��������оƬ��“����֮��”��ȷʵ˺����һ�����ӡ�
�������µ�AI�����ϣ�Ӣΰ������������ҫ��һ�����ǡ�
����ʮ��������Ӣΰ���������ܹ�ִ�и���AI����(��ͼ���沿������ʶ��)��оƬ���棬�����˼�����������*��λ��
����Ȼ�����������б仯��
�������ڣ����Źȸ衢IBM�Ⱦ�ͷ��ʼ��оƬ����һ�뷢����GPU����ľ�����֣���ʼ����Щ��ĸı䡣
���������IBM�Ƴ�һ��ȫ�µ�14nmģ��AIоƬ��Ч�ʴﵽ����*GPU��14����
������*�����㣬���ǽ�����������������������еĹؼ��������������ܺġ��Ӷ�*�ȵؼ��������ڼ����ϻ��ѵ�ʱ��;�����
����ͬ���ģ���Ϊ�Ƽ���ͷ�Ĺȸ裬Ҳ��8�µ�GoogleCloudNext2023����ϣ�������һ��ȫ��AIоƬCloudTPUv5e��רΪ��ģ��ѵ����������ơ�
����������˵��CloudTPUv5e�������256��оƬ�������ۺϴ�������400Tb/s��100petaOps��INT8���ܡ�
���������ٶȻ����ԣ���CloudTPUv5e��ѵ���������˹�����ģ�͵��ٶ������5����
�����ɴ˿ɼ��������ͷ��ʵ����������������������Զ��Ӣΰ��“������”������ʼ���Ƴ��˸��Ե�оƬ����Ӣΰ���GPU��Ȩ��λ������“Χ��”��
������ô����Ӣΰ������Ļ��Ǻ���ǰ����������սǰ���������?
����01 “����”��Զ��
����Ӣΰ��Ľ�ɽ���������?
������ij�̶ֳ���˵����������µģ���������Ӣΰ�ﱾ���Ĵ������������пƼ���չ���еĶ��ɡ�
������Ϊ�������ҵ�Ļƽ��ɣ�Ħ������һֱָ����оƬ������
������������оƬ���������ٶȵķŻ���Χ������һ�������ϵ�����Ҳ�ڲ�������
������νĦ�����ɣ�ָ���Ǽ��ɵ�·�Ͽ������ɵľ������Ŀ�ڴ�Լÿ����18���µ�24���±������һ����
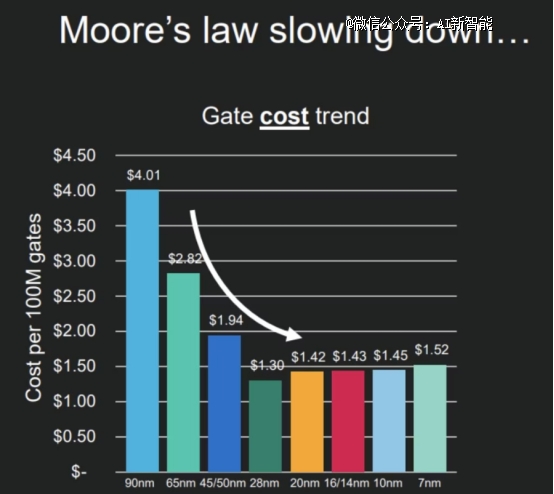
����Ȼ��������оƬ�����IJ��Ϸ�չ��Ħ��������������ƿ����
����CIC��ʶ��ѯ����¶��������оƬ�ߴ���������ޡ���̼���������ЧӦ�����ĺ�ɢ�ȡ��������������⣬��5nm��3nm�ٵ�2nm��������������2��ʱ�䡣
������������������ʹ����“������տ”���ƵĻ���ѫ��Ҳ���ò����ε�����“Ħ����������”���Ǽ������ɼ�!
