ЎЎЎЎөј¶БЈәJuiceFS КЗТ»ёцОӘФЖ»·ҫі¶шЙијЖөД·ЦІјКҪОДјюПөНіЈ¬ФЪ 2021 ДкіхҝӘФҙә󣬹эИҘТ»ДкФЪҝӘФҙЙзЗшАп·ўХ№әЬҝмЈ¬ТІКЬөҪБЛәЬ¶а№ШЧўЎЈұҫҙО·ЦПнПЈНыИГҙујТБЛҪв JuiceFS өДЙијЖұіҫ°ЎўЙијЖАнДоЈ¬ТФј°ЛьДЬ№»ОӘҝӘ·ўХЯҙшАҙөД°пЦъәНјЫЦөЎЈ
ЎЎЎЎҪсМмөДҪйЙЬ»бО§ИЖПВГжЛДөгХ№ҝӘЈә
ЎЎЎЎОДјюҙжҙўөД·ўХ№
ЎЎЎЎФЖКұҙъөДНҙөгУлМфХҪ
ЎЎЎЎJuiceFS өДЙијЖХЬС§
ЎЎЎЎJuiceFS өДК№УГіЎҫ°
ЎЎЎЎ01 ОДјюҙжҙўөД·ўХ№
ЎЎЎЎКЧПИОТГЗ»Ш№ЛТ»ПВОДјюҙжҙўөД·ўХ№АъіМЎЈ
ЎЎЎЎ1. ҫЦУтНшКұҙъ
ЎЎЎЎ2005 ДкЦ®З°»№КЗТ»ёцТФҫЦУтНшОӘЦчөДҪЧ¶ОЈ¬»ҘБӘНшІЕёХёХҝӘКјЎЈХвёцКұЖЪөД·ЦІјКҪОДјюПөНі»тХЯЛөОДјюҙжҙўҙуІҝ·ЦКЗИнУІТ»МеөДІъЖ·Ј¬ОТГЗДЬФЪКРіЎЙПҝҙөҪ NetAppЎўEMC »№УР»ӘОӘөДТ»Р©ҙжҙў№сЧУЎЈХвР©ІъЖ·ёшәЬ¶аУГ»§БфПВБЛТ»ёцУЎПуЈ¬ДЗҫНКЗҙжҙўКөјКЙПҫНКЗВтУІјюЈ¬ВтТ»ёцҙжҙўөД№сЧУҫНёг¶ЁБЛЎЈ
ЎЎЎЎ2. »ҘБӘНшКұҙъ
ЎЎЎЎ2005 ДкЦ®әуЈ¬ҝнҙш»ҘБӘНшФЪИ«Зт·¶О§ДЪЖХј°Ј¬»ҘБӘНшКұҙъөҪАҙБЛЎЈWeb2.0өД·ўХ№ЛЩ¶И·ЗіЈҝмЈ¬УЙөЪТ»ҙъ»ҘБӘНшДЗЦЦјтөҘіКПЦПыПўөДГЕ»§НшХҫЧӘұдіЙБЛТ»ёцЛщУРУГ»§¶јҝЙТФФЪНшВзЙП»Ҙ¶ҜөДІъЖ·РОМ¬Ј¬іцПЦБЛПсЙзҪ»НшВзХвСщөДІъЖ·ЎЈХыёц»ҘБӘНшІъЙъөДКэҫЭұ¬·ўКҪФціӨЈ¬ХвСщөДЗчКЖТІҫНөјЦВПсҫЦУтНшКұҙъТ»СщИҘВтУІјюөДҙжҙў№сТСҫӯёъІ»ЙПНшВзКұҙъКэҫЭФціӨөД·ўХ№БЛЎЈТтОӘВтУІјюөД№сЧУ»бЙжј°өҪСЎРНЎўІЙ№әЎўөҪ»хЎўЙПјЬХвСщТ»ёцәЬіӨөДБчіМЈ¬РиТӘЧцәЬСПҪчөДИЭБҝ№ж»®ЎЈ
ЎЎЎЎҫНФЪХвёцКұјдөгЙП Google МбіцБЛЛыГЗөД Google File System өДВЫОДЈ¬Н¬КұФЪјјКхЙзЗшАпГжіцПЦБЛөЪТ»ҙъҙҝИнјю¶ЁТеҙжҙўөД·ЦІјКҪОДјюПөНіІъЖ·ЎЈҙујТКмЦӘөДПсҙуКэҫЭБмУтөД HDFSЈ¬ТСҫӯұ»әмГұКХ№әөД CephFSЎўGlusterFSЈ¬»№УРөұКұГжПт HPC іЎҫ°өД LustreЎўBeeGFS ХвР©ІъЖ·¶јКЗФЪ 2005 ДкөҪ 2009 ДкХвСщТ»ёцәЬ¶МөДКұјдҙ°ҝЪДЪө®ЙъөДЎЈХвТІҫНТвО¶ЧЕХвР©ІъЖ·¶јУРТ»ёц№ІН¬өДКұҙъұіҫ°ТФј°ГжПтөұКұУІјю»·ҫіөДЙијЖЈ¬ұИИзЛөөұКұ»№Г»УРФЖөДҙжФЪЈ¬ЛщУРөДХвР©·ЦІјКҪОДјюПөНі¶јКЗГжПт»ъ·ҝАпөДОпАн»ъЙијЖөДЎЈ¶шөұКұөД»ъ·ҝ»·ҫіәНҪсМмЧоҙуөДЗшұрҫНКЗНшВз»·ҫіЈ¬өұКұ»ъ·ҝАпГжКЗТФ°ЩХЧНшҝЁОӘЦчөДЈ¬ИзҪс»ъ·ҝАпГж»щұҫ¶јКЗНтХЧНшҝЁБЛЈ¬ХвР©ёшОТГЗөДИнјюЙијЖәН IT »щҙЎјЬ№№өДЙијЖҙшАҙБЛәЬ¶аөДёДұдЎЈ
ЎЎЎЎөЪТ»ҙъИнјю¶ЁТеҙжҙўөДІъЖ·Пс HDFS әН CephFSЈ¬ТФј° AI БчРРТФәуөД Lustre ИФИ»ФЪұ»әܶ๫ЛҫФЪІ»Н¬·¶О§ДЪК№УГЎЈХвР©ІъЖ·ФЪ·ўХ№№эіМЦРГж¶ФөДРВөДМфХҪҫНКЗТЖ¶Ҝ»ҘБӘНшөДіцПЦЎЈ
ЎЎЎЎ3. ТЖ¶Ҝ»ҘБӘНшКұҙъ
ЎЎЎЎ2010 ДкЦ®әуөДК®ДкКұјдЈ¬ТЖ¶Ҝ»ҘБӘНшПаұИ Web2.0 ЧоҙуөДұд»ҜҫНКЗТФЗ°ИЛГЗЦ»ДЬЧшФЪөзДФЗ°К№УГНшВзІъЙъКэҫЭЈ¬¶шөҪБЛТЖ¶Ҝ»ҘБӘНшКұҙъЈ¬ГҝёцИЛГҝМмРСЧЕөДКұәт¶јҝЙТФК№УГКЦ»ъАҙІъЙъКэҫЭЈ¬ХвҫНТвО¶ЧЕХыёц»ҘБӘНшЙПКэҫЭөДФціӨЛЩ¶ИУЦҝмБЛТ»БҪёцКэБҝј¶ЎЈ
