����ɱ����!һҹ֮�䣬ȫ����ǿ�˲��ģ̬ģ���ٴ�ˢ�£�����8B�����������˶�ģ̬���ް�Gemini Pro��GPT-4V�����ң���OCR����ͼʶ��ˢ��SOTA��ͼ������ٶȱ���150�������ǹ���ͷ����ģ��˾������������������520���
����ȭ��GPT-4V������Gemini Pro������8B�������ܻ��ܶ�ģ̬��ģ�����ߡ�
�������죬���ȫ����ǿ�˲��ģ̬ģ�ͳ��ס�ɱ���ˡ�!
����������֪���˲�ģ����AI��չ�Ĵ�����——�������ȸ��ٵ�ƻ����Ӣ�ض���ȫ��Ƽ���ͷ����������PC���ֻ��ȶ˲ೡ����AI��ء�
����������û�뵽���ǣ��˲�ģ�͵����ܾ�Ȼ������ô�ͣ������ٶȾ�Ȼ������ô��!
���������˾�ϲ���ǣ����������Թ�������dz��Թ��ڴ�ģ���з�ʵ����ͷ���Ĺ�˾�������——�������´��������С����MiniCPM-Llama3-V 2.5��
�������ң�ѡ���ڽ���520�������������Ƴ�����˵������Դ���������˽������ֱ�����IJ�����Ƽ���˾~

����MiniCPM-Llama3-V 2.5��Դ��ַ��
����https://github.com/OpenBMB/MiniCPM-V
����MiniCPMϵ�п�Դ��ַ��
����https://github.com/OpenBMB/MiniCPM
����Hugging Face���ص�ַ��
����https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5
������ô���С���ھ����ж�ǿ?�����ܵ�������ȫ����ǿ�˲��ģ̬ģ�͵ijƺ�?
�����ܽ�������MiniCPM-Llama3-V 2.5����֧��30+�������ԣ����һ��߱���
������ǿ�˲��ģ̬�ۺ����ܣ���Խ��ģ̬���ް�Gemini Pro��GPT-4V;
����OCR����SOTA!9�����ظ���������ͼ��ͼ���ı���ʶ��;
����ͼ������150��!�״ζ˲�ϵͳ����ģ̬���١�
������������ͼ��ӳ����ȫ��Χ�ڣ�С�����������ܵĶ�ģ̬��ģ���Ѿ���Ϊ����;
���������������۵�һ�����������С����MiniCPM-Llama3-V 2.5��
����MiniCPM-Llama3-V 2.5��ʵ��֤����——ģ�Ͳ���ֻ�С�����Խ���������Խ�á������ǿ�������С�����˶���ǿ����!

�����������Ŵ�ģ�Ͳ������潵�͡��˲�����������ǿ�������ܶ˲�ģ����ͷǿ����
�������ֻ���PC�������ն��豸�����Ƶ��Ӱ���Ӿ����������ڶ˲ಿ��AIģ������˸��ߵĶ�ģ̬ʶ������������Ҫ��
��������ڡ�С���ڡ�������������Ѹ�ͽ����������ƶ������ɱ�������͡���ģ��Ч��أ�ʤ��������
����OCR����SOTA+��ǿ�˲��ģ̬
����8B�˲�ģ�ͣ���ԽGPT-4V��Gemini Pro
������һ�Σ�MiniCPM-Llama3-V 2.5��8B�˲�ģ�Ͳ��������������˾��� OCR(��ѧ�ַ�ʶ��)SOTA�ɼ����Լ��˲�ģ���е���Ѷ�ģ̬�ۺϳɼ���þ�����ˮƽ��

