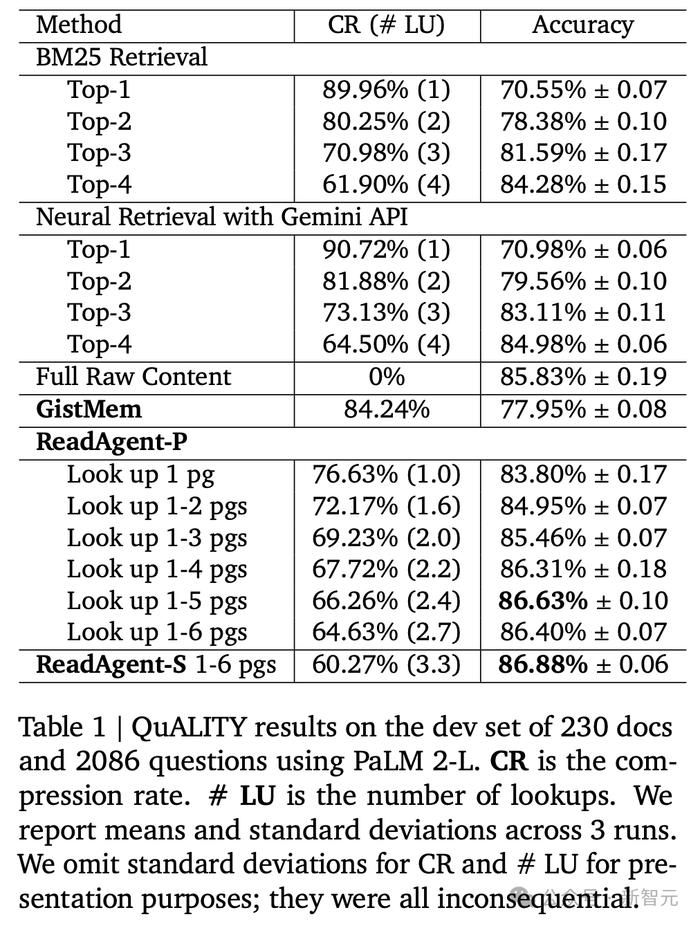
����ʵ������ʾ��ReadAgent(����1-5ҳ)ʵ������õĽ����ѹ����Ϊ66.97%(����Ҫ�������Ĵ����п�������3����token)��
�����������������ҵ����ҳ��(���5ҳ)ʱ�����ܻ�����;��6ҳʱ�����ܿ�ʼ�����½�����6ҳ�����Ŀ��ܻ����Ӹ�����Ϣ��
����NarrativeQA
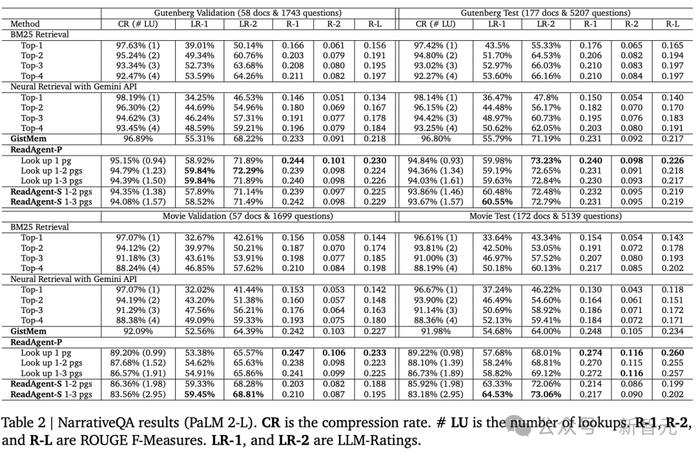
�����������Ķ��������ݼ��У�NarrativeQA��ƽ�������ij������Ϊ�˽�gists���������Ĵ��ڣ���Ҫ��չҳ��ijߴ��С��
������Ҫ��Gutenburg�ı�(�鼮)��ѹ����Ϊ96.80%���Ե�Ӱ�籾��ѹ����Ϊ91.98%
����QMSum
����QMSum�ɸ�������Ļ����¼�Լ���������˵����ɣ����ȴ�1,000�ֵ�26,300�ֲ��ȣ�ƽ������ԼΪ10,000�֣������������ʽ���ı�����������ָ����ROUGE-F

�������Կ�����������ѹ���ʵĽ��Ͷ���ߣ���˲��Ҹ���ҳ��ļ��������Ȳ��Ҹ���ҳ��ļ������ø��á�
���������Կ���ReadAgentS�������ReadAgent-P(�Լ����л���)�����ܸĽ��Ĵ����Ǽ����ε���������������������
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