ЎЎЎЎөЪТ»ҙъГжПт»ъ·ҝЈ¬УГИнјюҙоҪЁ·ЦІјКҪҙжҙўәН·ЦІјКҪПөНіөД·Ҫ°ёФЪТЖ¶Ҝ»ҘБӘНшКұҙъТІУцөҪБЛМфХҪЈ¬ХвТІҫНИГ№«УРФЖУҰФЛ¶шЙъЎЈЧоФзөДПс AWS ҫНКЗФЪ 2006 Дк·ўІјБЛөЪТ»ёцІъЖ· S3Ј¬ФЪөұКұ¶ј»№Г»УРХыёц№«УРФЖөДМеПөЈ¬Г»УР EC2 ХвСщөДјЖЛг»·ҫіЈ¬Ц»УРТ»ёцҙжҙў·юОс S3ЎЈS3 ҫНКЗПлјт»ҜЦ®З°ИЛГЗЧФјәҙоҪЁ»ъ·ҝЈ¬ІЙ№әУІјюИ»әуНЁ№эИнјюИҘҙоҪЁ·ЦІјКҪПөНіХвёцёҙФУөД№эіМЎЈ¶ФПуҙжҙўФЪТЖ¶Ҝ»ҘБӘНшКұҙъУРБЛТ»ёц·ЗіЈҝмЛЩөД·ўХ№Ј¬ЛьөДө®ЙъКЗОӘБЛҪвҫцЦ®З°·ЦІјКҪОДјюПөНіөДТ»Р©ОКМвЈ¬ө«ТІөјЦВОюЙьБЛТ»Р©ДЬБҰЈ¬ХвёцОТГЗәуГж»бФЩХ№ҝӘҪІЎЈ
ЎЎЎЎ4. ФЖФӯЙъКұҙъ
ЎЎЎЎФЪТЖ¶Ҝ»ҘБӘНшЕоІӘ·ўХ№Ц®әуЈ¬ПЦФЪУЦУӯАҙБЛОпБӘНшөД·ўХ№Ј¬Хв¶ФҙжҙўөД№жДЈЎўТЧ№ЬАнРФәНА©Х№ДЬБҰөИёч·ҪГж¶јУРБЛТ»ёцИ«РВөДТӘЗуЎЈөұОТГЗ»Ш№Л№«УРФЖКұ»б·ўПЦИұЙЩТ»ёц·ЗіЈККәПФЖ»·ҫіөД·ЦІјКҪОДјюПөНіЈ¬ЦұҪУҪ«ЙПТ»КұҙъөД HDFSЎўCephFSЎўLustre ХвСщөДІъЖ··ЕөҪ№«УРФЖЙПУЦІ»ДЬМеПЦіцФЖөДУЕКЖЎЈ
ЎЎЎЎ02 ФЖКұҙъөДНҙөгУлМфХҪ
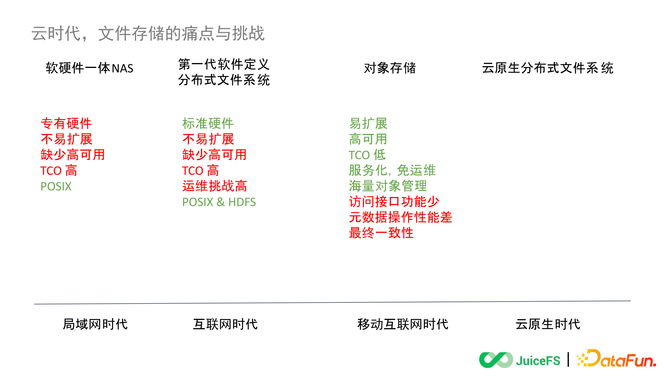
ЎЎЎЎ1. ёчҙъОДјюҙжҙўөДМШРФ
ЎЎЎЎПВНјХ№КҫБЛХвЛДёцКұҙъ¶ФУҰөДҙжҙўІъЖ·өДМШөгЈ¬ТФҪсМмөДКУҪЗ»ШҝҙЈ¬ЖдЦРәмЧЦКЗГҝҙъІъЖ·ЦРҙжФЪөДОКМвЈ¬ВМЧЦКЗЖдәГөДМШРФЎЈ
ЎЎЎЎ2. ИнУІјюТ»Ме NAS
ЎЎЎЎөЪТ»ҙъУІјюІъЖ·ФЪөұКұ¶јКЗІЙУГЧЁУРөДУІјюЈ¬А©ИЭІўІ»·ҪұгЈ¬ТтОӘјжИЭОКМвОЮ·ЁҪ«І»Н¬і§ЙМөДУІјю¶ФҪУөҪТ»ЖрК№УГЎЈІўЗТөұКұХвТ»ҙъИнУІТ»Ме NAS ТІИұЙЩёЯҝЙУГЈ¬ҙуІҝ·ЦІЙИЎЦчҙУ»ҘұёөД·ҪКҪЎЈ¶ФУЪҪсМмёьҙуёәФШЈ¬ёьҙу№жДЈөДПөНіЦчҙУ»ҘұёөДҝЙУГРФКЗІ»№»өДЎЈҙЛНвЈ¬»№ҙжФЪХыМеіЙұҫҪПёЯөДОКМвЈ¬ТтОӘРиТӘЧЁГЕөДУІјюЈ¬НшВз»·ҫіәНПаЖҘЕдөДО¬»ӨДЬБҰЎЈ
ЎЎЎЎөұКұХвТ»МЧИнУІТ»Ме NAS УРТ»ёцЧоҙуөДУЕКЖҫНКЗЛьКЗ POSIX јжИЭөДЈ¬С§П°іЙұҫәЬөНЈ¬¶ФУГ»§¶шСФҫНәНК№УГ Linux ұҫөШЕМөДМеСйКЗТ»СщөДЎЈХвҫНТвО¶ЧЕҝӘ·ўЙПІгУҰУГөДКұәтКЗ·ЗіЈјтөҘөДЈ¬ОЮВЫЦұҪУНЁ№эПөНіөчУГ»№КЗНЁ№эёчЦЦУпСФөДҝтјЬИҘҝӘ·ў¶јКЗ POSIX јжИЭөДЈ¬»бәЬ·ҪұгЎЈ
ЎЎЎЎ3. өЪТ»ҙъИнјю¶ЁТе·ЦІјКҪОДјюПөНі
ЎЎЎЎөҪБЛ»ҘБӘНшКұҙъЈ¬өЪТ»ҙъИнјю¶ЁТе·ЦІјКҪОДјюПөНі°ьАЁ HDFSЎўCephFS І»ФЩТААөУЪЧЁУРУІјюЈ¬¶јКЗУГұкЧјөД X86 »ъЖчҫНҝЙТФёг¶ЁБЛЎЈПаұИөЪТ»ҙъИнУІТ»МеөДА©Х№РФУРЛщМбёЯЈ¬ө«КЗәНәуАҙөДФЖҙжҙўПаұИ»№КЗІ»ТЧА©Х№Ј¬ДЬҝҙөҪПс CephFSЎўHDFS ТІ¶јУРТ»Р©өҘјҜИәөДЙППЮЈ¬ХвКЗФЪөұКұөДИЭБҝ№жДЈПВҪшРРЙијЖФмҫНөДҫЦПЮЎЈ
ЎЎЎЎҙЛНвИФИ»ИұЙЩёЯҝЙУГөДЙијЖЈ¬ҙуІҝ·ЦТАҫЙІЙУГЦчҙУ»ҘұёЈ¬ХвСщТ»АҙИФИ»ТӘОӘ»ъ·ҝ¶АБўөДІЙ№әУІјюЈ¬СРҫҝЎўО¬»Өҙу№жДЈөД·ЦІјКҪПөНіЈ¬ТтҙЛХыМеөД TCO »№КЗПа¶ФҪПёЯөДЎЈН¬КұПаұИЙПёцКұҙъ¶ФУЪФЛО¬өДМфХҪёьёЯБЛЈ¬ТтОӘІ»ҙжФЪі§ЙМөД·юОсБЛЈ¬РиТӘЧФјә№№ҪЁТ»МЧФЛО¬НЕ¶УЈ¬УөУРЧг№»өДФЛО¬ДЬБҰЈ¬ЙоИлХЖОХХвМЧҝӘФҙөДОДјюПөНіЎЈ
ЎЎЎЎәГФЪПс CephFSЎўLustre ХвР©ИФИ»КЗ POSIX јжИЭөДЈ¬¶ш HDFS ОӘБЛВъЧгҙуКэҫЭ Hadoop ЙъМ¬јЬ№№МбіцБЛТ»МЧРВөДҙжҙўҪУҝЪ HDFS APIЎЈИз№ыПкПёөДИҘ·ЦОцХвМЧ API ДЬ·ўПЦЛьЖдКөКЗ POSIX өДТ»ёцЧУјҜЈ¬јЩЙиЛө POSIX УР 200 ёцҪУҝЪЈ¬өҪ HDFS ҙуёЕҫНКЈПВТ»°лЎЈҙУОДјюПөНіөД№ҰДЬЙПАҙҝҙЈ¬ЛьКЗ¶ФТ»ёцНкХыөДОДјюПөНіЧцБЛТ»Р©ІГјфЈ¬ұИИз HDFS КЗ Append Only өДОДјюПөНіЈ¬ТІҫНКЗЦ»ДЬРҙРВКэҫЭЎўЧ·јУОДјюЈ¬¶шІ»ДЬ¶ФТСУРөДОДјюЧцёІёЗРҙЎЈХвКЗөұКұ HDFS ОӘБЛКөПЦёьҙу№жДЈКэҫЭөДҙжҙў¶шОюЙьөфөДТ»Іҝ·ЦОДјюПөНіУпТеЙПөДДЬБҰЎЈ