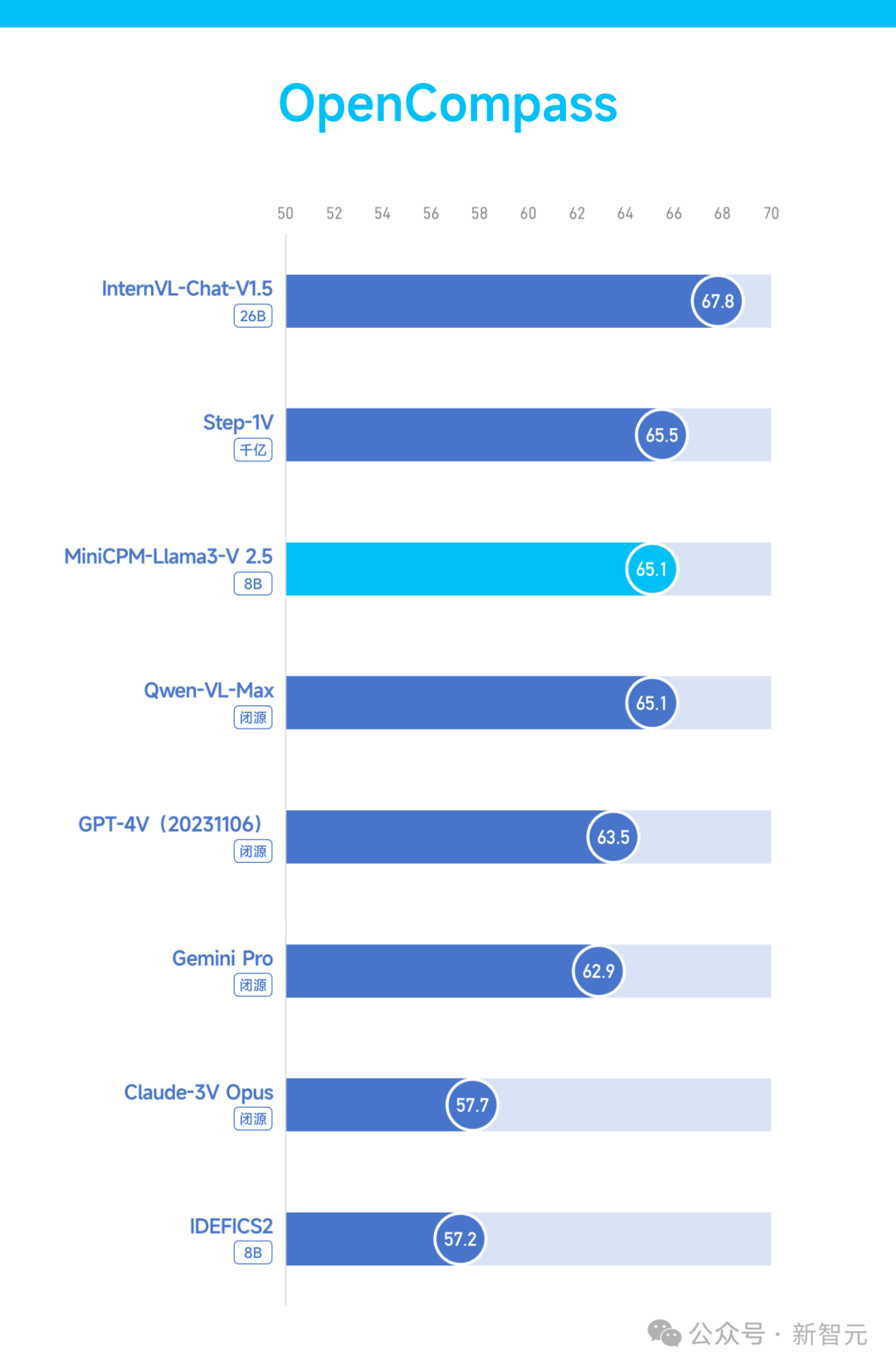
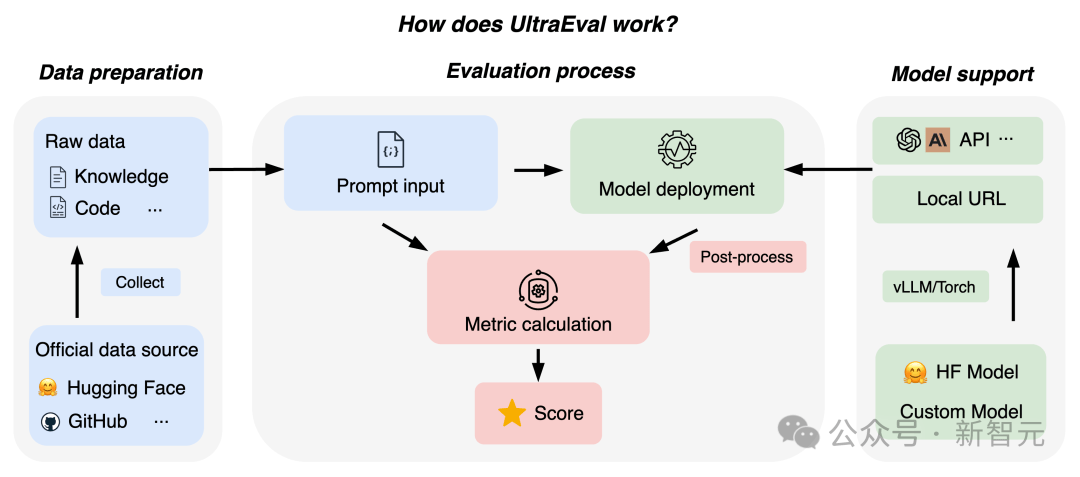
����ģ���״�ͼ��MiniCPM-Llama3-V 2.5�ۺ�����ˮƽȫ������
�������ۺ�����Ȩ��ƽ̨OpenCompass�ϣ�MiniCPM-Llama3-V 