��������ȥ�귢���� AD102(RTX4090) оƬ���ߴ�Ϊ 608mm������� 628mm �� GA102(RTX3090Ti)��С��
�������������ļ���·������ͳGPU���컨�壬�ƺ��Ѿ�Խ��Խ����
����Ҳ������ˣ���·��ͷ�ڽ������֮����ͬʱ��Ҳ�ڻ�����“�����辶”���ҵ�һ���б��ڴ�ͳ·�ߵ��ƾ�֮�ߡ�
����ǰ���ᵽ��IBMģ�������ṹ������оƬ�����������ij���֮һ��
����Ȼ��������Դ�ͳоƬƿ�����棬ҵ������źܶ��ֲ�ͬ�ķ�������������оƬ������оƬ������оƬ������ͬ����GPUȡ��CPU����Ϊ����AI���������һ�����ڶ��ּ���·���IJ����У�������������һ��“*”��·��ʤ������Ϊ��ʱ��ͨ�õ�оƬ��ʽ��
������������“*”·��������Ӧ��һ���ڼ�������ȡ�ͨ���Ժ��г�����ȷ��棬�������˽Ϻü�˵�һ�ַ�����
������Ŀǰ���������������оƬ������оƬ������оƬ�ȶ��������з��Σ��似������Ȼ��д�ʵ���ļ��顣
�������⣬����оƬ������оƬ������оƬ�ȶ�������ض��ļ����������Ƶģ�����ͨ���ԡ��������ϣ�������������һ���IJ��㣬
������������оƬ�ʺϽ��һЩ�����������Խ������Ҫ���⡣����оƬ�ʺϽ��һЩ�������ݴ����ʹ�������⣬���ͨ�š��⻥���������ȡ�
�������ۺϱȽ�������Ŀǰ���п���ʤ���ķ��������Ƕ���оƬģ����ϵ����칹���㡣
����02 �µ�����
����ʲô�dz��칹����?
��������˵��������һ��ƴͼ��Ϸ���Ѳ�ͬ��оƬģ��(��CPU��GPU��FPGA��)���ղ�ͬ�Ĺ����Ŀ����ƴ�ӣ��γɲ�ͬ�ļ��㷽�����Ӷ�������ͬ���͵����ݺ������صļ�����
�������칹�����Ŀ����ʵ�ּ����*�����������ܡ����ġ��ӳٵȷ���ﵽ*��ƽ�⡣
������CPUͬ������Σ�100%������CPU���;
��������GPU�칹�Σ�80%������GPU��ɣ�CPUֻ���ʣ���20%�Ĺ���;
�������ڳ��칹����Σ���80%�Ĺ����ɸ������Ч��DSA��ɣ�GPUֻ���ʣ��20%������80%����16%�Ĺ�����ʣ���4%����CPU��
���������DSA����һ������ض�����ͳ����ļ��㵥Ԫ������ʵ�ָ�Ч�����ݴ������㷨���١����������紦����(NPU)��ͼ�δ�����(GPU)�������źŴ�����(DSP)���Ӿ�������(VPU)����ȫ������(SPU)�� ��
������Щ“��ҵ��ר��”���ض�оƬ���Աȴ�ͳ��GPU���졢��ʡ�硢��С�ɡ�����
������ͬʱ�����ڸ߶��ػ���DSA��̫�ʺ�����������Ĺ��������ԣ�����Ҫ�õ�һЩGPU��CPU��������Э����ЩоƬ�����ʣ�µ�һЩ���㹤����
������������“ר��רְ”�ķֹ������£�оƬ�Ϳ���ʵ�ּ����*�����������ܡ����ġ��ӳٵȷ���ﵽ*��ƽ�⡣
���������AI��ģ�͡��Զ���ʻ��Ԫ��������˵������Ӧ�ó���ʱ��AIҪ��������Խ��Խ�࣬Խ��Խ�ѣ�����ͳ��ͬ��оƬ�Ѿ�������AI�IJ��������Ը�AI�ṩ�㹻���������ٶȡ�
���������칹��������ṩ���ߵ�����ԺͿ���չ�ԣ��ܹ����ݲ�ͬ�����ݺ������أ���̬�ط���͵��ȼ�����Դ��ʵ�ּ��������Ӧ�����ܡ�
����������˵�����칹������Է�Ϊ����ģʽ����̬���칹����Ͷ�̬���칹���㡣
������̬���칹���㣬��ָ����ƽξ�ȷ���ø���������֮��ķֹ���Э����ʽ��������һЩ�ȶ��ҿ�Ԥ��ij���������Ƶ����롢ͼ������;
������̬���칹������ָ������ʱ����ʵʱ���ݺ�����������̬��ѡ��͵�������ʵĴ�������������һЩ���߱仯�ij��������Ƽ��㡢��Ե���㡢��������;
����ͨ������“�������”�ķ�ʽ�����칹����������������أ�ʵ�ָ�Ч���������ȡ�
��������֮�⣬�ӳɱ���˵�����칹����ͬ����һ����Ч���ʹ�����оƬ�ɱ��ķ�����
�������Ŵ�ͳGPUоƬ�ߴ�IJ�����С�����Ǿ���Ҫ������з�Ͷ������ܵ������豸����͵����˳ɱ���������
����֪���뵼���о�����Semiengingeeringͳ���˲�ͬ������оƬ������ã�����7nm�ڵ���Ҫ�ķ����Ѿ��ﵽ��2.97����Ԫ;
���������칹���㣬ȴƾ�����оƬ�����ķֹ���Э��������ؽ������һ���⡣
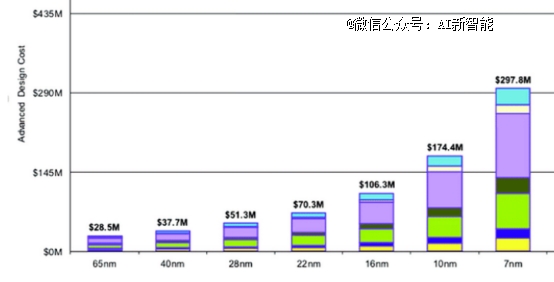
������һ������ı�����˵����ͳGPUоƬ������һ���ܳ���Ҫ�������ܵø��죬����Ҫ���ϵظĽ�����������̥��ɲ���Ȳ������������ɱ���ɱ�������
���������칹���������һ����������������Ը��ݲ�ͬ��·���������л���ͬ������ģʽ����ԽҰ�����䡢�ؿ͵ȣ����һ�����Ͳ���һζ�ظĽ�������(��СоƬ�ߴ�)����������ˡ�
����03 �������
���������������������ƣ����칹���㲻��ͻ���˴�ͳGPU��ƿ��������Ҳ���˹���������оƬ�ṩ��“�������”����ʷʱ����
������Ŀǰ�������ڳ��칹����������ϣ�Ӣΰ��Ⱦ�ͷ�IJ���Ҳ�dz�������ȫ�棬�Ƴ���Hopper����оƬ����GraceCPU��BluefieldDPU���ɣ�����һ�������ij��칹ϵͳ��
���������ڳ���Ҳͬ����ʼ����һ��������˷������绪Ϊ�Ƴ�������920������������һ�����ARM�ܹ��ĸ�����CPU�������뻪Ϊ���еĕN�� AI оƬ������ AI оƬʵ���칹Эͬ��֧���ơ��ߡ��˵ȶ��ֳ�����
��������һЩ���ڳ���Ҳ���з��Լ��ij��칹оƬ�������Ϲ�չ���Ƴ��˻��� T7520������������һ�����CPU��GPU��NPU��ISP�ȶ��ּ��㵥Ԫ�ij��칹оƬ��רΪ5G�ն˶���ơ�
������������˵�����칹�����Ƿ�������оƬ�����ṩ��������Ļ��ᣬ��Ҫȡ�������¼������أ�
����·����оƬ�����ڲ�ͬ���͵ļ��㵥Ԫ�ϵļ���ˮƽ�;�����������CPU��GPU��DPU��FPGA�ȣ��Լ�����֮���Эͬ���Ż�������
����·����оƬ�����ڸ��ٻ������Ƚ���װ����Ĵ��������ͳɱ��������������� 2.5D��3D�ѵ��������Լ��Բ�ͬ���սڵ�ͼܹ��ļ����ԺͿ���չ�ԡ�
����·����оƬ������ͳһ����ƽ̨����Ŀ�����������̬��������������֧�ֶ����칹�豸�ı�̿�ܺ���ƽ̨���Բ�ͬ������Ӧ�õ�����������
���������������棬Ŀǰ�Ĺ�����ҵ��Ȼ��һ����̽���ͽ�չ����������ԣ������ٲ�С����ս��
�������磬��ͬ���͵ļ��㵥Ԫ�ϵļ���ˮƽ�ϣ������Դ�����һ���Ķ̰壬���绪Ϊ������920��������Ȼ�����������������������ڼ����Ժ���̬���滹�в��㡣
�����ڸ��ٻ������Ƚ���װ���棬����2.5D��3D�ѵ��ȹؼ�������Ŀǰ����оƬ���̻�û����ȫ���գ����һ������ڹ��Ӧ�̡�
������Ŀǰ���ڳ���Ŀǰͻ��*��Ҳ*DZ���ķ���������ƽ̨�Ŀ��������ϡ�
������Ϊ�����칹�����Ӳ�������Ժ����ԣ��������ߴ����˺ܴ����ս��
���������һ��ͳһ������ƽ̨���������εײ��ϸ�ڣ��ṩ��Ч�ı��롢���ȡ��Ż��ȹ��ܣ���ô�Ϳ��Դ�Ϳ����ߵĸ�������߳��칹����Ŀ����Ժ��ռ��ԡ�
�����ֽΣ������Ƶ��칹�����Ʒ���壬����GPU�Ʒ�������FPGA�Ʒ������͵��Լ��ټ���ʵ�� EAIS �ȣ��ṩ��һϵ�е��칹�������ͽ��������
��������Ϊ��Atlas�칹����ƽ̨���������еĕN��AI��������Ҳ�ṩ�˴�оƬ���Ʒ����ȫջ�칹������������
�����ۺ����ϸ������أ��Լ�Ӣΰ���������з�������һ“��̬����”���п��ǣ�δ��оƬ�г��ľ�����֣����»��������̬�ƣ�
��������оƬ����δ��5���ڳ��칹�����ϵľ���ˮƽ������һ���̶ȵ�������ͻ�ƣ������������“������”���������ǻ�����ȫ���Ѷ�Ӣΰ��ȹ����ͷ��������
������һЩ�ض��ij�����Ӧ���ϣ�����оƬ���̿�����Ӣΰ�� �Ⱦ�ͷ�γ���Ч�ľ�����������5G������������Ե�����������оƬ���̿��ܻ��Ƴ����ʺϱ��ػ�����ͻ����ij��칹������������
��������˵�����칹���㣬ȷʵΪ����оƬ��“����֮��”˺����һ�����ӣ����ӳ�Զ������Ҫ����ȫ���“������”���⣬����Ӣΰ��Ⱦ�ͷ�γɶԵȾ���������һ�����ص�Զ�Ĺ��̡�
�����������ݽ����Ķ���������Ͷ�ʽ��飬������Դ���Ͷ���߾ݴ˲����������Ե���

��ʮ�Ĵ�Ӣ�ض�® ���™ ������(����Raptor Lake S Refresh)�������Ƚ���Intel 7�Ƴ̹��ա�

��ά����(AVC)����������ʾ��2024��1-9�������������۶�94.2��Ԫ��ͬ������3.1%�����ж��������������죬ͬ����14%���Ƿ�����ͳ���������»���ͬ�Ƚ���2.3%��

����ǰ��Ҫȥ���ڰ죬һ������������Ҫ������ˣ����ڷ������!�������칫������С��������ʾ�����ύ��ز��ϣ��������ӣ�����������ij���˻��ʹ����21600Ԫ��

��˶ProArt����27 Pro PA279CRV��ʾ����ƾ����������������ú;���ɫ�ʳ���������Ϊ���Ĵ�����������ʵ���Եİ�����˫ʮһ�ڼ����2799Ԫ���Լ۱Ⱥܸߣ���ֱ�Ǵ������ǵ���ѡ��

9��14�գ�2024ȫ��ҵ��������ᡪ����ҵ��������ʶ����ר����̳�������ɹ��ٰ졣