ЎЎЎЎ4. ¶ФПуҙжҙў
ЎЎЎЎ¶ФПуҙжҙўПаұИЦ®З°өДОДјюПөНіМбіцБЛИэёцәЛРДөДДЬБҰЈәТЧА©Х№ЎўёЯҝЙУГәНөНіЙұҫЎЈФЪХвИэёцәЛРДДЬБҰөД»щҙЎЙПМбіцТӘКөПЦ·юОс»ҜЈ¬јҙУГ»§І»ФЩРиТӘН¶ИлИОәОіЙұҫФЪҙоҪЁЎўФЛО¬ЎўА©ИЭХвР©КВЗйЙПБЛ;ҙЛНв»№МбіцЧчОӘТ»ёцФЖ·юОсТӘДЬЧ°ПВЧг№»әЈБҝөДКэҫЭЎЈ
ЎЎЎЎө«КЗУлҙЛН¬КұТІОюЙьБЛәЬ¶аОДјюПөНіФӯЙъЦ§іЦөДДЬБҰЎЈ
ЎЎЎЎөЪТ»КЗҪУҝЪЙЩБЛЎЈ¶ФПуҙжҙўМṩөД API НщНщКЗ HDFS өДТ»ёцЧУјҜЈ¬ПаұИ POSIX ДЬМṩөДДЬБҰҫНёьЙЩБЛЎЈЗ°ГжҫЩАэЛөјЩИз POSIX УР 200 ёц APIЈ¬ДЗөҪ HDFS ҝЙДЬЦ»УР 100 ёцБЛЈ¬өҪ S3 өДКұәтҙуёЕЦ»КЈ 20-30 ёцБЛЎЈ
ЎЎЎЎөЪ¶юКЗФӘКэҫЭІЩЧчРФДЬПВҪөБЛЎЈ¶ФПуҙжҙўұҫЙнІўІ»КЗОӘДЗР©РиТӘІЩЧчёҙФУФӘКэҫЭөДУҰУГЙијЖөДЈ¬ЧоҝӘКјЙијЖ¶ФПуҙжҙўЦ»КЗПлКөПЦКэҫЭЙПҙ«ФЩНЁ№э CDN ҪшРР·Ц·ўХвСщТ»ёцјтөҘөДТөОсДЈРНЎЈЧоіхS3АпөДҪУҝЪЖдКөЦ»УР PUTЎўGET әН DELETEЈ¬әуАҙУЦСЬЙъіцБЛ LISTЎўHEADЈ¬ө«ДЬҝҙөҪПс RENAMEЎўMV ХвР©ФЪОДјюПөНіАпәЬіЈјыөДІЩЧчЦБҪс¶ФПуҙжҙў¶јКЗІ»Ц§іЦөДЎЈ
ЎЎЎЎ5. ¶ФПуҙжҙўУлОДјюПөНіөДЗшұр
ЎЎЎЎҪУПВАҙОТГЗФЩХ№ҝӘҝҙТ»ПВ¶ФПуҙжҙўәНОДјюПөНіөДјёёцЗшұрЎЈ
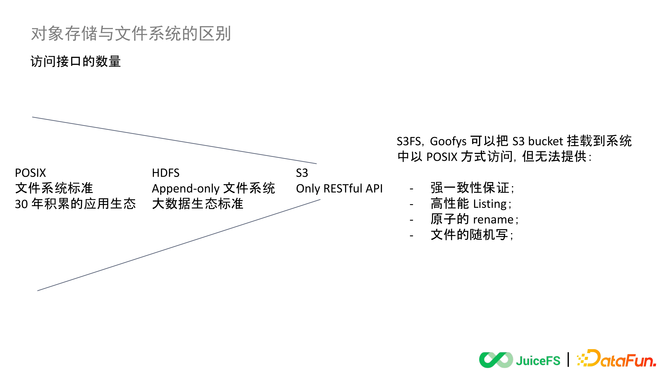
ЎЎЎЎ6. ·ГОКҪУҝЪөДКэБҝ
ЎЎЎЎPOSIX
ЎЎЎЎPOSIX РӯТйТСҫӯДЪЦГөҪ Linux ІЩЧчПөНіөДДЪәЛАпБЛЈ¬ҝЙТФНЁ№эПөНіөчУГЦұҪУ·ГОКТ»ёц POSIX јжИЭөДҙжҙўПөНіЈ¬OpenЎўWriteЎўRead ХвР©ұкЧјөДҪУҝЪТІТСҫӯДЪЦГөҪёчёцұаіМУпСФАпГжБЛЎЈФЪ POSIX Ц®ЙП№№ҪЁіцАҙөДУҰУГЙъМ¬ҙУ Linux ҝӘКјБчРРөҪПЦФЪЦБЙЩУРИэК®ДкөДКұјдБЛЈ¬ФЩ»щУЪ POSIX ұкЧјИҘЧцИ«РВөДОДјюПөНіЙПІгУҰУГІ»РиТӘЧцИОәОөДККЕдРЮёДЈ¬ТІІ»РиТӘМṩИОәОМШКвөД SDKЈ¬ёчёцУпСФ¶јКЗҝЙТФЦұҪУ·ГОКөДЎЈ
ЎЎЎЎHDFS
ЎЎЎЎHDFS КЗТ»ёцЦ»ДЬЧ·јУөДОДјюПөНіЎЈЛьМṩБЛТ»МЧЧФјәөД SDKЈ¬ұИИзЛөУРҙујТКмЦӘөДУГФЪ Hadoop АпГжөД Java SDKЎЈө«ХвёшЙПІгөДУҰУГҝӘ·ўҙшАҙБЛТ»Р©РВөДМфХҪЈ¬јҙФӯАҙөДіМРтКЗГ»°м·ЁЦұҪУК№УГ HDFS өДЈ¬ұШРлФЪёъОДјюПөНіҙтҪ»өАХвТ»ІгИҘЧцМж»»ЎЈМж»»өД№эіМЦРҫНТӘИҘҝјВЗҪУҝЪЦ®јдКЗІ»КЗТ»Т»¶ФУҰөДЈ¬І»¶ФУҰөДКұәтУГКІГҙ·ҪКҪДЬ№№ҪЁЖҪ»¬өДУіЙд№ШПөЎЈ
ЎЎЎЎHDFS ҫӯ№эК®јёДкөД·ўХ№ТСҫӯіЙОӘ Hadoop БмУтөДТ»ёцД¬ИПұкЧјЈ¬ө«ЖдКөФЪЖдЛыБмУтІўГ»УРөГөҪ№г·әөДУҰУГЈ¬ҫНКЗТтОӘ HDFS УРЧЕТ»МЧЧФјәөД API ұкЧјЎЈHDFS ҪсМмЧоіЙКмөД»№КЗУГФЪ Hadoop МеПөАпГжөД Java SDKЎЈ¶шЖдЛыөДПс CЎўC++ЎўPythonЎўGolang ХвР©УпСФөД SDK іЙКм¶И¶ј»№І»№»Ј¬°ьАЁНЁ№э FUSEЎўWebDAVЎўNFS ХвР©·ГОК HDFS өД·ҪКҪТІІ»КЗәЬіЙКмЈ¬ЛщТФЦБҪс HDFS ЦчТӘ»№Ц»НЈБфФЪ Hadoop МеПөДЪИҘК№УГЎЈ
ЎЎЎЎS3
ЎЎЎЎS3 ЧоҝӘКјКЗ»щУЪ HTTP РӯТйМṩБЛТ»МЧ RESTful APIЈ¬әГҙҰКЗёьјУөДұкЧјәНҝӘ·ЕЈ¬ө«КЗН¬КұТІТвО¶ЧЕЛьәНПЦУРөДУҰУГіМРтКЗНкИ«І»ДЬјжИЭөДЈ¬ГҝТ»ёцУҰУГ¶јРиТӘГжПтЛьЧц¶ФҪУККЕд»тХЯХл¶ФРФөДҝӘ·ўЎЈS3 ұҫЙнМṩБЛәЬ¶аУпСФөД SDK ·ҪұгҝӘ·ўХЯК№УГЈ¬ТІө®ЙъБЛТ»Р©өЪИэ·ҪПоДҝЈ¬ЖдЦРЧоЦшГыөДКЗ S3FS әН GoofysЎЈХвБҪёцПоДҝ¶јКЗЦ§іЦҪ« S3 өД Bucket №ТФШөҪПөНіАпЈ¬Пс·ГОКұҫөШЕМТ»Сщ¶БРҙКэҫЭЈ¬ПЦФЪёчёц№«УРФЖЙПТІУРМṩХл¶ФЧФјә¶ФПуҙжҙўөДТ»Р©АаЛЖ·Ҫ°ёЎЈ