2.5��С�����ۺ����ܳ�Խ��ģ̬���ް�GPT-4V��Gemini Pro��
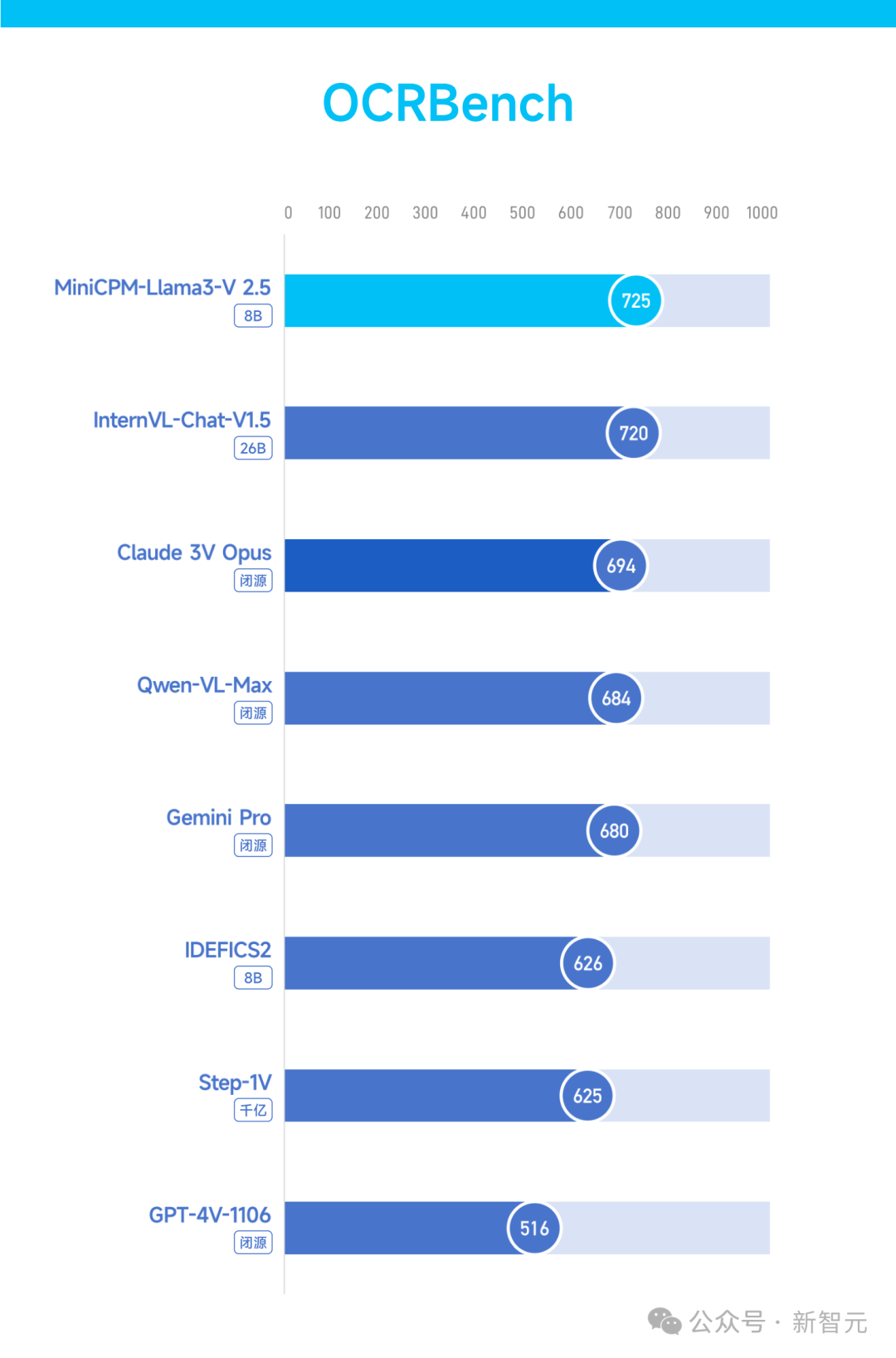
����OCR(��ѧ�ַ�ʶ��)�Ƕ�ģ̬��ģ������Ҫ������֮һ��Ҳ�ǿ����ģ̬ʶ��������������Ӳ��ָ�ꡣ