ЎЎЎЎЛдИ»ХвР©ДЬ№»КөПЦ°С Bucket №ТФШөҪІЩЧчПөНіАпЈ¬ө«КЗОЮ·ЁМṩөДКЗКэҫЭЗҝТ»ЦВРФөДұЈЦӨЈ¬И»әуКЗёЯРФДЬөД ListingЈ¬ТФЗ°ФЪұҫөШЕМАпБРДҝВјКЗТ»ёцәЬЗбБҝөД¶ҜЧчЈ¬ө«КЗФЪ¶ФПуҙжҙўөД Bucket АпИҘБРДҝВјРФДЬҙъјЫКЗәЬёЯөДЎЈҙЛНвЈ¬¶ФПуҙжҙўТІ»№Г»УРЦ§іЦФӯЧУөД Rename әН¶ФОДјюҪшРРЛж»ъРҙЎЈPOSIX јжИЭөДОДјюПөНіАпКЗУР API Ц§іЦ¶ФОДјюөДЛж»ъРҙөДЈ¬ҙтҝӘТ»ёцОДјюИ»әу Seek Цё¶ЁөДЖ«ТЖБҝИҘёьРВЛьөДДЪИЭЎЈө«КЗФЪ¶ФПуҙжҙўЙПГжТӘПлКөПЦ¶ФКэҫЭ»тХЯЛө¶ФОДјюөДҫЦІҝҪшРРёьРВЈ¬ОЁТ»ДЬЧцөДҫНКЗПИҪ«ОДјюНкХыөДПВФШөҪұҫөШЈ¬ёьРВЖдЦРРиТӘРЮёДөДДЗТ»Іҝ·ЦКэҫЭЈ¬ФЩ°СХвёцОДјюНкХыөДЙПҙ«»Ш¶ФПуҙжҙўАпГжЎЈХыёцЛж»ъРҙөДІЩЧчҙъјЫКЗ·ЗіЈҙуөДЈ¬ОЮ·ЁЦ§іЦРиТӘЛж»ъРҙөДУҰУГЎЈ
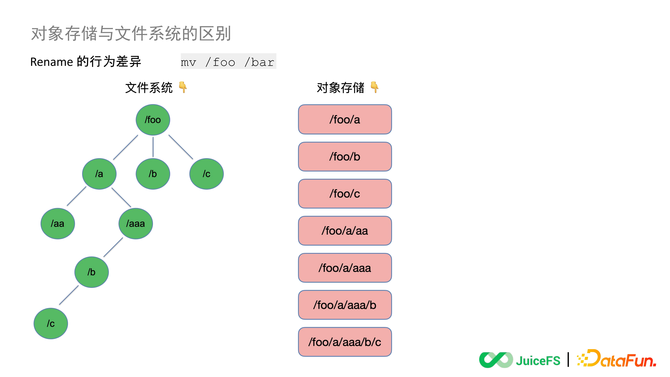
ЎЎЎЎ7. Rename өДРРОӘІоТм
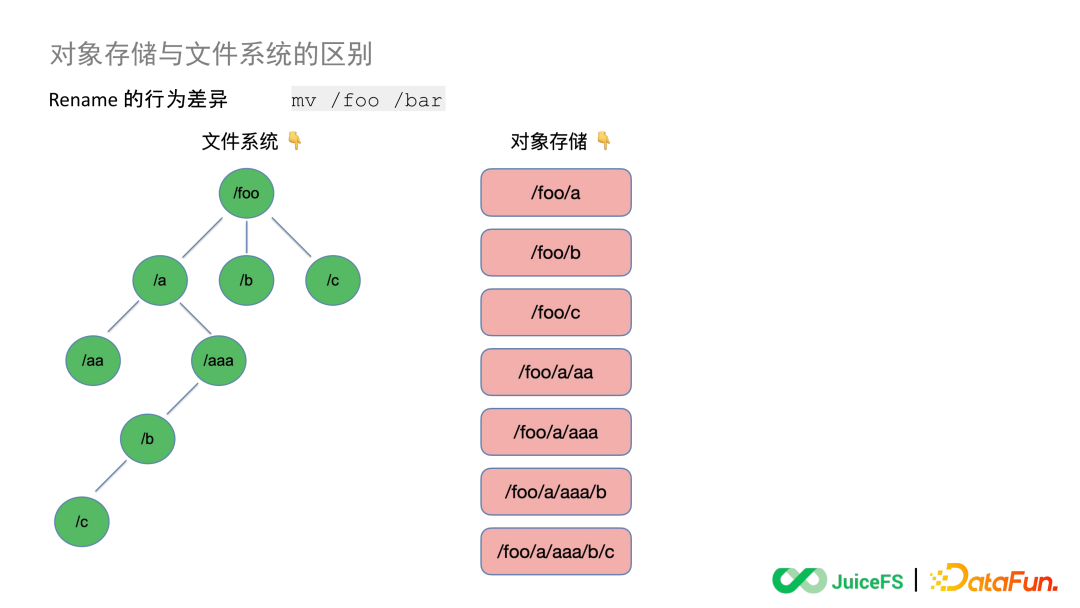
ЎЎЎЎПЦФЪ S3 ФӯЙъөД API АпИФИ»Г»УР RenameЈ¬№Щ·Ҫ SDK әНәЬ¶аөЪИэ·Ҫ№ӨҫЯөДИ·МṩБЛХвёц№ҰДЬЈ¬ұИИзНЁ№э Goofys »тХЯ S3FS °С Bucket №ТФШөҪ»ъЖчЙПФЩЦҙРР RenameЎЈө«ХвАпөД Rename әНОДјюПөНіФӯЙъөД Rename КЗУРІоұрөДЈ¬ХвАпҫЩТ»ёцАэЧУЎЈ
ЎЎЎЎЧуұЯДЈДвОДјюПөНіЈ¬ХвКЗТ»ёцКчРОҪб№№өДДҝВјКчЎЈ¶ш¶ФПуҙжҙўКЗІ»ҙжФЪФӯЙъөДКчРОҪб№№өДЈ¬Ль»бНЁ№эЙиЦГ¶ФПуөД Key Цө(¶ФПуГы)АҙДЈДвіцТ»ёцВ·ҫ¶Ј¬КөјКЙП¶ФПуҙжҙўАпГжөДКэҫЭҪб№№КЗұвЖҪөДЈ¬јҙУТұЯХвСщөДҪб№№ЎЈ
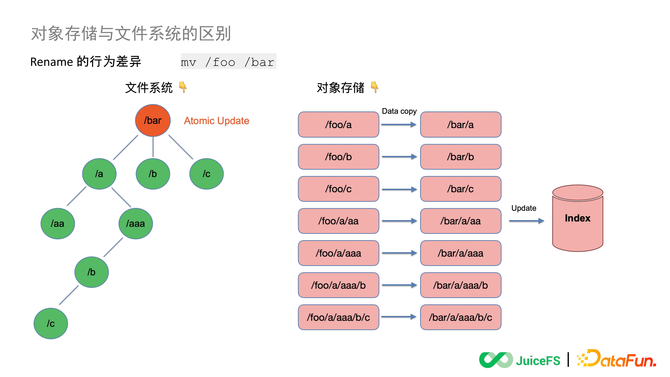
ЎЎЎЎИз№ыҙЛКұТӘЦҙРРТ»ёц Rename ІЩЧчЈ¬°С /foo ХвёцДҝВјГыёДіЙ /barЈ¬ТтОӘОДјюПөНіКЗКчРОөДКэҫЭҪб№№Ј¬ЛщТФЛьҫНДЬХТөҪХвёцДҝВјГы¶ФУҰөД Inode ИҘЦҙРРТ»ёцФӯЧУөДёьРВЈ¬°С foo Мж»»іЙ BarЎЈ
ЎЎЎЎТтОӘ¶ФПуҙжҙўөДКэҫЭҪб№№КЗұвЖҪөДЈ¬ЛщТФРиТӘФЪ¶ФПуҙжҙўАп¶ФХвёц Key өДЛчТэИҘЧцТ»ҙОЛСЛчЈ¬ХТөҪЛщУРТФ foo ОӘЗ°ЧәөД¶ФПуЈ¬ҝЙДЬКЗ 1 ёцТІҝЙДЬКЗ 100 НтёцЎЈЛСЛчіцАҙТФәуТӘҪ«ХвР©¶ФПуҪшРРТ»ҙО lO ҝҪұҙЈ¬УГРВөДГыЧЦЧчОӘ Key ЦөёҙЦЖТ»ұйЈ¬ёҙЦЖЦ®әуФЩёьРВПа№ШөДЛчТэРЕПўН¬КұЙҫөфҫЙөД¶ФПуЎЈ
ЎЎЎЎДЬҝҙөҪХвКЗТ»ёцұИҪПіӨөДІЩЧч№эіМЈ¬ТӘПИЛСЛч¶ФПуЈ¬И»әуҝҪұҙЈ¬ФЩёьРВЛчТэЈ¬Хыёц№эіМЖдКөКЗГ»УРКВОсИҘұЈЦӨөДЈ¬УРҝЙДЬ»біцПЦТ»ЦВРФОКМвЎЈДҝЗ°ҙуІҝ·ЦөД¶ФПуҙжҙў»бұЈЦӨЧоЦХТ»ЦВРФЈ¬Ц»УРЙЩКэөД¶ФПуҙжҙў»бФЪЧФјәФӯЙъөД API АпГжұЈЦӨЗҝТ»ЦВРФЈ¬ө«КЗФЪөЪИэ·Ҫ№ӨҫЯЧцөДПс Rename ХвСщөДСЬЙъ API АпИФИ»Ц»КЗұЈЦӨЧоЦХТ»ЦВРФЎЈ
ЎЎЎЎ8. ЧоЦХТ»ЦВРФ
ЎЎЎЎХвАпФЩНЁ№эТ»ёцАэЧУАҙҪвКНЧоЦХТ»ЦВРФТФј°ЛьҝЙДЬ¶ФУҰУГФміЙөДУ°ПмЎЈ
ЎЎЎЎХвАп»ӯБЛТ»ёұВю»ӯЈ¬ҪІБЛАПДМДМөДТ»Ц»ГЁЕЬөҪБЛКчЙПЈ¬ЛэПлЗлХвёцРЎЕуУС°пЛэҫИГЁЈ¬РЎЕуУСЛөГ»ОКМвЈ¬ОТ°пДг°СГЁДГ»ШАҙЎЈҙујТҝЙТФҝҙөҪЛыҫУИ»ҙУБнНвТ»ёц»ӯГжАп°СГЁёшИЎБЛіцАҙЈ¬АПДМДМәЬТЙ»уЈ¬ОӘКІГҙКчЙПәНРЎЕуУСКЦАпёчУРТ»Ц»ГЁ?РЎЕуУСЛөХвЦ»КЗТ»ёц SYNC өДОКМвЈ¬ДгФЩИҘ Check Т»ПВҫНәГБЛЈ¬АПДМДМФЩНщКчЙПҝҙөДКұәтКчЙПөДГЁТСҫӯІ»јыБЛЎЈХвАпЖдКөҫНМеПЦБЛЗ°ГжҪІөД Rename өД№эіМЈ¬јҙФЪТ»ёцәЬіӨөДБчіМАпКэҫЭГ»УРұЈіЦНкХыөДТ»ЦВРФЧҙМ¬ЎЈ
ЎЎЎЎ¶ФУҰөДГьБоФЪЧуұЯЈ¬КЧПИБРБЛТ»ПВХвёц Bucket өДДҝВјЈ¬·ўПЦУРТ»ёцОДјю cat.txtЈ¬Ҫ«Ль MV өҪРВөДДҝВјЈ¬»»НкДҝВјЦ®әуҝҙөҪФӯАҙөДХвёцДҝВјАпГж»№УРХвёцcat.txtЈ¬¶шРВөДДҝВјАпТІУРБЛТ»ёц cat.txtЈ¬ҙЛКұҝҙөҪБЛБҪЦ»ГЁЈ¬ХвҝҙЖрАҙҫНІ»ПсКЗ MV өДІЩЧчБЛЎЈө«ЖдКөХвКЗТ»ёц SYNC ЧҙМ¬өДОКМвЈ¬ҝЙДЬ№эБЛТ»»бФЩИҘФӯАҙөДҫЙДҝВјАпІйҝҙОДјюҫН»б·ўПЦ cat.txt І»јыБЛЈ¬ФЪІЩЧч№эіМЦРИҘ№ЫІмКұКэҫЭЧҙМ¬»№Г»УРТ»ЦВЈ¬ө«КЗПөНі»бұЈЦӨЧоЦХКЗТ»ЦВөДЧҙМ¬ЎЈ¶шИз№ыЙПІгөДУҰУГФЪКэҫЭЧҙМ¬І»Т»ЦВөДКұәтҫНТСҫӯИҘТААөЛьАҙҪшРРПВТ»ІҪІЩЧчөД»°Ј¬ДЗУҰУГҝЙДЬҫН»біцҙнБЛЎЈ
ЎЎЎЎХвАпҫЩБЛјёёцАэЧУАҙЛөГчЛдИ»ҪсМм¶ФПуҙжҙўКЗДЬ№»ёшОТГЗМṩУЕРгөДА©Х№РФЎўөНБ®өДіЙұҫәНұгҪЭөДК№УГ·ҪКҪЈ¬ө«КЗөұОТГЗРиТӘ¶ФКэҫЭҪшРРёьёҙФУөД·ЦОцЎўјЖЛгІЩЧчКұ¶ФПуҙжҙўИФИ»»бёшОТГЗҙшАҙТ»Р©І»·ҪұгөДөШ·ҪЈ¬ұИИзЛөҪУҝЪәЬЙЩЎўРиТӘХл¶ФРФөДҝӘ·ўЎўФӘКэҫЭөДРФДЬІоЎЈТФЗ°ФЪОДјюПөНіАпәЬЗбБҝөДІЩЧчЈ¬ФЪ¶ФПуҙжҙўАпҝЙДЬ»бұдөГәЬёҙФУ;ҙЛНв»№ҝЙДЬ»бТэИлТ»Р©Т»ЦВРФөДОКМвЈ¬¶ФКэҫЭҫ«И·РФТӘЗуәЬёЯөДіЎҫ°ҫНІ»ККәПБЛЎЈ
ЎЎЎЎ03 JuiceFS өДЙијЖХЬС§
ЎЎЎЎҙУИнУІТ»МеөҪөЪТ»ҙъИнјю¶ЁТеОДјюПөНіФЩөҪ S3 ёчУРёчөДУЕИұөгЈ¬ЛщТФҪсМмөұОТГЗФЪФЖөД»·ҫіАпГжИҘҝҙөДКұәт»б·ўҫхИұЙЩТ»ёц·ЗіЈНкЙЖЈ¬·ЗіЈККәПФЖ»·ҫіУЦДЬәЬәГөДЦ§іЦҙуКэҫЭЎўAI »№УРТ»Р©РВРЛөДәЈБҝКэҫЭҙҰАн»тХЯГЬјҜјЖЛгХвР©іЎҫ°өДОДјюПөНіІъЖ·Ј¬јИҝЙТФИГҝӘ·ўХЯ·ЗіЈИЭТЧөДК№УГУЦУРЧг№»өДДЬБҰИҘУҰ¶ФХвР©ТөОсЙПөДМфХҪЈ¬ХвҫНКЗОТГЗЙијЖ JuiceFS өДіхЦФЎЈ
ЎЎЎЎ1. JuiceFS өДЙијЖДҝұк
ЎЎЎЎ(1)¶аіЎҫ°Ј¬¶аО¬¶И
ЎЎЎЎЗ°Гж·ЦОцБЛөұЗ°КРГжЙПөДіЎҫ°Ј¬өұОТГЗПлИҘОӘФЖ»·ҫіЙијЖ JuiceFS ХвёцІъЖ·өДКұәтЈ¬ОТГЗҝӘКјҝјВЗЧФјәөДЙијЖДҝұкЈ¬ТӘұИҪПЗ°ГжХвР©ІъЖ·өДТ»Р©УЕБУКЖәНЛьГЗөДЙијЖЛјВ·Ј¬Н¬КұТІТӘёь¶аөД№ШЧўУГ»§ТөОсіЎҫ°өДРиЗуЎЈОДјюПөНіКЗФЪХыёц IT »щҙЎјЬ№№ЦР·ЗіЈөЧІгөДІъЖ·Ј¬К№УГЛьөДіЎҫ°»б·ЗіЈөД·бё»Ј¬ФЪІ»Н¬өДіЎҫ°Ап¶ФОДјюПөНіұҫЙнөД№жДЈЎўА©Х№РФЎўҝЙУГРФЎўРФДЬЎў№ІПнөД·ГОКДЬБҰТФј°іЙұҫЙхЦБ»№УРәЬ¶аО¬¶ИөДТӘЗу¶јКЗІ»Т»СщөДЈ¬ОТГЗТӘЧцөДКЗФЖ»·ҫіНЁУГРНІъЖ·Ј¬ҫНРиТӘФЪХвёцҫШХуЙПИҘЧцИЎЙбЎЈ
ЎЎЎЎ2. јЬ№№өДЙијЖСЎФс
ЎЎЎЎФЪ¶аіЎҫ°Ўў¶аО¬¶ИөДЗ°МбПВЧцјЬ№№ЙијЖКұУРјёёцәк№ЫөД·ҪПтКЗОТГЗ·ЗіЈјбіЦөДЈә
ЎЎЎЎНкИ«ОӘФЖ»·ҫіЙијЖ
ЎЎЎЎФӘКэҫЭУлКэҫЭ·ЦАл
ЎЎЎЎХвЦЦЙијЖ»бОӘОТГЗФЪ¶аіЎҫ°¶аО¬¶ИЙПИҘЧцИЎЙбөДКұәтҙшАҙёь¶аөДБй»оРФЎЈПс HDFS КЗФӘКэҫЭәНКэҫЭ·ЦАлөД·Ҫ°ёЈ¬¶ш CephFS ҫНёьПсКЗФӘКэҫЭәНКэҫЭТ»МеөД·Ҫ°ёЎЈ
ЎЎЎЎІејюКҪТэЗж
ЎЎЎЎОТГЗМбіц°С JuiceFS ЙијЖіЙТ»ЦЦІејюКҪөДТэЗжЈ¬ИГКэҫЭ№ЬАнЎўФӘКэҫЭ№ЬАн°ьАЁҝН»§¶Л¶јДЬМṩһЦЦІејюКҪөДДЬБҰЈ¬ИГУГ»§ҪбәПЧФјәөДіЎҫ°ИҘЧцІ»Н¬О¬¶ИЙПІејюөДСЎФсЈ¬АҙЖҙІеіцТ»ёцЧоККәПЧФЙнТөОсіЎҫ°РиЗуөДІъЖ·ЎЈ
ЎЎЎЎSimple is better
ЎЎЎЎОТГЗТ»ЦұјбіЦ Linux өДТ»ёцЧо»щұҫөДЙијЖХЬС§“Simple is better”Ј¬ТӘҫЎҝЙДЬөДұЈіЦјтөҘЈ¬Т»ёц»щҙЎЙиК©ІъЖ·Ц»УРЧг№»јтөҘІЕДЬЧцөДЧг№»ҪЎЧіЈ¬ІЕДЬёшУГ»§МṩһёцТЧО¬»ӨөДК№УГМеСйЎЈ