������һ��MiniCPM-Llama3-V 2.5 ��OCR�ۺ���⼒Ȩ����OCRBench�ϣ�Խ����Խ��Claude 3V Opus��Gemini Pro�ȱ��ģ�ͣ�ʵ��������SOTA��
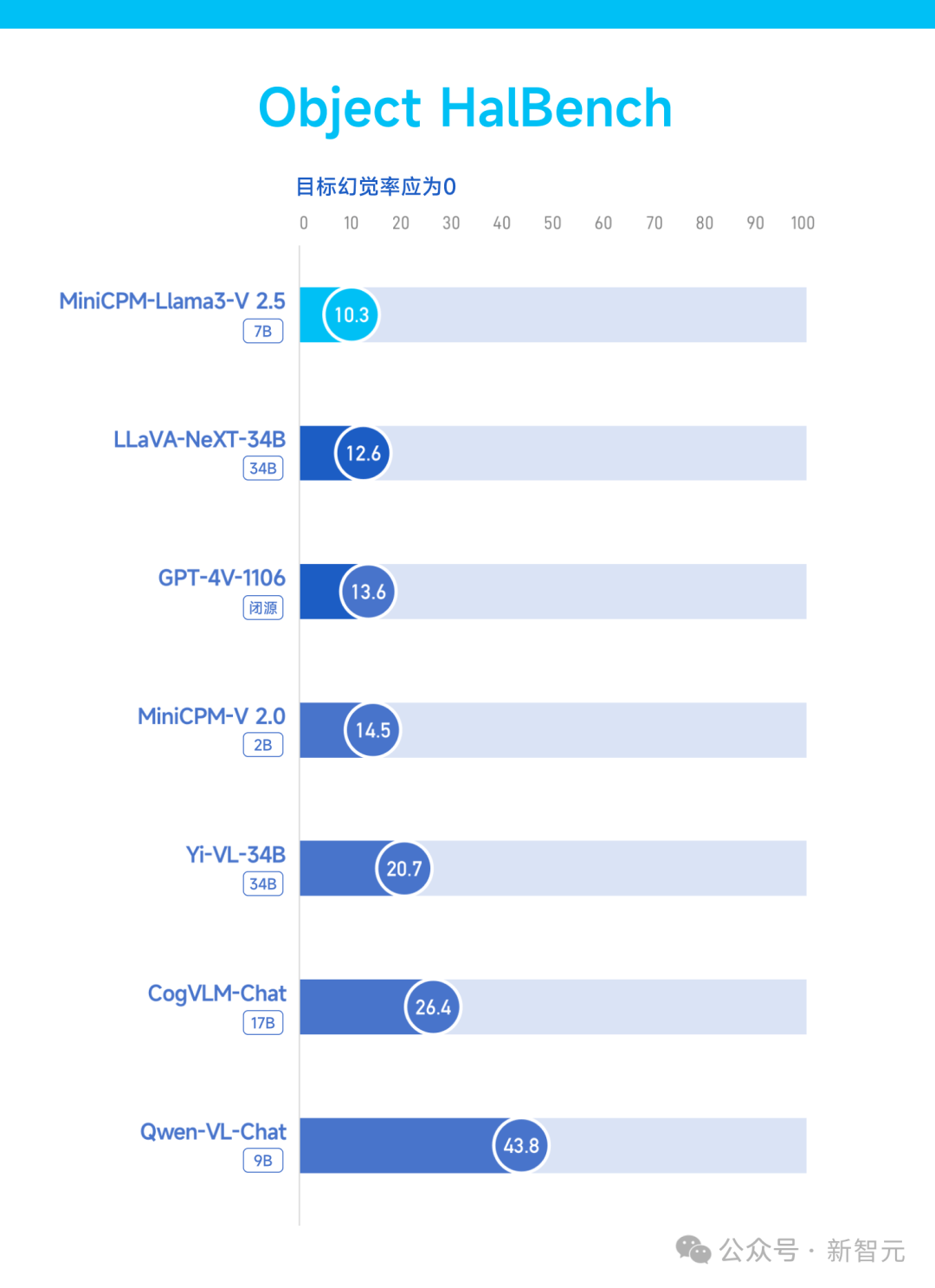
������������ģ̬��ģ�����ܿɿ��Ե���Ҫָ��——�þ������ϣ�MiniCPM-Llama3-V 2.5��Object HalBench���ϳ�Խ��GPT-4V���ڶ�ģ��(ע��Ŀ��þ���ӦΪ0)��
������������ģ̬ģ�͵Ļ�����ʵ����ռ�����������RealWorldQA���ϣ�MiniCPM-Llama3-V 2.5�ٴγ�ԽGPT-4V��Gemini Pro�����8Bģ�Ͷ������ܿɹ�

������150��!�״ζ˲�ϵͳ������
����֧��30+�����ԣ�ӵ�����翪Դ����
�����״ν��ж˲�ϵͳ�����٣�MiniCPM-Llama3-V 2.5�Ѹ�Ч�����ֻ���
������ͼ����뷽�棬����״�����NPU��CPU���ٿ�ܣ���MiniCPM-Llama3-V 2.5ͼ����뷽��ʵ����150������������
����������ģ���������棬Ŀǰ��Դ�����ı�������ʾ��Llama 3����ģ�����ֻ��˲�Ľ����ٶ���0.5 token/s���£����֮�£���ģ̬��ģ�͵Ķ˲����������Ÿ����Ч����ս������CPU�������Ż����Դ�������Ż���ʽ����ڽ� MiniCPM-Llama3-V 2.5���ֻ��˵����Խ����ٶ�������3-4 token/s��
����Ŀǰ������ģ�͵�ͼ��������Ҳ�ڽ����У��������������鼴��������

����(�˴�GIFΪ2������ʾ���������һ�������Ż���)

����(�˴�GIFΪ2������ʾ���������һ�������Ż���)
�����б��ڳ�������Ӣ˫��ģ�ͣ�MiniCPM-Llama3-V2.5��֧��30+�������ԣ�
���������������������������������������ԣ���������һ��һ·���ҡ�
�����������еĿ����Է�����������ͨ����������Ķ�ģ̬���ݵ�ָ�������ͿɶԶ����Զ�ģ̬�Ի����ܸ�Ч������
�������ڣ��ϰٸ����ҵļ�ʮ���˿ڣ����ڿ�������ʹ��ĸ��Ͷ˲��ģ�ͽ���������������ǰ�ؿƼ���չ�����ߣ�Ҳ������и���AIӦ����ء�����Ʒ�����������Ƽ�����Ŀ����ԡ������ø��������ܴ�ģ�͵���Ȥ!
������������չʾ(���Լ��ٹ������ڽ��У��˴�Ϊ2����)
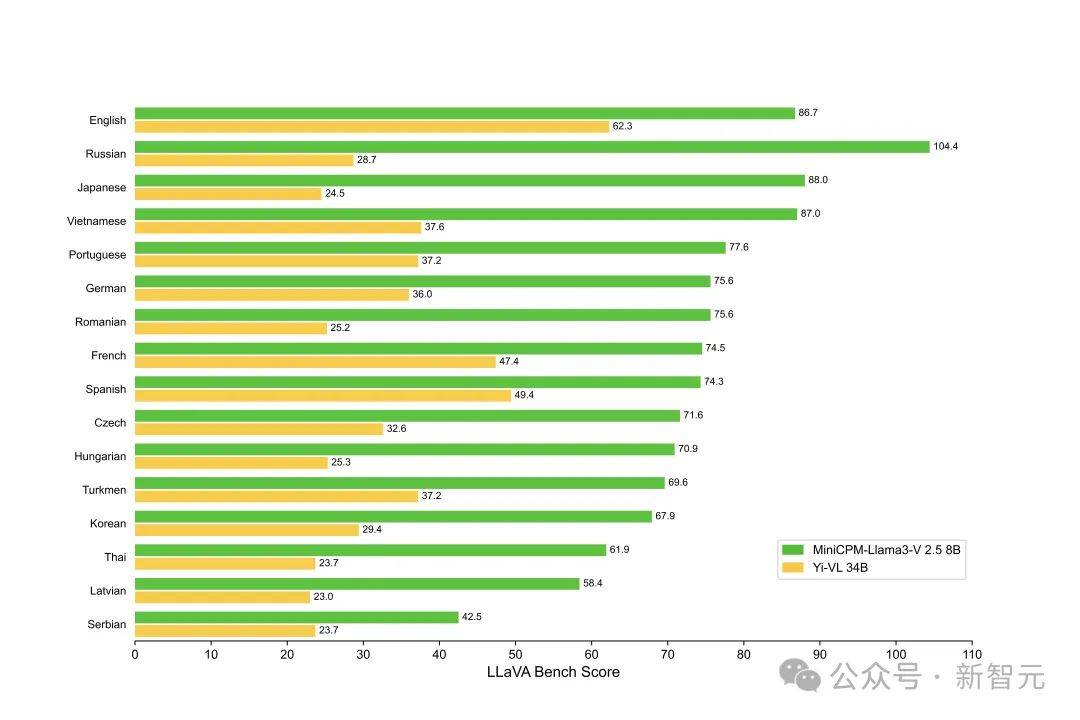
���������汾LLaVABench��������MiniCPM-Llama3-V 2.5�Ի�������ʤһ��
����9�����ظ�����
������ͼ��ͼ���ı���ʶ��
����OCR������һ����ĥ�������������ģ̬ʶ�������ٽ�����MiniCPM-Llama3-V 2.5������ͼ����ͼ�����ı��ľ�ʶ���ٶȴ������ڱ���!
����������и���ͼ���Ч���뼼�������Ը�Ч���뼰����ʶ��180���������ͼƬ������֧�����ⳤ���ȡ��������е��̬����1:9���ޱ���ͼ��ͻ���˴�ͳ��������ʶ��20������Сͼ��ƿ����
������ǰ��MiniCPM-Vϵ�ж�ģ̬ģ�;�����ڽ־�����ͼ�����ѳ����ĸ�Ч������Ӯ�������ÿڱ���

��������������MiniCPM-Llama3-V 2.5�ڸ������������Ͻ�һ��ͻ�ơ��ɸ��õ����붴��ͼ���ڸ����ӡ����ӽ������ˮƽ�Ͻ���˼���ͽ�����⣬���ƴ�ģ���еġ�С����Ħ˹����
����������������ʹ��ģ�Ͳ��������ⵥ���ı���ͼ���ģ̬��Ϣ�����ܿ�Խ��ͬģ̬����ۺ���Ϣ��������ȷ������ķ�����
�����������һ�ų��������ּ��Ľ����羰ͼ���������۱�𣬵�MiniCPM-Llama3-V 2.5�ܹ�һ�ۿ������еġ����塷���⣬������ȷ��������Щ������Ϊ�˼�����塷������й��ƻ���ѧ�Ĺ�����ƣ����˻���һЦ��
������ͬ����������GPT-4V������������롣
�������⣬ʶ�����������������ͼ�Ƕ�ģ̬ģ������������ֱ�����֣�MiniCPM-Llama3-V 2.5�����ܹ����ɿ�������ͼ�в�ͬģ������֡���ͷ֮��Ŀռ�λ�ú�������ϵ�����ܸ����������Ľ���˵����

����������ת��һ��������ʳ������ͼ������������Ӣ��?
����MiniCPM-Llama3-V 2.5ƾ���ɫ���������������������������ͼ�������ʳ���ͺͷֲ������ܶ��챳���Ӫ���������������ܻ�������ϣ�ֱ��һ�����������Ƽ�������һ�ܵ�����ʳ�ס�


����ȫ��OCR�������棬�ṹ����Ϣ��ȡ���������������ڳ�ͼ���ı��ľ�ʶ����а�����
������������һ�Ű���������Ϣ�ij��ij�ͼ��MiniCPM-Llama3-V 2.5һ�ֲ����ʶ�����ȫ�ġ�

�������»����鿴

�����ٸ�һ��Ҫ���ĺü�����ͼ�ĸ��ӽ����ij�ͼ��ͼ���ı���MiniCPM-Llama3-V 2.5 Ҳ�ܾ�������ȷ�Ļش�

�������»����鿴

����������һ���ֻ�����Ļ�Ʊ��MiniCPM-Llama3-V 2.5 Ҳ��ȷ��ȡ��Ϣ����������ġ�json����ʽ�����

�����������ǿ�Դ���������Ĺ����ߣ�Ҳ�������ߡ�
��������MiniCPM-Llama3-V 2.5�ķ�Ծ��������������ŶӶԶ�ģ̬�����Ĵ��´�ĥ�����벻��Llama3-8B-Instruct��Ϊ����ģ�͵����ܻ�����
������л��������ͬ�е�Խ������������վ�ڱ˴˵ļ���ϣ�����ժ�ǣ�ָ����ߡ����貵Ŀ�ѧ����֮����
��������Ҳ�������ر���������Դ��������ģ�͡����ݡ�infra���ߵȣ�����Դ���ŵ��ǻ�������Э������֮��
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