ЎЎЎЎ3. №ШјьДЬБҰ
ЎЎЎЎФЩПё»ҜТ»ІгөҪ JuiceFS ІъЖ·ЙијЖөД№ШјьДЬБҰЙПЈ¬ОТГЗМбіцФЪФЛО¬ЙПЧц·юОс»ҜЈ¬Пс S3 Т»СщК№УГЈ¬І»РиТӘУГ»§ЧФјәО¬»Ө;ДЬЦ§іЦ¶аФЖЈ¬¶ш·ЗХл¶ФДіТ»ёцФЖ»тХЯДіТ»ЦЦ»·ҫіЙијЖЈ¬ТӘФЪ№«УРФЖЎўЛҪУРФЖЎў»мәПФЖөД»·ҫіАп¶јДЬУГ;Ц§іЦөҜРФЙмЛхЈ¬І»РиТӘКЦ¶ҜА©ИЭЛхИЭ;ҫЎҝЙДЬЧцөҪёЯҝЙУГЎўёЯНМНВәНөНКұСУЎЈ
ЎЎЎЎЗ°ГжМбөҪ POSIX РӯТйТФј° HDFS әН S3 ёчЧФөДұкЧјЈ¬ЛдИ» POSIX КЗТ»ёц·ГОКҪУҝЪЙПөДЧоҙујҜЈ¬ө«ҫӯ№эХвР©ДкөД·ўХ№әуЈ¬ИзҪс Hadoop ЙъМ¬ЦРГжПт HDFS ҝӘ·ўөДЧйјю·ЗіЈЦ®¶аЈ¬S3 ҫӯ№эК®јёДкөД·ўХ№ГжПтЛь API ҝӘ·ўөДУҰУГТІ·ЗіЈ¶аЎЈХвИэёцКЗҪсМмКРГжЙПЧоБчРРөД·ГОКұкЧјЈ¬ТтҙЛЧоАнПлөДЗйҝцКЗФЪТ»ёцОДјюПөНіЙПДЬ№»¶ФНвКдіцИэЦЦІ»Н¬ұкЧјөД API өД·ГОКДЬБҰЈ¬ХвСщТСУРөДХвР©іМРтҫН¶јҝЙТФЦұҪУ¶ФҪУҪшАҙЈ¬РВөДУҰУГТІҝЙТФСЎФсёьККәПөД·ГОКРӯТйҪшРРҝӘ·ўЎЈ
ЎЎЎЎЗҝТ»ЦВРФКЗОДјюПөНіұШұёөДДЬБҰЈ¬ЧоЦХТ»ЦВРФКЗІ»ДЬұ»ҪУКЬөД;»№УРәЈБҝРЎОДјюөД№ЬАнЈ¬ХвКЗЙПТ»ҙъОДјюПөНіЖХұй¶јГ»УРҪвҫцөДОКМвЈ¬ТтОӘФЪЙПТ»ҙъөДКұјдөгЙПёщұҫІ»ҙжФЪәЈБҝРЎОДјюөДіЎҫ°Ј¬¶шҪсМмОТГЗҝҙөҪФЪ AI өДБмУтАпГжЈ¬№ЬАнәЈБҝРЎОДјюЦрҪҘұдОӘ»щҙЎРиЗуЎЈұИИзЛөФЪЧФ¶ҜјЭК»ЎўИЛБіК¶ұрЎўЙщОД·ЦОцХвР©іЎҫ°АпГжҙујТ¶јФЪГж¶ФЧЕК®јёТЪЈ¬КэК®ТЪЙхЦБЙП°ЩТЪөДОДјюЈ¬¶шУЦГ»УРТ»ёцОДјюПөНіДЬ№»УҰ¶ФХвСщөД№жДЈЈ¬ОТГЗЙијЖ JuiceFS ҫНТӘҪвҫцХвёцәЛРДОКМвЎЈәуГж»№°ьАЁУГНёГчөД»әҙжЧцјУЛЩЈ¬ҫЎБҝұЈіЦөНіЙұҫХвР©ТІ¶јФЪОТГЗөДЙијЖДҝұкАпЎЈ
ЎЎЎЎ4. JuiceFS өДјЬ№№ЙијЖ
ЎЎЎЎПЦФЪИГОТГЗАҙҝҙТ»ПВЧоЦХөДЙијЖЈ¬ЧуұЯКЗ High Level өДјЬ№№НјЈ¬УТұЯКЗКэҫЭҙжИЎөДҪб№№НјЎЈ
ЎЎЎЎ5. ХыМејЬ№№
ЎЎЎЎјЬ№№НјДЬМеПЦіцОТГЗІејюКҪөДЙијЖЈ¬ХвАпУРИэёцҙуөДРйПЯҝт·ЦұрұнКҫ·ЦІјКҪОДјюПөНіАпөДИэҙуЧйјюЈәЧуПВҪЗөДФӘКэҫЭТэЗжЈ¬УТПВҪЗөДКэҫЭТэЗжТФј°ЙП·ҪөД·ГОКҝН»§¶ЛЎЈФӘКэҫЭТэЗжЈ¬КэҫЭТэЗжәНҝН»§¶ЛИэёцЧйјю¶јКЗІејюКҪөДЙијЖЈ¬ҝӘ·ўХЯҝЙТФҪбәПҫЯМеУҰУГәНЧФјәКмПӨөДјјКхХ»ИҘЧцСЎФсЎЈ
ЎЎЎЎФЪФӘКэҫЭТэЗжЙПУГ»§ҝЙТФСЎФсКРГжЙПЧоБчРРөДҝӘФҙКэҫЭҝв°ьАЁ RedisЎўMySQLЎўPostgreSQLЎўTiKVЈ¬ЧоҪь»№Ц§іЦБЛөҘ»ъөД SQLiteЎўBadgerDB әН Kubernetes ЙПҙујТұИҪПКмПӨөД ETCDЈ¬»№°ьАЁОТГЗДҝЗ°ХэФЪЧФСРөДТ»ёцДЪҙжТэЗжЈ¬ЧЬ№ІТСҫӯЦ§іЦБЛ 9-10 ҝоІ»Н¬өДҙжҙўТэЗжДЬ№»ИҘ№ЬАн JuiceFS өДФӘКэҫЭЎЈХвСщЙијЖТ»КЗОӘБЛҪөөНС§П°іЙұҫәНК№УГГЕјчЈ¬¶юКЗҝЙТФ·ҪұгУГ»§ҪбәПҫЯМеіЎҫ°¶ФКэҫЭ№жДЈЎўРФДЬЎўіЦҫГРФЎў°ІИ«РФөДТӘЗуИҘЧцИЎЙбЎЈ
ЎЎЎЎКэҫЭТэЗжКЗУГАҙҙжИЎКэҫЭОДјюөДЈ¬ОТГЗјжИЭБЛКРіЎЙПЛщУРөД¶ФПуҙжҙў·юОсЎЈ»Ш№ЛЙПТ»ҙъөД·ЦІјКҪОДјюПөНіЈ¬HDFS АпУР DatanodeЈ¬CephFS АпУР RADOSЈ¬јёәхГҝТ»ёцОДјюПөНі¶јЧцБЛТ»јю№ІН¬өДКВЗйҫНКЗ°СҙуБҝөДВг»ъҪЪөгАпөДҙЕЕМНЁ№эТ»ёц·юОс№ЬАнәГЈ¬°ьАЁКэҫЭДЪИЭәНКэҫЭёұұҫЎЈөұОТГЗҝјВЗОӘФЖ»·ҫіЙијЖөДКұәтҫН·ўПЦ№«УРФЖЙПөД¶ФПуҙжҙўТСҫӯДЬ°СКэҫЭ№ЬАнЧцөД·ЗіЈНкГАБЛЈ¬ЛьУРЧг№»ЗҝөДА©Х№РФЈ¬Чг№»өНөДіЙұҫЈ¬Чг№»°ІИ«өДДЬБҰЎЈЛщТФОТГЗФЪЙијЖ JuiceFS өДКұәтҫНІ»ФЩЧФјәИҘЧцКэҫЭ№ЬАн¶шКЗНкИ«Ҫ»ёш¶ФПуҙжҙўАҙЧцЎЈОЮВЫКЗ№«УРФЖЛҪУРФЖ»№КЗТ»Р©ҝӘФҙПоДҝМṩөДЈ¬ОТГЗИПОӘЛьГЗ¶јКЗёЯҝЙУГЈ¬°ІИ«әНөНіЙұҫөДЎЈ
ЎЎЎЎЙП·ҪөДРйПЯҝтҙъұнБЛ JuiceFS өДҝН»§¶ЛЈ¬ЖдЦРЧоөЧІгХвёцКЗ JuiceFS ҝН»§¶ЛАпГжөДТ»ёц Core LibЈ¬ёәФрУлФӘКэҫЭТэЗжәНКэҫЭТэЗжНЁРЕЈ¬ІўГжПтУҰУГКдіцЛДЦЦІ»Н¬өД·ГОК·ҪКҪЈә
ЎЎЎЎFUSEЈә°Щ·ЦЦ®°ЩјжИЭ POSIXЈ¬НЁ№э LTP әН pjd-fstest ІвКФ
ЎЎЎЎJava SDKЈә·юОсУЪ Hadoop ЙъМ¬Ј¬НкИ«јжИЭ HDFS API
ЎЎЎЎCSI DriverЈәФЪ Kubernetes өД»·ҫіАпГжҝЙТФУГ CSI өД·ҪКҪ·ГОК
ЎЎЎЎS3 GatewayЈәКдіцТ»ёц S3 өД End point ИҘ¶ФҪУ S3 өД API
ЎЎЎЎ6. КэҫЭҙжҙў
ЎЎЎЎУТІаөДНјЛөГчБЛОТГЗКЗИзәОАыУГ¶ФПуҙжҙўЧцКэҫЭіЦҫГ»ҜөДЎЈАаЛЖ HDFSЈ¬Т»ёцОДјюНЁ№э JuiceFS РҙөҪ¶ФПуҙжҙўАпКұ»бұ»ЗРёоЈ¬Д¬ИПКЗГҝ 4M ОӘТ»ёцКэҫЭҝйҙжөҪ¶ФПуҙжҙўАпЎЈХвСщЗРёоөДәГҙҰКЗҝЙТФМбёЯ¶БРҙөДІў·ў¶ИЈ¬МбЙэРФДЬЈ¬ХвКЗФЪФӯАҙөД¶ФПуҙжҙўАпәЬДСЧцөҪөДЎЈКэҫЭЗРёоТІУРЦъУЪОТГЗКөПЦТ»ёц»ъЦЖЈ¬јҙРҙөҪ¶ФПуҙжҙўЦРөДЛщУРКэҫЭҝйЦ»РВФцІ»РЮёДЎЈөұРиТӘ¶ФКэҫЭЧцёІёЗРҙөДКұәтЈ¬»б°СёІёЗРҙөДДЪИЭЧчОӘТ»ёцРВөДКэҫЭҝйРҙөҪ¶ФПуҙжҙўАпІўН¬ІҪёьРВФӘКэҫЭТэЗжЈ¬ХвСщөД»°ҫНҝЙТФ¶БөҪРВКэҫЭө«КЗУЦІ»УГРЮёДҫЙКэҫЭҝйЎЈХвСщөДЙијЖјИҝЙТФЦ§іЦЛж»ъРҙУЦҝЙТФ№жұЬөф¶ФПуҙжҙўөДЧоЦХТ»ЦВРФОКМвЈ¬Н¬КұАыУГХвёц»ъЦЖ»№ҝЙТФОӘҝН»§¶ЛМṩϸБЈ¶ИөДұҫөШ»әҙжөДДЬБҰЎЈ
ЎЎЎЎ7. JuiceFS өДҝЙ№ЫІвРФ
ЎЎЎЎОТГЗЙијЖ JuiceFS өДКұәт»№УРТ»ёцәЬЦШТӘөДДҝұкҫНКЗМбЙэУГ»§МеСйЎЈХвАпЦёөДУГ»§јИ°ьАЁК№УГОДјюПөНіөДҝӘ·ўХЯУЦ°ьАЁО¬»ӨОДјюПөНіөДФЛО¬әН SRE Н¬С§ЎЈТӘЧцөҪәГУГәГО¬»ӨЈ¬ОТГЗҫНҝјВЗМṩФЪФЖФӯЙъЙијЖЦРҫӯіЈМбј°өДҝЙ№ЫІвРФЎЈТФНщОТГЗК№УГОДјюПөНіКұИПОӘПөНіКЗҝмКЗВэёьЖ«ПтУЪёРРФөДЕР¶ПЈ¬әЬДСҝҙөҪ·ЗіЈПкПёөДКэҫЭЎЈ
ЎЎЎЎ¶ш JuiceFS МṩБЛҝЙ№ЫІвРФөДДЬБҰЈ¬ҝЙТФФЪҝН»§¶ЛАпҙтҝӘТ»ёцПкПёөД accesslogЈ¬АпГж»бКдіцЙПІгУҰУГ·ГОКОДјюПөНіКұЛщУРІЩЧчөДПёҪЪЈ¬°ьАЁЛщУР¶ФФӘКэҫЭөДЗлЗуЈ¬ЛщУРКэҫЭ·ГОКЗлЗуөДПёҪЪТФј°ПыәДөДКұјдЎЈФЩНЁ№эТ»ёц№ӨҫЯҪ«ХвР©РЕПўҪшРР»гЧЬЈ¬ҫНҝЙТФҝҙөҪЙПІгУҰУГФЛРР№эіМЦРУлОДјюПөНіХвТ»ІгКЗИзәОҪ»»ҘөДЎЈөұФЩУцөҪОДјюПөНіВэКұЈ¬ҫНҝЙТФәЬИЭТЧөД·ЦОціцХвёцВэКЗКІГҙФӯТтФміЙөДЈ¬КЗТтОӘУРМ«¶аөДЛж»ъРҙЈ¬»№КЗТтОӘ¶аПЯіМІў·ўЦ®јдҙжФЪЧиИыЎЈХвАпОТГЗМṩБЛ CLI №ӨҫЯЈ¬ФЪОТГЗ№«УРФЖөДФЖ·юОсЙП»№МṩБЛТ»Р©»щУЪ GUI өДҝЙКУ»Ҝ№ӨҫЯИҘЧц№ЫІвЈ¬ПаРЕХвСщөД№ЫІвДЬБҰ¶ФУЪЙПІгУҰУГөДҝӘ·ўТФј°¶ФУЪОДјюПөНіұҫЙнөДФЛО¬¶јКЗәЬУР°пЦъөДЎЈ
ЎЎЎЎ04 JuiceFS өДК№УГіЎҫ°
ЎЎЎЎЧоәуАҙ·ЦПнТ»ПВ JuiceFS ЙзЗшЦРУГ»§ЧоіЈУҰУГөДТ»Р©іЎҫ°ЎЈ
ЎЎЎЎ1. Kubernetes
ЎЎЎЎФЪ Kubernetes АпТ»Р©УРЧҙМ¬өДУҰУГРиТӘТ»ёціЦҫГҫнЈ¬Хвёц PV өДСЎФсТ»ЦұКЗ Kubernetes ЙзЗшАпГжУГ»§ҫӯіЈМЦВЫөДОКМвЎЈТФЗ°ҙујТҝЙДЬ»бСЎФс CephFSЈ¬ө«КЗҙшАҙөДМфХҪҫНКЗФЛО¬Па¶ФёҙФУЈ¬JuiceFS ПЈНыёшҙујТМṩһёцёьТЧФЛО¬өДСЎПоЎЈ
ЎЎЎЎ2. AI
ЎЎЎЎТтОӘ JuiceFS МṩБЛ¶а·ГОКРӯТйөДЦ§іЦЈ¬ЛщТФФЪ AI іЎҫ°ЦРәЬіӨөД Pipeline ЙПөДёчёц»·ҪЪ¶јҝЙТФәЬ·ҪұгөДК№УГЎЈJuiceFS »№МṩБЛНёГчөД»әҙжјУЛЩДЬБҰЈ¬ҝЙТФәЬәГөДЦ§іЦКэҫЭЗеПҙЎўСөБ·ЎўНЖАнХвР©»·ҪЪЈ¬ТІЦ§іЦБЛПс Fluid ХвСщөД Kubernetes АпГж AI өч¶ИөДҝтјЬЎЈ
ЎЎЎЎ3. Big Data
ЎЎЎЎJuiceFS УРТ»ёцәЬЦШТӘөДДЬБҰҫНКЗәЈБҝОДјюөД№ЬАнДЬБҰЈ¬JuiceFS ҫНКЗОӘ№ЬАнКэК®ТЪОДјюөДіЎҫ°ИҘЧцЙијЖәНУЕ»ҜөДЎЈФЪҙуКэҫЭіЎҫ°ПВЈ¬ТтОӘЛьНкИ«јжИЭ HDFS APIЈ¬ЛщТФАПөДПөНіОЮВЫКЗКІГҙ·ўРР°ж¶јҝЙТФәЬЖҪ»¬өДЗЁТЖҪшАҙЎЈҙЛНвЈ¬ФЪ Hadoop МеПөНвөДәЬ¶аMPPКэҫЭҝвПс ClickHouseЎўElasticsearchЎўTDengine әН MatrixDB ЧчОӘРВөДКэҫЭІйСҜТэЗжЈ¬Д¬ИПЙијЖКЗОӘБЛЧ·ЗуёьёЯРФДЬөДРҙИлЈ¬РиТӘЕдұё SSD ХвСщөДҙжҙўҙЕЕМЎЈө«КЗҫӯ№эіӨКұјдөДК№УГәуЈ¬ФЪҙуКэҫЭБҝПВҫНДЬ·ўПЦХвР©КэҫЭКЗУРИИКэҫЭТІУРОВЎўАдКэҫЭөДЈ¬ОТГЗПЈНыДЬУГёьөНіЙұҫөДИҘҙжҙўОВЎўАдКэҫЭЎЈJuiceFS ҫНЦ§іЦјтөҘНёГчөДҙжҙўОВЎўАдКэҫЭЈ¬ЙПІгөДКэҫЭҝвТэЗж»щұҫІ»РиТӘЧцИОәОРЮёДЈ¬ҝЙТФЦұҪУНЁ№эЕдЦГОДјю¶ФҪУҪшАҙЎЈ
ЎЎЎЎ4. NAS Migration to Cloud
ЎЎЎЎЗ°Гжёь¶аМбөҪөДКЗФЪ»ҘБӘНшРРТөЦРУҰУГҪП¶аөДіЎҫ°Ј¬¶шәЬ¶аЖдЛыБмУтТФНщөДРРТөУҰУГ¶јКЗ»щУЪ NAS №№ҪЁөДЈ¬ОТГЗҝҙөҪөұЗ°өДЗчКЖКЗХвР©РРТө¶јФЪПтФЖ»·ҫіЗЁТЖЈ¬ҪиЦъФЖөҜРФөДДЬБҰЈ¬АыУГёьҙу№жДЈөД·ЦІјКҪ»·ҫіИҘНкіЙЛыГЗРиТӘөДЦоИзКэҫЭҙҰАнЎў·ВХжЎўјЖЛгХвР©іЎҫ°ЎЈХвАпҙжФЪТ»ёцМфХҪҫНКЗИзәО°СФӯПИ»ъ·ҝАпөД NAS ЗЁТЖөҪФЖЙПЎЈОЮВЫКЗЙзЗш»№КЗЙМТөөДҝН»§Ј¬JuiceFS ХвұЯ¶јЦ§іЦБЛҙУҙ«НіөД»ъ·ҝ»·ҫіЙПФЖХвСщТ»ёцЗЁТЖ NAS өД№эіМЈ¬ОТГЗТСҫӯҪУҙҘ№эөДУР»щТтІвРтЎўТ©ОпСРҫҝЎўТЈёРОАРЗЈ¬ЙхЦБПс EDA ·ВХжЎўі¬ЛгХвР©БмУтЈ¬ЛыГЗ¶јТСҫӯҪиЦъ JuiceFS КөПЦБЛҪ«»ъ·ҝЦРөД NAS әЬЖҪ»¬өДЙПФЖЎЈ
ЎЎЎЎОДХВДЪИЭҪц№©ФД¶БЈ¬І»№№іЙН¶ЧКҪЁТйЈ¬ЗлҪчЙч¶ФҙэЎЈН¶ЧКХЯҫЭҙЛІЩЧчЈ¬·зПХЧФөЈЎЈ

өЪК®ЛДҙъУўМШ¶ы® ҝбоЈ™ ҙҰАнЖч(ҙъәЕRaptor Lake S Refresh)ІЙУГБЛПИҪшөДIntel 7ЦЖіМ№ӨТХЎЈ

°ВО¬ФЖНш(AVC)НЖЧЬКэҫЭПФКҫЈ¬2024Дк1-9ФВГч»рҙ¶ҫЯПЯЙПБгКЫ¶о94.2ТЪФӘЈ¬Н¬ұИФцјУ3.1%Ј¬ЖдЦР¶¶ТфЗюөАұнПЦУЕТмЈ¬Н¬ұИУР14%өДХЗ·щЈ¬ҙ«НіөзЙМВФУРПВ»¬Ј¬Н¬ұИҪөөН2.3%ЎЈ

Ў°ТФЗ°¶јТӘИҘҙ°ҝЪ°мЈ¬Т»МЧБчіМПВАҙ¶јТӘ°лёцФВБЛЈ¬ПЦФЪ·Ҫұг¶аБЛ!ЎұҙтҝӘЎ°ЦШЗ칫»эҪрЎұОўРЕРЎіМРтЈ¬°ҙХХМбКҫБчіММбҪ»Па№ШІДБПЈ¬ҪцјёГлЦУЈ¬ЦШЗмКРГсФшДіөДХЛ»§ҫНҙтҪшБЛ21600ФӘЎЈ

»ӘЛ¶ProArtҙҙТХ27 Pro PA279CRVПФКҫЖчЈ¬ЖҫҪиЖдУЕРгөДРФДЬЕдЦГәНҫ«ЧјөДЙ«ІКіКПЦДЬБҰЈ¬ОӘДъөДҙҙЧч№ӨЧчҙшАҙКөЦКРФөД°пЦъЈ¬Л«К®Т»ЖЪјдөНЦБ2799ФӘЈ¬РФјЫұИәЬёЯЈ¬јтЦұКЗҙҙЧчХЯГЗөДКЧСЎЎЈ

9ФВ14ИХЈ¬2024И«Зт№ӨТө»ҘБӘНшҙу»бЎӘЎӘ№ӨТө»ҘБӘНшұкК¶ҪвОцЧЁМвВЫМіФЪЙтСфіЙ№ҰҫЩ°мЎЈ

·ө»ШЦчТі ©® №ШУЪОТГЗ ©® ДЪИЭБӘПө ©® БӘПөОТГЗ ©® ГвФрЙщГч ©® ФӯҙҙРВОЕ ©® ГЕ»§°ж
Copyright www.citnews.com.cn ЦРОДҝЖјјЧКС¶ 2009-2025 all rights reserved
№ШјьҙКЈәCITNews|CitnewsЦРОДҝЖјјЧКС¶|ЦРОДҝЖјјЧКС¶Нш|ҝЖјјЧКС¶Нш|ЦР№ъҝЖјјЧКС¶|ЦР№ъҝЖјјРВОЕНш|ЦР№ъҝЖјјЧКС¶Нш|ҝмҝЖјј|РВҝЖјј|ЦРОДҝЖјјКэВлН·МхәЕ|ЦРОДТЖ¶ҜРВГҪМе